さて、前回の理論編に続いて今回は実践編だ1。前回解説したVoVNetをKerasで実装したので、実際に走らせて遊んでみよう。
前回貼ったkerasコードを再掲する2: https://gist.github.com/woodyZootopia/25e7940bf98fe05a631038f88dcbb8a0
これはVoVNetをベースに、最後にDense(10)をつけて10-class classifierにしただけのとっても単純な分類機だ。
実験条件
cifar-10 (train=50000枚、validation=10000枚。32x32のRGB画像), minibatch=128, Google Colab GPU上で100 epochs訓練した。OptimizerはAdam。
こしあんさんの実験に条件を揃えるため標準的なデータ水増しも行った。詳しくはコードを読んでほしい。
測定対象
- VoVNet
- cifar-10の画像サイズは32x32であるが、VoVNetでは画像のサイズを半減する処理が6回ある。
- 最初のconvがstride=2なのと、5つのstageを終えるたびに
Maxpooling(3x3, stride=2)があるので
- 最初のconvがstride=2なのと、5つのstageを終えるたびに
- したがって、32→15→7→3→1→OUT!→OUT! となっちゃう
- なので、まず最初のconvのstride=1にして、さらにstage 5のあとのMaxPoolをなくして、2回strideをへらした
- 実装としては次のように変更する:
- cifar-10の画像サイズは32x32であるが、VoVNetでは画像のサイズを半減する処理が6回ある。
# stem stage
x = self.conv_bn_relu(x, 64, strides=1)
x = self.conv_bn_relu(x, 64, strides=1)
x = self.conv_bn_relu(x, 128, strides=1)
# x = MaxPooling2D((3, 3), 2)(x)
# OSA stage
for chan, chan_after_1x1_conv, rep in zip(self.channels, self.bottleneck, self.repetition):
x = MaxPooling2D((3, 3), 2)(x)
for _ in range(rep):
x = self.OSAModule(x, chan, chan_after_1x1_conv)
# x = MaxPooling2D((3, 3), 2)(x)
- DenseNet
- こしあんさんの記事に比較的軽量なDenseNetのベンチマークが乗っていたので、MaxValAccについては(学習を100epochs回すのが面倒だったので)それを流用した。訓練時間・推論時間については、Colabの環境変更などの可能性があったので、手元で実行して測定した。
- 以下、上記事の番号で呼び、Koshian-2〜Koshian-6とする。
- 下の表に詳細なスペックをまとめておく。
| k | ブロック | |
|---|---|---|
| Koshian-2 | 16 | 1, 2, 4, 3 |
| Koshian-3 | 32 | 1, 2, 4, 3 |
| Koshian-4 | 16 | 2, 4, 8, 5 |
| Koshian-5 | 16 | 3, 6, 12, 8 |
| Koshian-6 | 16 | 6, 12, 24, 16 |
結果
VoVNet-27-slim
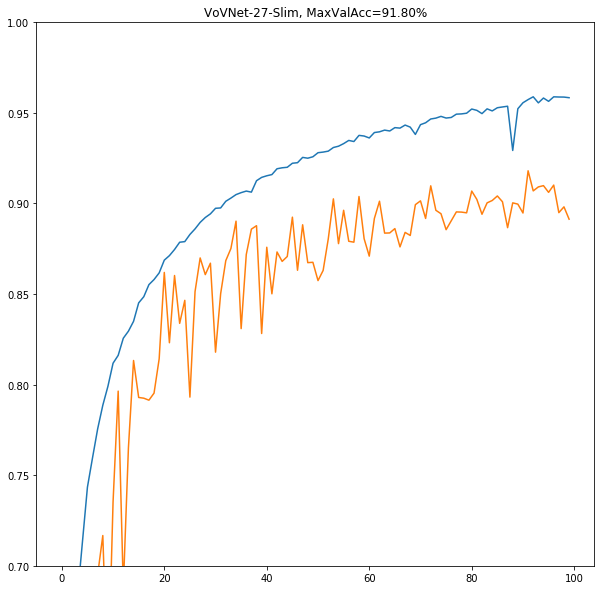
