Information
2024/1/8:
pandas , Polars など18を超えるライブラリを統一記法で扱える統合データ処理ライブラリ Ibis の100 本ノックを作成しました。長期目線でとてもメリットのあるライブラリです。こちらも興味があればご覧下さい。
Ibis 100 本ノック
https://qiita.com/kunishou/items/e0244aa2194af8a1fee9
2023/2/12:
大規模データを高速に処理可能なデータ処理ライブラリ Polars の 100 本ノックを作成しました。こちらも興味があればご覧下さい。
Polars 100 本ノック
https://qiita.com/kunishou/items/1386d14a136f585e504e
はじめに
この度、PythonライブラリであるPandasを効率的に学ぶためのコンテンツとして 「Python初学者のためのPandas100本ノック」 を作成したので公開します。本コンテンツは、 Python3エンジニア 認定データ分析試験の出題内容にも沿っているため、この100本ノックを実施することで資格対策にもなります。 また、ノック終盤には、タイタニック号乗客の生存予測問題もあり、Kaggleなどの機械学習コンペへ参加するための練習にもなります。
作成の動機
- 最近、知り合いでPython・機械学習を始める人が増えてきており、そのような人たちに紹介できるコンテンツを自分でも作ってみたいと前々から思っていたため。Pandasが使えれば、機械学習まではできなくても、日常のデータ集計・分析業務にも活用できると考え、まずPandasの100本ノックを作ってみることにしました。
- 世の中に参考書は山ほどありますが、頭で理解するよりも、サクサクと手を動かして学べるものが初学者にとって最も上達するコンテンツだと考え、そのようなものを作りたいと考えました。
Pandas100本ノックの概要
- Jupyter Notebook上のセルに記載された、Pandasに関する設問100問を解いていきます。
- 通常版と、問題のランダム表示版の2つが同封されています。
- セクションは、基礎(1-13)、抽出(14-32)、加工(33-58)、マージと連結(59-65)、統計(66-79)、ラベリング(80-81)、Pandasプロット(82-89)、タイタニック号乗客の生存予測(90-100)の8つに分かれています。
以下に概要の動画を載せておきます。
問題内容
| No. | 分類 | 問題 |
|---|---|---|
| 1 | 基礎 | dfに読み込んだデータの最初の5行を表示 |
| 2 | 基礎 | dfに読み込んだデータの最後の5行を表示 |
| 3 | 基礎 | dfのDataFrameサイズを確認 |
| 4 | 基礎 | inputフォルダ内のdata1.csvファイルを読み込みdf2に格納、最初の5行を表示 |
| 5 | 基礎 | dfのfareの列で昇順に並び替えて表示 |
| 6 | 基礎 | df_copyにdfをコピーして、最初の5行を表示 |
| 7 | 基礎 | ① dfの各列のデータ型を確認 ② dfのcabinの列のデータ型を確認 |
| 8 | 基礎 | ① dfのpclassの列のデータ型をdtypeで確認 ② 数値型から文字型に変換し、データ型をdtypeで確認 |
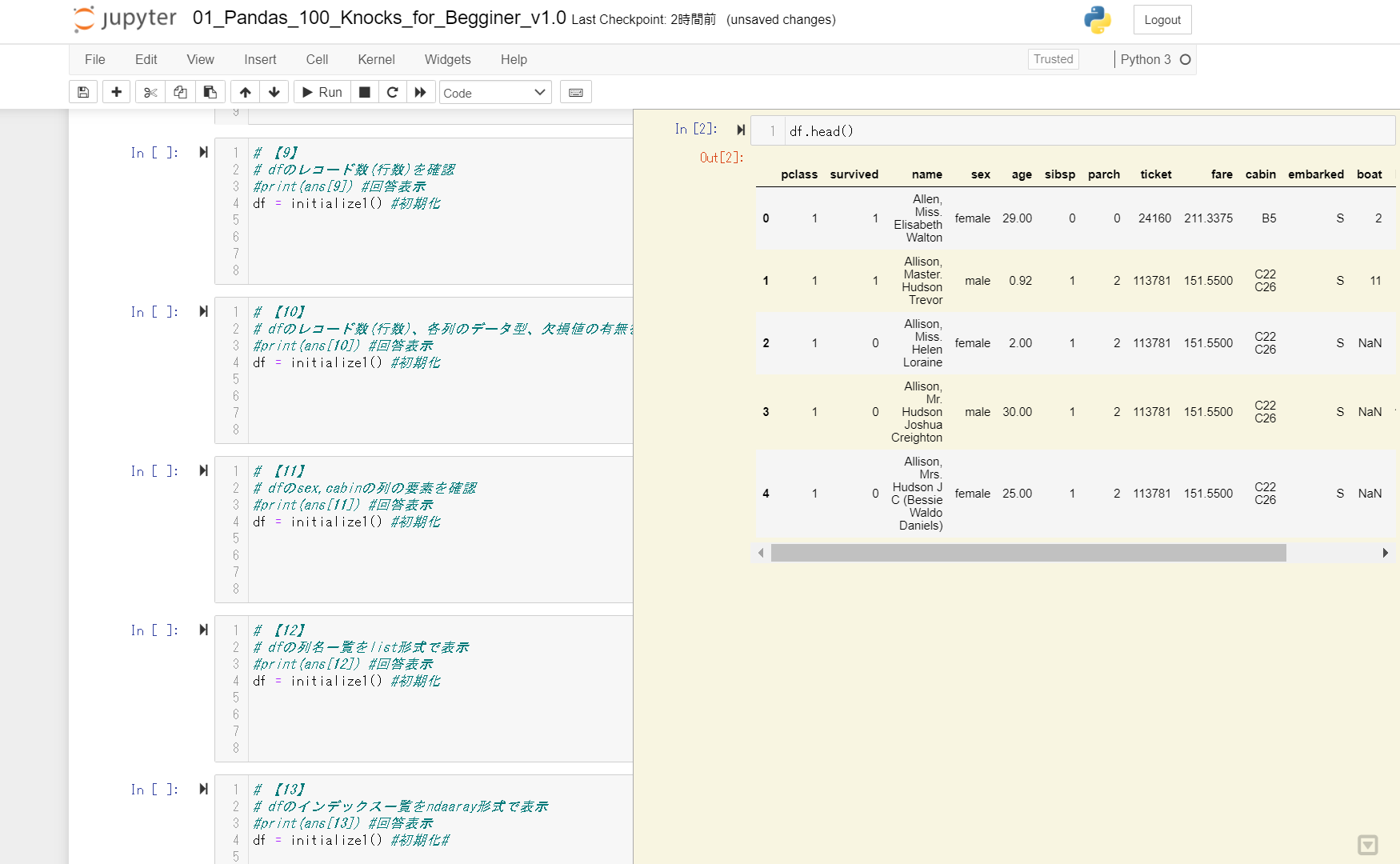
| 9 | 基礎 | dfのレコード数(行数)を確認 |
| 10 | 基礎 | dfのレコード数(行数)、各列のデータ型、欠損値の有無を確認 |
| 11 | 基礎 | dfのsex,cabinの列の要素を確認 |
| 12 | 基礎 | dfの列名一覧をlist形式で表示 |
| 13 | 基礎 | dfのインデックス一覧をndarray形式で表示 |
