はじめに
ZoomがSDKを提供しはじめたということで盛り上がりを見せている昨今ですが、Qiitaでも盛り上げイベントが開催されています。SDKでいろいろ遊ばせてもらえる上に、アイテムもゲットできるかも、ということで参加するしかないですね。
ということで、これを機にいろいろ実験してみたのですが、面白そうなことがたくさんできそうだったので、いくつか連投する予定です。ご興味を持たれましたら、後続の投稿もご覧ください。
第1回の記事はこちら⇒Zoom Meeting SDKでタイムキーパーちゃんを作る
第2回の記事はこちら⇒Zoom Meeting SDKでアバターにいろいろしゃべらせる
第3回の記事はこちら⇒Zoom Meeting SDKをつかって会議にアバターで参加する
第4回の記事はこちら⇒Zoom Meeting SDKでなんちゃってボイスチェンジャー
番外編の記事はこちら⇒Zoom Meetingにアバターで参加するぞ。番外編
第5回の記事はこちら⇒Zoom Meeting SDKとVosk browserでZoom会議のリアルタイム文字起こし ←本記事
Zoomに対してのデータの流れでいうと、マイクとカメラによる入力と、スピーカーからの出力の2系統に大別できると思います。これまで、全4回にわたりZoom Meeting SDKを使ってアバターを作ってきました。これまでは入力を主に対象にいろいろと実験してきましたが、今回は出力の方を何とかいじれないか考えてみたいと思います。
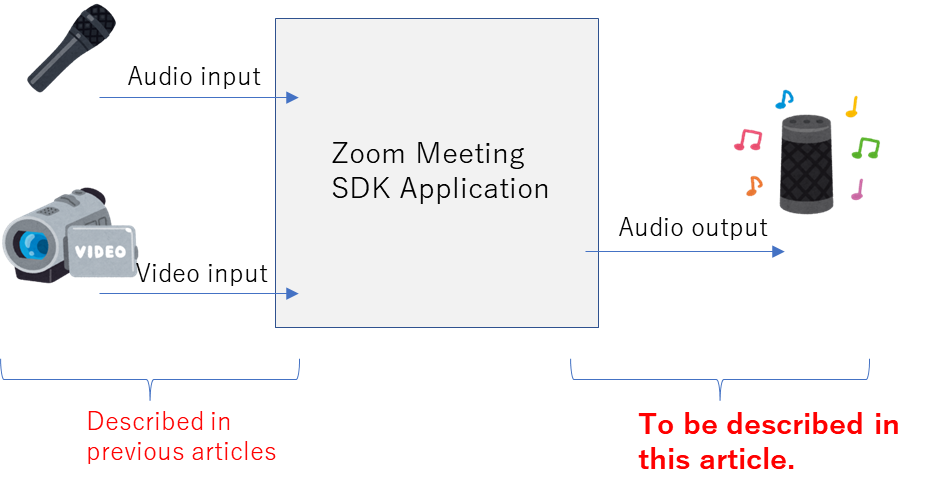
ということで、今回はZoom会議の音声のリアルタイム文字起こしをしてみたいと思います。Zoomでもリアルタイム文字起こし機能を提供していますが、日本語はまだ対応していないようなのでちょうどよいかと思います。また、他の類似サービスと比較してZoomの強みの一つはE2EEができることだと考えています。文字起こしをサーバでやってしまってはその強みが失われますので、クライアント側でやってしまうのは一つの価値になるかと思います。
動きは次のようになります。