**いきなり90%超えの大台である。**試しにやったつもりがKoshian-6モデルと同等以上の性能が出てしまってびびる。詳しい比較は下に書く。
一番軽量なモデルでこの性能が叩き出されているなら、もっと性能を上げた2つにも期待が高まるところである。
VoVNet-39
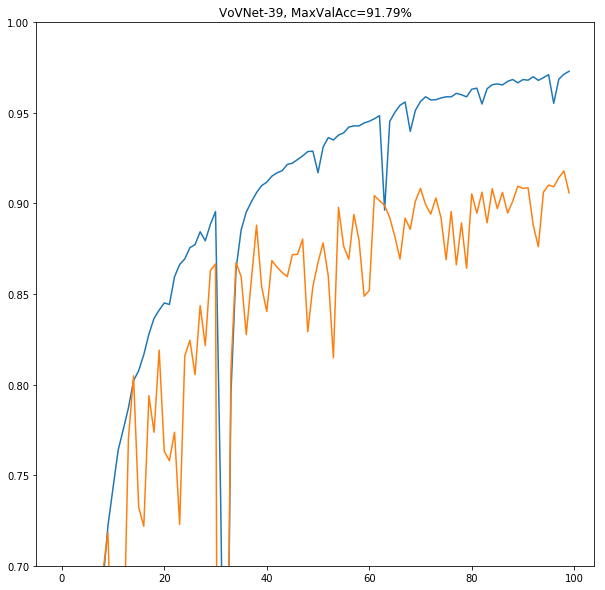
むしろ下がった。
Training accuracyは上昇しているが、validation accuracyはむしろ僅かながら下がったように思われる。追加の正則化などの対策をせずにcifar-10という軽いデータセットに対してモデルサイズを大きくしたのがまずかったのかもしれない。
あと、34epoch目あたりで一瞬予測がぶっ壊れてその後直っているのだがこれはなんだろう?読者の中にわかる人がいたらぜひ教えてほしい。
まだ収束しきっていないように思われたので、もう50epochsほど追加で回してみた。
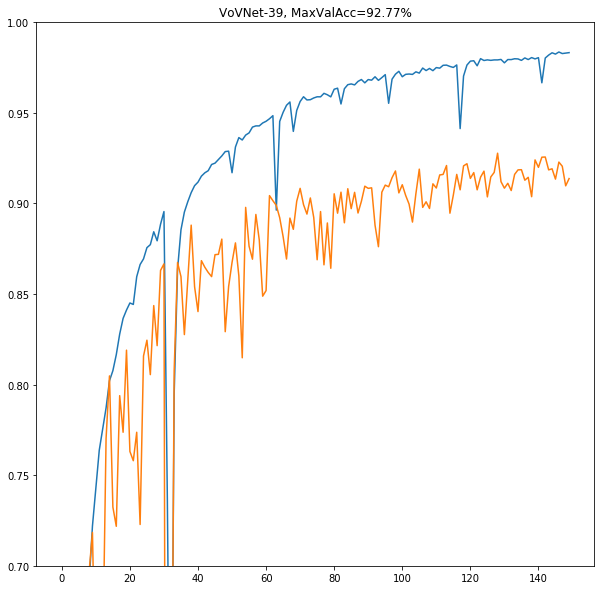
おもったとおり少し性能が向上した。極限まで性能を追求したいときはもう少し訓練を回したほうがいいかもしれない。
VoVNet-57に対しても同じような傾向が見られると予想され、同じように100epochs回してvalidation accuracyを計ってもあまり意味があると思えなかったので省略し、訓練時間や推論時間のみを計ることにした。
最終的には、挑むタスクの難しさ、リソースや計算時間と相談しながらどれを使うか選べばいいだろう。
表
というわけで、以上の結果(とDenseNetのベンチマーク)を下の表にまとめた。
各列の意味は以下の通り。
- MaxValAcc: 100epoch回したときのvalidation accuracyの最大値。
- 訓練時間 (secs/epoch):
fitを使った際の訓練時間を測定した。CPUがボトルネックとなるのをできるだけ回避するため - 訓練時間2(secs/epoch):
fit_generatorを使った際の訓練時間を測定した。実際に訓練したのはこちらなので、参考値として載せた- fit_generatorは画像を読み込み各種の水増しや変換を施すという作業をパイプライン化して並列に行ってくれる便利な仕組みだが、これによるCPU計算がボトルネックになり定数時間奪われている可能性がある。
- これらの訓練時間は1epoch目のみ何らかの理由3で少し長かったので、2epoch目以降の値を測定した
- 実推論時間(secs):
evaluate(batch_size=1)でvalidationデータ全体に対しての実行時間を測定した。Real-Time Inferenceの場合こちらになると思われる - バッチ推論時間(secs):同じく、
evaluate(batch_size=default=32)でのvalidationデータ全体に対しての実行時間を測定した。
| MaxValAcc | 訓練時間 | 訓練時間2 | 実推論時間 | バッチ推論時間 | Params(M) | |
|---|---|---|---|---|---|---|
| DenseNet(Koshian-2) | 83.8 | 18 | N/A | 67 | 4 | 0.255 |
| DenseNet(Koshian-3) | 85.9 | 21 | N/A | 70 | 3 | 0.505 |
| DenseNet(Koshian-4) | 87.4 | 37 | N/A | 92 | 5 | 0.600 |
| DenseNet(Koshian-5) | 89.0 | 58 | N/A | 116 | 7 | 1.10 |
| DenseNet(Koshian-6) | 90.9 | 140 | N/A | 187 | 16 | 3.31 |