| 14 | 抽出 | dfのnameの列のみ表示 |
| 15 | 抽出 | dfのnameとsexの列のみ表示 |
| 16 | 抽出 | dfのindex(行)の4行目までを表示 |
| 17 | 抽出 | dfのindex(行)の4行目から10行目までを表示 |
| 18 | 抽出 | locを使ってdf全体を表示 |
| 19 | 抽出 | locを使ってdfのfare列をすべて表示 |
| 20 | 抽出 | locを使ってdfのfare列の10行目まで表示 |
| 21 | 抽出 | locを使ってdfのnameとticketの列をすべて表示 |
| 22 | 抽出 | locを使ってdfのnameからcabinまでの列をすべて表示 |
| 23 | 抽出 | ilocを使ってdfのage列を5行目まで表示 |
| 24 | 抽出 | dfのname,age,sexの列のみ抽出しdf2に格納 その後outputフォルダにcsvファイルで出力 |
| 25 | 抽出 | dfのage列の値が30以上のデータのみ抽出 |
| 26 | 抽出 | dfのsex列がfemaleのデータのみ抽出 |
| 27 | 抽出 | dfのsex列がfemaleでかつageが40以上のデータのみ抽出 |
| 28 | 抽出 | queryを用いてdfのsex列がfemaleでかつageが40以上のデータのみ抽出 |
| 29 | 抽出 | dfのname列に文字列「Mrs」が含まれるデータを表示 |
| 30 | 抽出 | dfの中で文字型の列のみを表示 |
| 31 | 抽出 | dfの各列のユニークな要素数のカウント |
| 32 | 抽出 | dfのembarked列の要素と出現回数の確認 |
| 33 | 加工 | dfのindex名が「3」のage列を30から40に変更 |
| 34 | 加工 | dfのsex列にてmale→0、femlae→1に変更し、先頭の5行を表示 |
| 35 | 加工 | dfのfare列に100を足して、先頭の5行を表示 |
| 36 | 加工 | dfのfare列を2を掛けて、先頭の5行を表示 |
| 37 | 加工 | dfのfare列を小数点以下で丸める |
| 38 | 加工 | dfに列名「test」で値がすべて1のカラムを追加し、先頭の5行を表示 |
| 39 | 加工 | dfにcabinとembarkedの列を「_」で結合した列を追加(列名は「test」)し、先頭の5行を表示 |
| 40 | 加工 | dfにageとembarkedの列を「_」で結合した列を追加(列名は「test」)し、先頭の5行を表示 |
| 41 | 加工 | dfからbodyの列を削除し、最初の5行を表示 |
| 42 | 加工 | dfからインデックス名「3」の行を削除し、最初の5行を表示 |
| 43 | 加工 | df2の列名を'name', 'class', 'Biology', 'Physics', 'Chemistry'に変更 df2の最初の5行を表示 |
| 44 | 加工 | df2の列名を'English'を'Biology'に変更 df2の最初の5行を表示 |
| 45 | 加工 | df2のインデックス名「1」を「10」に変更 df2の最初の5行を表示 |
| 46 | 加工 | dfのすべての列の欠損値数を確認 |
| 47 | 加工 | dfのageの列の欠損値に30を代入 その後、ageの欠損値数を確認 |
| 48 | 加工 | dfでひとつでも欠損値がある行を削除 その後、dfの欠損値数を確認 |
| 49 | 加工 | dfのsurvivedの列をarray形式(配列)で表示 |
| 50 | 加工 | dfの行をシャッフルして表示 |
| 51 | 加工 | dfの行をシャッフルし、インデックスを振り直して表示 |
