はじめに
JSで描画されるWebページが増え定期的にチェックする場合にクロールするのが厄介になりました。
LambdaでChromeのHedadlessブラウザでアクセスさせたいときに簡単な方法があったのでメモ
-
chrome-aws-lambdaのarnの取得
検索するともろもろzipで固めてアップロードみたいな形が多いのですが公式にLambda Layerのarnが公開されています。
https://github.com/shelfio/chrome-aws-lambda-layer
こちらからリージョンにあわせたものをコピーしてください
参考:東京リージョン(ap-northeast-1)
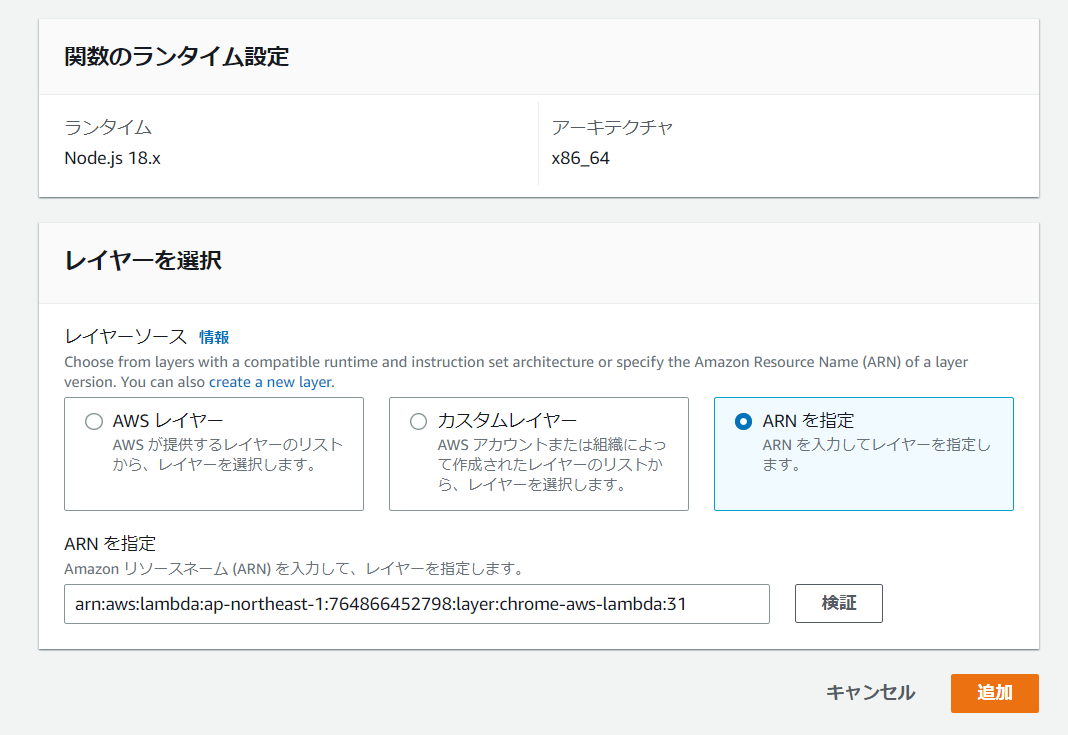
arn:aws:lambda:ap-northeast-1:764866452798:layer:chrome-aws-lambda:31 -
Lambda Layerを登録
Lambda上で通常通りに関数を作成します。
その後にコードの下にあるLayersをクリックします。
そして先ほどコピーしたarnをARNを指定にチェックをいれて入力します。
-
コードを書きます
const chromium = require("@sparticuz/chrome-aws-lambda");
exports.handler = async(event, context) => {
const browser = await chromium.puppeteer.launch({
args: chromium.args,
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath,
headless: chromium.headless,
});
let page = await browser.newPage();
await page.goto('https://www.yahoo.co.jp/');
const pageTitle = await page.title();
await page.waitForSelector('#tabpanelTopics1');
const innerText = await page.evaluate(() => (document.querySelector('#tabpanelTopics1')).innerText);
await browser.close();
return pageTitle+"\n\n"+innerText;
};