| VoVNet-27-Slim | 91.80 | 32 | 35 | 54 | 3 | 2.68 |
| VoVNet-39 | 91.79→92.77 | 57 | 60 | 92 | 6 | 18.6 |
| VoVNet-57 | N/A | 70 | 73 | 125 | 8 | 30.5 |
考察
- MaxValAccは、VoVNetがどのKoshianモデルも超えていた。すごいね!
- VoVは全体に軽量で、例えばVoVNet-27/39とKoshian-6はある程度近い性能が出ているといえるが、明らかにKoshian-6のほうが諸々の計算コストは大きい。
- ただし、Koshianモデルのハイパーパラメータはこしあんさんが試しに決めたものであり、VoVのような論文に使われているハイパラと違って最適化されていないということには留意しなければならないだろう
- Koshian-5とVoV-39は、**訓練時間はだいたい同じだが、実推論時間に大きな差が出た。**Koshian-4とVoV-27も同じような傾向が見られている(それぞれ実推論スピードは116/92=1.26倍、92/54=1.70倍)
- バッチ推論時間はどれも十分速かったので10000枚程度だと違いが分かりづらいが、実推論時間には大きな差が出た
- VoVはパラメータ数が多いので、パラメータを更新しなければならない訓練のときには不利だが、コンボリューション層の数自体は少ないので、推論時には性能が良くなったものと思われる
- 例えば、VoV-39はその名前通り39層コンボリューションがあるが、Koshian-5は62層である。同じように27層であるVov-27に対し、Koshian-4は42層。
- ただし、特に推論時間については(おそらく同じコンピュータを使っている別の人のファイルアクセスなどによって)ある程度の幅が出た
まとめ
VoVNet(OSAアーキテクチャというべきか?)すごい。DenseNetより(特に推論が)圧倒的に速いし簡単に高精度がでちゃう。
まあ、論文向けにガリガリにチューニングされてるであろうVoVがCifarみたいな簡単な問題に対して性能を出すこと自体は大してすごくはないだろうが、**推論が高速なのは実運用上非常に便利そう。**GPU搭載した製品とかにこれからどんどん使われていく気がする。
最後に、たびたび引用していますが、この比較記事のためにはベースラインとしてこしあんさんのDenseNet実装と結果が不可欠でした。感謝です!
[追記]
こしあんさんから指摘をいただきました。
あ、実装されてアレですが多分あのDenseNetの記事、L2正則化とか相当いい加減だった記憶があるんで、CIFARで合わせるならDenseNetの論文にあわせたほうがいいと思います。
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) July 7, 2019
あとDAの掛け方も一般的なCIFARと僕の記事は違って、正直昔過ぎて自分が知らなくて適当にかけちゃったんですよね。自分の記事だったらPeleeNetのほうがまだマシかもしれません。 https://t.co/GFibj5yQwK
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) July 7, 2019
まとめると、
- 参考にした記事、及びこの記事では重み正則化をかけていない
- データ水増しももっといいやり方がありそう
- DenseNet論文では少なくとも重み正則化をやっており、**DenseNetで95%程度の性能を出している。**それと比較するべきでは?
ということですね。確かに、VoVの性能に関しては疑問の余地があるので、追加でベンチマークをしてみたいと思います。それでは〜