はじめに
ZoomがSDKを提供しはじめたということで盛り上がりを見せている昨今ですが、Qiitaでも盛り上げイベントが開催されています。SDKでいろいろ遊ばせてもらえる上に、アイテムもゲットできるかも、ということで参加するしかないですね。
ということで、これを機にいろいろ実験してみたのですが、面白そうなことがたくさんできそうだったので、いくつか連投する予定です。ご興味を持たれましたら、後続の投稿もご覧ください。
第1回の記事はこちら⇒Zoom Meeting SDKでタイムキーパーちゃんを作る
第2回の記事はこちら⇒Zoom Meeting SDKでアバターにいろいろしゃべらせる
第3回の記事はこちら⇒Zoom Meeting SDKをつかって会議にアバターで参加する
第4回の記事はこちら⇒Zoom Meeting SDKでなんちゃってボイスチェンジャー ←本記事
番外編の記事はこちら⇒Zoom Meetingにアバターで参加するぞ。番外編
第5回の記事はこちら⇒Zoom Meeting SDKとVosk browserでZoom会議のリアルタイム文字起こし
前回は、Zoom で使えるアバターにユーザの動作を同期させてみました。今回はユーザの会話をボイスチェンジャー的に別の声に変換して伝えてみたいと思います。しかし、リアルタイムに声を綺麗に変換するのは難しく、機械音っぽくなってしまいます。今回は、ちょっとタイムラグがありますが、音声認識をしてからText-To-Speechでしゃべらせるという方向で考えてみたいと思います。なんちゃってボイスチェンジャーですね。
こんな感じに動きます。