Vosk(Vosk Browser)というライブラリを使って、ブラウザ上で音声認識を動かしています。Googleの Speech Recognition APIに比べると精度は数段落ちますが、サーバ側にデータが送信されないという利点はユースケースによっては大きいものになるかと思います。
操作は次の通りです。
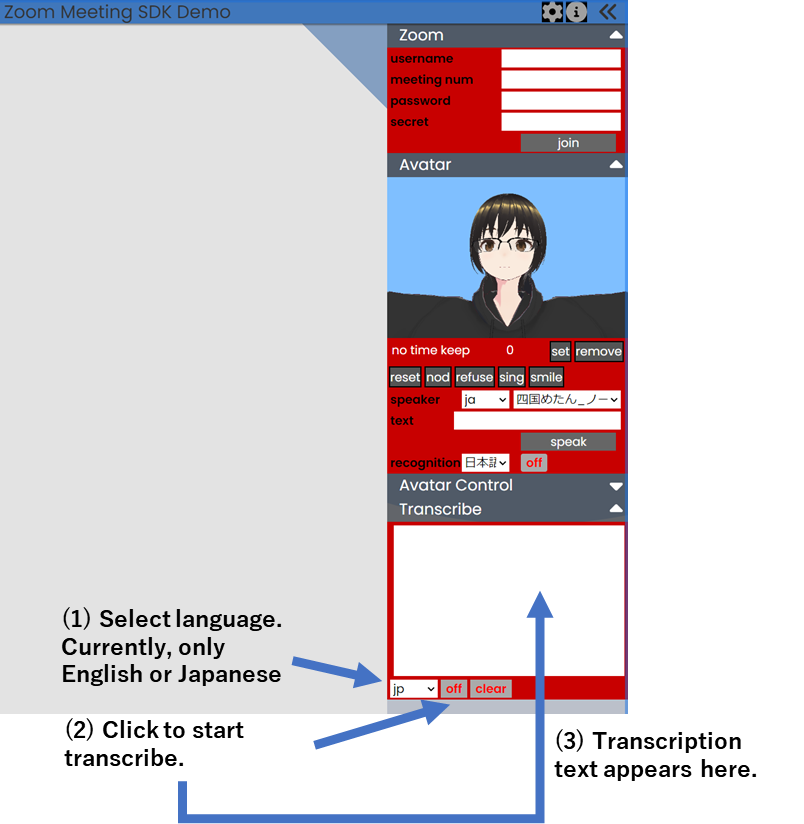
今回も、Dockerイメージの作成に加えて、Herokuにもデプロイしています。とりあえず、使ってみてください。
■ Dockerコンテナの起動
$ docker run -p 8888:8888 dannadori/zoom-meeting-plus:v06
$ docker run --rm -it -p '127.0.0.1:50021:50021' voicevox/voicevox_engine:cpu-ubuntu20.04-latest
$ docker run -it -p 5500:5500 synesthesiam/opentts:en
http://localhost:8888/ にアクセスすれば使えるようになります。
なお、httpで起動しているのでローカルで使用する必要があります。
■ Heroku上のアプリにアクセス
Herokuは一定時間アクセスがないと停止してしまい、再起動に少々時間がかかります。アプリ開始されるまで気長にお待ちください。(多分1分もかからないと思います。)
構成
Zoom会議の音声はZoom Meeting SDKが出力先として使用するHTMLAudioElementからMediaStreamとして取得しています。このMediaStreamをソースとしたWebAudioAPIのAudioNodeを作成します。また、このMediaStream内には、ローカルの音声(自分のマイク、アバターの音声)は含まれていないようです。それぞれをソースとするAudio Nodeを作成しておきます。これらをDestinationNodeに接続し、そこからMediaStreamを取得して、Vosk Browserに入力します。これにより、Zoom会議の文字起こしをリアルタイムに行うことができるようになります。
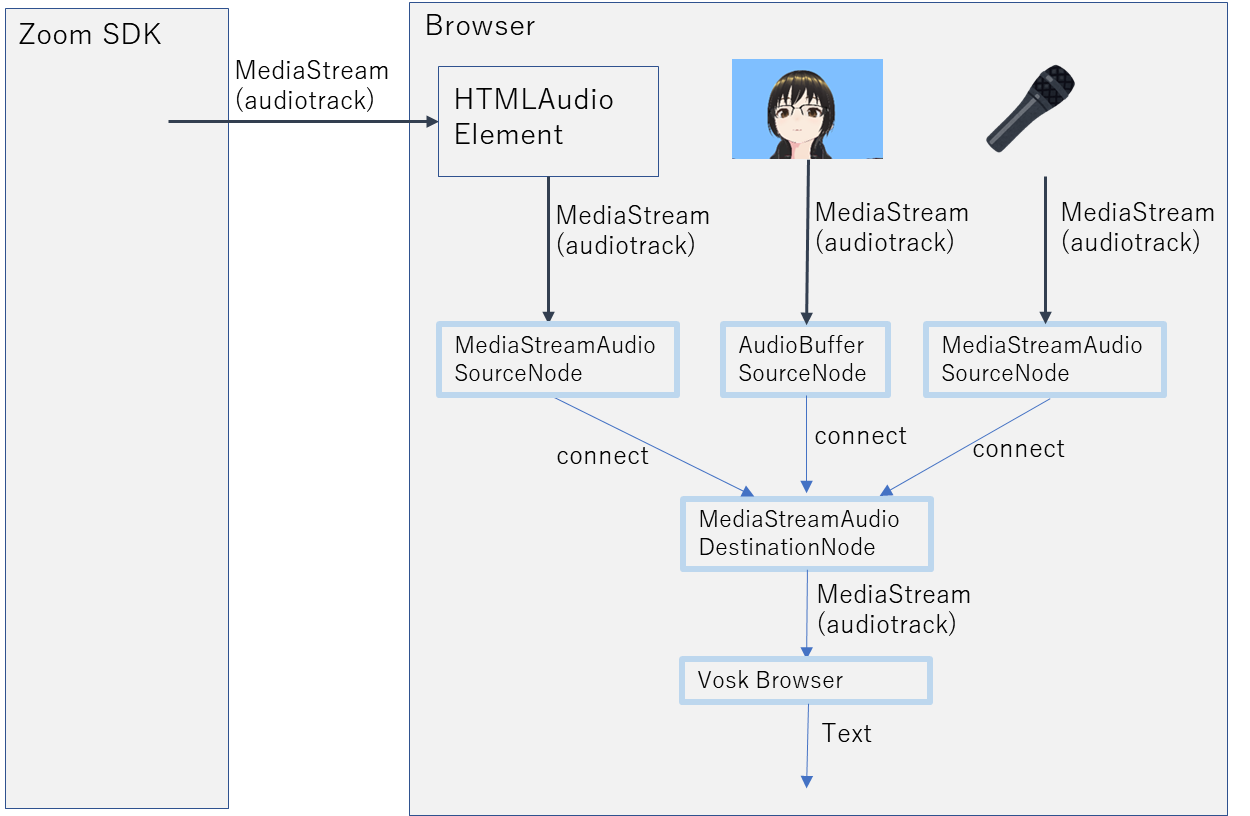
