0. はじめに
普段は半導体業界で材料研究&開発に従事しています。
日頃からデータを扱う機会は多めですが、大規模なデータセットを解析するというよりは、自然科学的な文脈でモデルを作り、現象を説明したり、問題解決・意思決定を行うことをメインで行っています。
上記にあるように、プログラムや機械学習ゴリゴリ勢ではないので、本記事がQiita初投稿、Kaggle Advent Calendar 2021初参加となります。
ポエム感満載ですが、優しく指摘や感想など頂けたら嬉しいです。Twitterもやっているので仲良くなりたいです。
今回の記事は、私が参加したKaggleと社内コンペでの所感を記します。
Kaggleが気になっている方、これから始める方、始めて間も無い方々の参考になれば幸いです。
1. 初コンペはTop11%・Discussionで銅メダル
動機
最初にKaggleに興味を持ったのは2019年でした。その頃はタイタニック号の解法ブログを見て「ふーん、面白そうじゃん」くらいに思っていました。
その後は、時折思い出したようにKaggleや機械学習について調べていたら、2021年になっていました。
そして、趣味に近い形とはいえ「学習の成果が欲しいなあ」とぼんやりと思うようになり、社内的にもDXやらデータ解析の熱が上がり始めたのもあり「これはKaggleを始める機運…!」とコンペに参加する意思を固めました。
(2年前に登録だけはしていたみたいです)
Google Brain - Ventilator Pressure Prediction1(通称:圧力コンペ)への参加
せっかくだから業務に活かせるコンペがいいな…といった選定基準でCompetitionを眺めていました。
人工呼吸器の気道圧力を予測する、圧力コンペ(テーブルデータ)が目に留まりました。
とりあえず参加してデータを眺めることに……
したのですが、はじめは何をすればいいのかすら分かっていませんでした。
とりあえず、以下に取り組んだことを記します。
【取り組んだこと】
1.PythonではじめるKaggleスタートブックを読む。
Kaggleの概要とコンペの一連の流れは大体書いています。
ブログなどを参考にすると、読んだだけで分かった気になってしまいがちです。
この本を片手にタイタニックチュートリアルに取り組んだほうが理解が早かったです。
データの眺め方…EDA^2などから丁寧に説明されています。
2.OverviewのDescriptionとEvaluationを読む。
概要と評価基準について把握するということです。まずは読んでみましょう。
ただ、全文英語なのでGoogle翻訳に頼りまくりました。
最近ではDeepLといったサービスもあるので使ってみてください。
(正確性よりも把握のスピードを重視していました)
3.CodeをCopy&EditしてSubmit
ここが一番きつかった。
というのも、やってみると分かるのですが動かないことが多いです。
デバッグ、デバッグ、デバッグ……
コツ? これはもう、エラー内容を検索して地道に解決するしかありません。
(大体はPandasのVer.が合わなかったりといった環境起因)
そして、賢い人はCodeからBestScoreで検索して一番上にあるコードを使いたくなります!