| 52 | 加工 | ①df2の重複行数をカウント ②df2の重複行を削除し表示 |
| 53 | 加工 | dfのnameの列をすべて大文字に変換し表示 |
| 54 | 加工 | dfのnameの列をすべて小文字に変換し表示 |
| 55 | 加工 | dfのsex列に含まれる「female」という単語を 「Python」に置換 |
| 56 | 加工 | dfのname列1行目の「Allen, Miss. Elisabeth Walton」の 「Elisabeth」を消去(import reが必要) |
| 57 | 加工 | df5の都道府県列と市区町村列を空白がないように 「_」で結合(新規列名は「test2」)し、先頭5行を表示 |
| 58 | 加工 | df2の行と列を入れ替えて表示 |
| 59 | マージと連結 | df2にdf3を左結合し、df2に格納 |
| 60 | マージと連結 | df2にdf3を右結合し、df2に格納 |
| 61 | マージと連結 | df2にdf3を内部結合し、df2に格納 |
| 62 | マージと連結 | df2にdf3を外部結合し、df2に格納 |
| 63 | マージと連結 | df2とdf4を列方向に連結し、df2に格納 |
| 64 | マージと連結 | df2とdf4を列方向に連結し重複している name列の片方を削除し、df2に格納 |
| 65 | マージと連結 | df2とdf2を行方向に連結し重複しているname列の片方を削除し、df2に格納 |
| 66 | 統計 | dfのage列の平均値を確認 |
| 67 | 統計 | dfのage列の中央値を確認 |
| 68 | 統計 | ①df2の生徒ごとの合計点(行方向の合計) ②df2の科目ごとの点数の総和(列方向の合計) |
| 69 | 統計 | df2のEnglishで得点の最大値 |
| 70 | 統計 | df2のEnglishで得点の最小値 |
| 71 | 統計 | df2においてclassでグルーピングし、クラスごとの科目の最大値、最小値、平均値を求める(name列は削除しておく) |
| 72 | 統計 | dfの基本統計量を確認(describe) |
| 73 | 統計 | dfの各列間の(Pearson)相関係数を確認 |
| 74 | 統計 | scikit-learnを用いてdf2のEnglish、Mathmatics、Historyを標準化する |
| 75 | 統計 | scikit-learnを用いてdf2のEnglish列を標準化する |
| 76 | 統計 | scikit-learnを用いてdf2のEnglish、Mathmatics、History列をMin-Maxスケーリングする |
| 77 | 統計 | dfのfare列の最大値、最小値の行名を取得 |
| 78 | 統計 | dfのfare列の0、25、50、75、100パーセンタイルを取得 |
| 79 | 統計 | ①dfのage列の最頻値を取得 ②value_counts()にてage列の要素数を確認し、①の結果の妥当性を確認 |
| 80 | ラベリング | dfのsex列をラベルエンコーディングし、dfの先頭5行を表示 |
| 81 | ラベリング | dfのsex列をOne-hotエンコーディングし、dfの先頭5行を表示 |
| 82 | Pandasプロット | dfのすべての数値列のヒストグラムを表示 |
| 83 | Pandasプロット | dfのage列をヒストグラムで表示 |
| 84 | Pandasプロット | df2のnameごとの3科目合計得点を棒グラフで表示 |
| 85 | Pandasプロット | df2のname列の要素ごとの3科目を棒グラフで並べて表示 |
| 86 | Pandasプロット | df2のname列の要素ごとの3科目を積み上げ棒グラフで表示 |