なお、上述の通り、Vosk(Vosk Browser)の精度はGoogleの Speech Recognition APIと比較すると数段落ちます。また、私の環境だとヘッドセットからの入力だと比較的高い精度で認識されましたが、ノートPC内臓マイクだとほとんど認識されないという現象がありました。人間の耳で聞くと内臓マイクの方が多少クリアでないかな?くらいで、ほとんど変わらないような気がするので不思議です。試しに、全く同じ音声をMediaRecorder録音して、Googleの Speech Recognition APIで書き起こしをしたところ、内臓マイクからの入力もヘッドセットからの入力もどちらもしっかり認識されましたので、Voskの日本語事前学習モデルの特性なのかもしれません。必要に応じてGoogleの Speech Recognition APIを使用してみてください。上記の構成図のVoskBrowserの部分をMediaRecorderに置きかえてGoogleのAPIを叩けば実現できます。(私は、PythonのSpeechRecognitionを使って自分でサーバを立てて実験しました。近いうちにご紹介したいと思います。)
リポジトリ
ここで紹介したデモは次のリポジトリで公開しています。
https://github.com/w-okada/zoom-meeting-plus
どんどんアップデートしていくので最新版は安定しない可能性があります。
次のタグでcloneして使ってください。
$ git clone https://github.com/w-okada/zoom-meeting-plus -b v06
宣伝
弊社 FLECT は、Salesforce を中心に AWS, GCP, Azure を用いたマルチクラウドシステムの提案、開発を行っております。 また、ビデオ会議システムについては、Zoom SDK, Amazon Chime SDK, Twillio など各種ビデオ会議用 SDK を用いたシステムの開発しており、サービス化の実績も多数あります。 ご興味をお持ちいただけたら是非ご相談ください。
謝辞
デモで使われている音声はCommon Voiceデータセットから借用しています。