これも罠。
初心者はシングルモデルを使ったコードかensembleしたコードか、区別がつきません。
大事なのはシングルモデルを使ったベースになるコードを探すことです。
コンペにもよりますが、今回はLightGBM、LSTM、Keras…などで検索をかけました。
Kaggleの特性上、公開されているSubmittionデータを使用することができるので、簡単に「他人の褌」に乗れちゃいます。
そして、しばしばensemble合戦が繰り広げられているみたいです。
Kaggleスタートブックにもありますが、初手はLightGBMでいいと思います。
LSTMはFold,Epoch数にもよりますが、自分は6時間かかってビビりました。
4.チームマージの誘いに乗る
KaggleはDisscusion以外では議論や情報交換はNGなので、チームを組むことによってやっと雑談……相談できたりします。
自分は運よくTwitterで同時期にKaggleを始めた人たちがチームマージを募集していたので乗っかりました。
足手まといになるんじゃないか?といった心配性なマインドは置いておいてもいいと思います。
というのも、真摯に取り組むと何かしら情報が手に入ります。それはバグであったり、Disscusionの情報であったり。
これらをSlacksなどで垂れ流すことは有益で、善い行いです。
自分はこちらのサイトを参考に、Party Parrotスタンプで騒いでいました。
5.実験計画を立てる&記録する
ベースとなるコードができたら、あとは特徴量エンジニアリングやチューニングなどの組み合わせでScoreの向上を図っていきます。意外とアイディアは出るものです。それらをすべて試せるか? それはNoです。
Submitは5回/日で、チームマージするとチーム内で5回/日になります。圧倒的に少なくなります。日割りでどれくらいの回数から効果的に実験できるかを悩むことから始めます。
そして、数カ月に及ぶ実験なので、何をしたかを簡単にでいいのでスプレッドシートに記録します。最初の項目は「記録日」「実験名」「LB」「コード名」「コメント」くらいから始めても良いと思います。使い勝手は後々よくしていけます。
あとは先人たちの知恵を借りましょう。特徴量エンジニアリングはこのスライドを見ると良いかと思います。
6.あとはひたすらDisccusion
チーム内での議論はもちろん、日々更新される珠玉のDisccusionに目を通しましょう。そして、自分の中にある疑問などを書いてみましょう。誰も笑いはしません。ちゃんと答えてくれたり、反応を返してくれます。疑問が生まれること自体が貴重なアイディアとなります。
とりあえずアイディアを話す、書き込む、といった行為を経ることで脳内を整理できるメリットもありますね。ラバーダッキング2という方法です。
最終順位は上位11%

チームメンバーがスコアを向上させると、ありがたいという気持ちと、超えてやるというライバル意識がちょうどいい感じに生じました。
黒魔術と呼ばれるensembleにも手を出し、一喜一憂していたこともありました。ただやはりシングルモデルでのスコア向上が一番うれしかったですね…。
最終的には同点メダル圏外という結果でしたが、はじめてにしては良い順位だったのではないでしょうか。
何が言いたいかというと、チームマージは初心者にこそオススメしたい、ということです。
今回チームを組んでくださった皆さんありがとうございました!
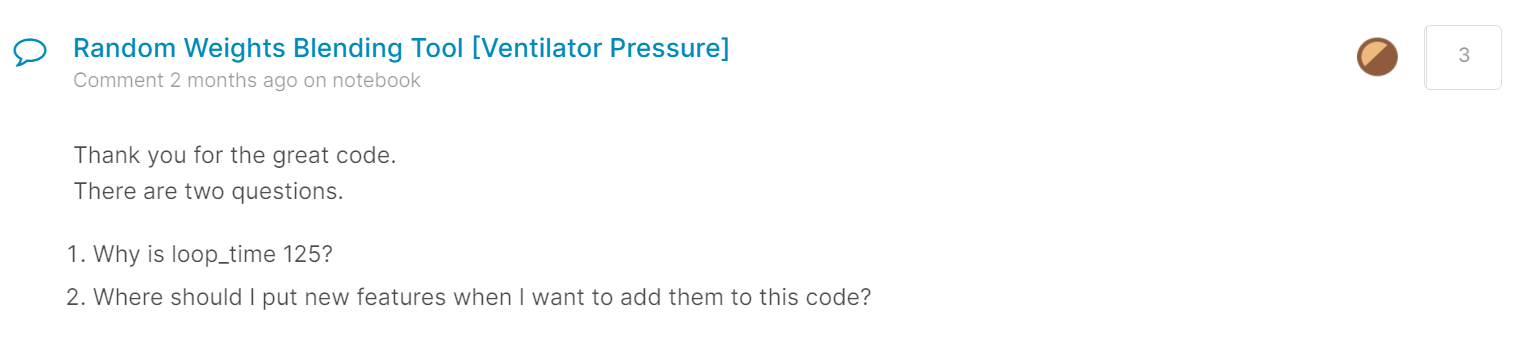
(この記事を書いていて気が付いたのですが、Disccusionに投稿した質問に銅メダルが付いていました)
2. 社内コンペは優秀賞
動機
圧力コンペに参加してから、しばらく燃え尽き症候群になっていました。
かといってすぐにKaggleに取り組む気力もなく……そんな時、社内のDX活動の一環としてデータ分析コンペ開催の告知がありました。
ある装置の寿命を予測する、時系列テーブルデータコンペ
社内データなので詳細を書けないのが残念ですが、ある装置についてるセンサーなどから装置の寿命を予測するコンペでした。
圧力コンペとは評価基準などが変わり、かつコードをイチから作るという、やりごたえのありそうな内容でした。