| 87 | Pandasプロット | dfの各列間の散布図を表示 |
| 88 | Pandasプロット | dfのage列とfare列で散布図を作成 |
| 89 | Pandasプロット | 【88】で描画したグラフに「age-fare scatter」という グラフタイトルをつける |
| 90 | タイタニック号の生存者予測 | df_copyのsexとembarked列をラベルエンコーディング |
| 91 | タイタニック号の生存者予測 | df_copyの欠損値を確認 |
| 92 | タイタニック号の生存者予測 | df_copyのage、fare列の欠損値を各列の平均値で補完 |
| 93 | タイタニック号の生存者予測 | df_copyの中で機械学習で使用しない不要な行を削除 |
| 94 | タイタニック号の生存者予測 | ①df_copyのpclass、age、sex、fare、embarkedの列を抽出し、ndarray形式に変換 ②df_copyのsurvivedの列を抽出し、ndarray形式に変換 |
| 95 | タイタニック号の生存者予測 | 【94】で作成したfeatrues、targetを学習データとテストデータに分割 |
| 96 | タイタニック号の生存者予測 | 学習データ(features、target)を用いランダムフォレストにて学習を実行 |
| 97 | タイタニック号の生存者予測 | test_Xデータの乗客の生存を予測 |
| 98 | タイタニック号の生存者予測 | 予測結果がtest_y(生存有無の答え)とどれぐらい 整合していたかを確認(評価指標はaccuracy) |
| 99 | タイタニック号の生存者予測 | 学習における各列(特徴量)の重要度を表示 |
| 100 | タイタニック号の生存者予測 | test_Xの予測結果をcsvでoutputフォルダに出力(ファイル名は「submission.csv」) |
利用方法
※Pythonをまだインストールしていない方は、以下の記事を参考に、まずAnacondaを自身のPCにインストールして下さい。問題内ではPandas以外にも、Scikit-learnなどのライブラリも使用します。
5分で簡単!AnacondaでPython3をインストール(Windows/Mac編)
なお、作者のpandasバージョンは1.1.0です。下位バージョンにて実行した場合、一部エラーが出る設問があることが報告されています(設問31の「nunique()」等)。
- GitHubよりZIPフォルダをダウンロードした後に、自身のPCのローカル領域に展開する。
- 「notebook」フォルダに格納されているipynbファイルをJupyter Notebookで開く(まずは「01_Pandas_100_Knocks_for_Begginer_v1.0.x.ipynb」を開いてみて下さい)。
- ipynbファイルを開いた後に、先頭のセルを実行すると回答ファイル、問題で使用するデータセットが読み込まれます。使用するデータセットは、タイタニック号の乗客データ等になっています。
- 各設問のセル内に設問に対するコードを入力していきます。
- 答えが分からない場合は、設問セル内の「#print(ans[])」という記述から「#」を消して実行することで、回答例が表示されます。
- 100本ノック終了後に、各セルの出力結果をオールクリアしたい場合は、ツールバーの「Kernel」→「Restart & Clear Output」を実行します。
- 「01_Pandas_100_Knocks_for_Begginer(all_answer_displayed)_v1.0.x」ではすべての回答と出力結果を最初から表示しています。回答や出力結果をまとめて確認したいときにご活用下さい。Pandasを一度も触ったことのない方はまずこちらでメソッドを暗記するような勉強方法でも良いと思います。