お聞き苦しいですが男の声は私の声です(涙)。その後の女性の声がシステムから出力されたものです。内部的にはText-To-Speechなので、発声時のイントネーションとかは完全に失われますが、それなりに良い感じで動いていると思います。
なお、素のマイク入力を相手に送信するかしないかは設定で変えることができます。
今回からDockerイメージの作成に加えて、Herokuにもデプロイしています。とりあえず、使ってみてください。
■ Dockerコンテナの起動
$ docker run -p 8888:8888 dannadori/zoom-meeting-plus:v04
$ docker run --rm -it -p '127.0.0.1:50021:50021' voicevox/voicevox_engine:cpu-ubuntu20.04-latest
$ docker run -it -p 5500:5500 synesthesiam/opentts:en
http://localhost:8888/ にアクセスすれば使えるようになります。
なお、httpで起動しているのでローカルで使用する必要があります。
■ Heroku上のアプリにアクセス
Herokuは一定時間アクセスがないと停止してしまい、再起動に少々時間がかかります。アプリ開始されるまで気長にお待ちください。(多分1分もかからないと思います。)
操作は次の通りです。
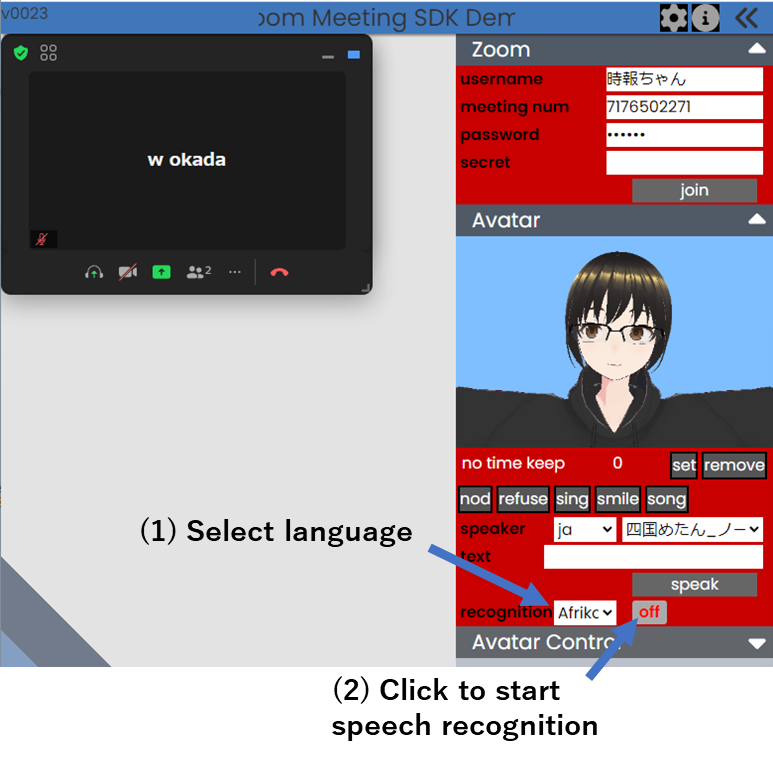
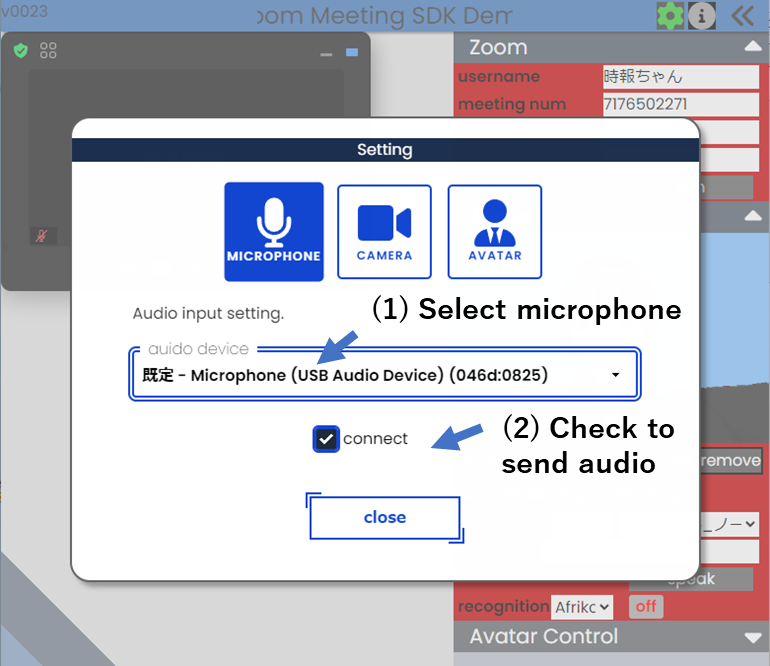