また、社内のKaggle情勢が分からないというのもあり、それらを探るという意味合いもありました。
予想以上に苦戦
正直言うと結構舐めていました。
社内で初めての分析コンペ開催……色々と整っていないだろうと。
しかし実際は、
・データ数が少ない
・手を入れてある
・特徴量を増やすと過学習
・パラメータで大きく変わる
・特徴のあるデータセット
……と色々とクセのある問題でした。
特に大変だったのが、クロスバリデーションのCVを小さくすることには成功したのですが、LBとは相関が無く特徴量を増やすと過学習となったことでした。
評価指標であるRMSE以外にMAEを用いてRMSE/MAEを求めることで、モデルの当てはまりを評価できるということがこのコンペを通しての発見でした。統計の知識も必要と感じました。
【取り組んだこと】
1.EDA
2.Submissionファイルの作成するためのコードを検証
3.初手LightGBM(まさかの、これがシングルモデルBest Score)
4.LSTMや回帰、スタッキングなどにチャレンジ
5.特徴量を増やすと過学習になったため特徴量エンジニアリング断念(もっといい方法あったかも)
5.あとはひたすらパラメータチューニングして実験
6.ensembleとシングルモデルのBest Scoreを最終提出(ensembleのデータで入賞)
LBでは3位、PBでは5位(優秀賞)
最終的にはShake downがあり5位という結果になりましたが、賞をもらえたのは励みとなりました。
Kaggleに挑戦していなかったら、この社内コンペには参加していなかったことを考えると、Kaggleに取り組んでいてよかったなと小並感3です。
3. ワナビー4Kagglerへ向けたTips
手を動かして、本気で取り組んで、スコアに一喜一憂する純粋な楽しみを味わいましょう。
【以下のことやれば、たぶん初心者Kaggler】5
・Kaggleへ登録してみよう。6
・Kaggleで開催中のコンペを探して参加する。初手はテーブルデータコンペがオススメだよ。
・KaggleノートブックとGoogle Colab7をベースに環境を整えてみよう。
・PythonではじめるKaggleスタートブックを読みながらタイタニックチュートリアルに取り組むんでみよう。
※タイタニックのスコアは気にしなくてよい。
・TwitterでKagglerをフォローする。みんなが参加していそうなコンペを探してみよう。(マストではないよ。)
・Python初学者のためのPandas100本ノックに取り組む。(Pandasはめっちゃ使うよ。)
・序盤に試すテーブルデータの特徴量エンジニアリングを読む。
・Kaggle本は辞書的な使い方で良いと思うよ。とはいえ通読はお勧めだよ。
・統計とかは後からでいいよ。でも、やったほうが良いよ。
・たいていネットにあるコードは、自分の環境だとうまく動かないよ。そんな時は寝たほうが良いよ。(本当に)
・意外とモデルのリファレンスマニュアルに使えるコードがあったりするよ。
注釈
-
問題を説明している過程で解決策を思いつくことがある。目的とするコードと、実際のコードの挙動を観察して、説明することにより、その違いが明白になる(Wikipediaより) ↩
-
小並感(こなみかん)とは、「小学生並みの感想」の略で、感想文の末尾に付してその文が稚拙であることを表す俗な言葉。(Weblio辞書より) ↩
-
ワナビー (wannabe) は、want to be(…になりたい)を短縮した英語の俗語で、何かに憧れ、それになりたがっている者のこと。上辺だけ対象になりきり本質を捉えていない者として、しばしば嘲笑的あるいは侮蔑的なニュアンスで使われる。(Wikipediaより) ↩
-
項目は順序良くやるのではなく、並行して進めることをおススメする。1つ1つが深いから。 ↩
-
作業興奮を誘発するため。 ↩
-
Jupyter Notebookライクな、ブラウザからPythonを記述、実行できるサービス。KaggleノートブックだとGPUの時間制限があるため、TPUなども使えるColabの併用をおススメしたい。状況次第ではPro契約も考えてもいいかも。 ↩