ディレクトリ構成
pandas_100_knocks_v1.0.x
├ notebook/ … 4つのipynbファイルが格納
├ input/ … 100問分の回答ファイル、問題で使用するデータセットが格納
└ output/ … 問題でファイル出力する際にここに格納
※ZIPファイルから展開した後に、このディレクトリ構成は変えないで下さい(上手く動作しなくなります)。
このコンテンツの目指すところ
願わくばPython初学者の方がレベル3まで到達できることを意識し、問題を設定しました(3回解けばレベル2までは到達できると思います。)。
-
レベル1
Python・Pandasで基本的なデータ集計・分析ができるようになる(業務においてExcel、Accessの代替え手法として、Pythonでデータ集計・分析ができる)
(補足) Excel、AccessではなくPythonでデータ集計・分析を行う必要性ですが、Excelは表示できるレコードの行数、Accessはファイル容量2GBまでと、集計・分析できるファイルに制限があります。それに対し、Pythonであれば10GB、20GB等の大容量ファイルの集計・分析を行うことが可能です(PCスペックにより扱えるファイル容量の上限は変わります)。
-
レベル2
データ集計・分析だけでなく一部の機械学習ができる(「notebook」フォルダに格納している03のipynbファイル(タイタニック)を見た時に何を実施しているのか理解できるようになる)。 -
レベル3
Kaggle等の機械学習コンペに参加できるようになる
ダウンロード
コンテンツはGitHubよりダウンロードできます。
使用範囲/注意事項
-
使用範囲
個人・法人を問わず誰でも使用可能
(有志の勉強会や社内の研修で使う際、ご一報いただけると作者のモチベーションが上がります。「このコンテンツがPython認定試験の取得に役立った」のようなコメントも嬉しいです) -
注意事項
コンテンツの再配布・改編は不可
その他(Scratchpad)
Jupyter Notebookの拡張機能としてnbextensionsのScratchpadが便利なのでインストールをおすすめしておきます。100本ノックに取り組んでいる途中、データフレームに格納しているデータ内容を確認するためにいちいち「新規セル追加 → df.head()」をするのは面倒です。Scratchpadを使えば、「Ctrl+B」で使い捨てのセル領域を呼び出すことができます。
インストール方法は以下を参考にして下さい。
【Python】jupyter notebookの機能拡張 ~jupyter notebook extensions~
最後に
本コンテンツに関してご質問・ご要望があればご連絡下さい。
※ 2023/1/27 大変光栄なことに記事の閲覧回数が100,000viewsを越えました。
また、企業様より社内育成で使用しているというお声もいただいております。
誠にありがとうございます。
更新履歴
-
2021/3/1:V1.0.4に更新
・設問71の回答誤りを修正
・一部の問題の文の表現を修正 -
2020/10/21:V1.0.3に更新
・設問34と64の回答誤りを修正 -
2020/10/2:V1.0.2に更新
・設問66と67の回答誤りを修正(mean(平均値)とmedian(中央値)が逆) -
2020/9/28:V1.0.1に更新
・Mac環境にてファイルがansリスト、quesリストに順番通り読み込まれない不具合を修正
・回答ファイル17、47の回答誤りを修正
・100本ノックのすべての回答と出力結果を最初から表示してあるipynbファイル(all_answer_displayed)を追加で同封(まとめて回答、出力結果を確認したいときにご活用下さい)