マイク入力をそのまま相手に送信したい場合は、ギアのアイコンから設定画面を開いてください。マイクを選択して"connect"をチェックすると相手に送信されます。
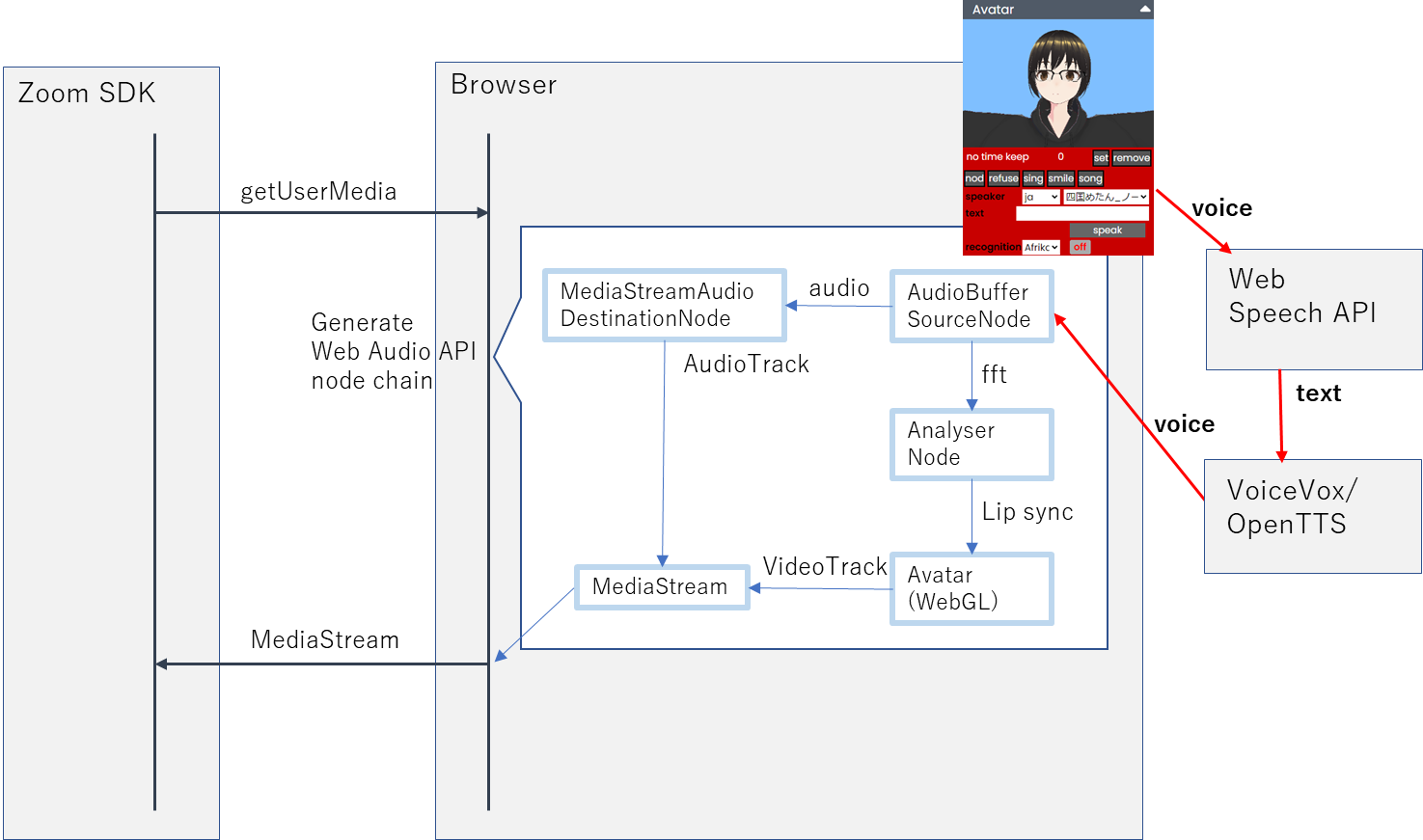
構成
今回は、音声認識をしたうえでText-To-Speechを行って音声に戻しています。音声認識にはChromeのWeb Speech APIを使用しています。音声認識により出力されたテキストを、以前の記事で紹介したVoiceVox, あるいはOpenTTSに入力して音声を生成しています。生成された音声は、これまでご紹介してきたWeb Audio APIのノードチェインに流し込んで相手に送信します。
デモ
記事の冒頭で示した通りです。
リポジトリ
ここで紹介したデモは次のリポジトリで公開しています。
https://github.com/w-okada/zoom-meeting-plus
どんどんアップデートしていくので最新版は安定しない可能性があります。
次のタグでcloneして使ってください。
$ git clone https://github.com/w-okada/zoom-meeting-plus -b v04
宣伝
弊社 FLECT は、Salesforce を中心に AWS, GCP, Azure を用いたマルチクラウドシステムの提案、開発を行っております。 また、ビデオ会議システムについては、Zoom SDK, Amazon Chime SDK, Twillio など各種ビデオ会議用 SDK を用いたシステムの開発しており、サービス化の実績も多数あります。 ご興味をお持ちいただけたら是非ご相談ください。