概要
以前作成した記事から、あえて汎用性を高めるために機能を削ぎ落としたデグレード(シンプル)版です。
「大量の領収書をとりあえずリスト化したい」「名刺の束をテキストデータにしたい」といった、前工程を選ばない全方位型の自動化ツールです。
実現できること
- 指定フォルダ内の全画像を自動で認識
- Google DriveのOCR機能でテキストを抽出
- スプレッドシートに「No」「ファイル名」「抽出テキスト」を1行ずつ追記
- 処理が終わった画像は「処理済みフォルダ」へ自動移動(二重処理を防止)
事前準備
このスクリプトを動かすには、Google ドライブ上に専用の場所(フォルダ)と、データを書き込むためのスプレッドシートが必要です。以下の手順で準備を行ってください。
1. Google ドライブに 2 つのフォルダを作成する
まず、画像のやり取りを行うための場所を 2 つ用意します。
① 入力用フォルダ (Input)
OCR処理したい画像をアップロードするためのフォルダです。
② 処理済みフォルダ (Done)
OCRが終わった画像が自動的に移動してくる、保管用のフォルダです。
※各フォルダを開いた時の URL(folders/ 以降の文字列)が フォルダ ID になります。あとで使うのでメモしておきましょう。
2. 書き込み用のスプレッドシートを用意する
OCRで読み取ったテキストを転記するスプレッドシートを作成します。
シート名の設定
デフォルトでは「シート1」という名前のシートに書き込まれます。
ヘッダー(見出し)の作成
1行目に「No」「画像名」「読み取り内容」などの見出しを入力しておくと、2行目からデータが綺麗に蓄積されます。
3. スクリプトプロパティの設定
作成したフォルダやシートをスクリプトに教えるために、Google Apps Script の「プロジェクトの設定(歯車アイコン)」から以下の スクリプトプロパティ を登録してください。

-
INPUT_FOLDER_ID
解析したい画像を入れるフォルダのID。GoogleドライブのフォルダのURLの/drive /foldersの後ろの文字列。 -
DONE_FOLDER_ID
処理が終わった画像を移動させるフォルダのID。GoogleドライブのフォルダのURLの/drive /foldersの後ろの文字列。 -
SPREADSHEET_ID
画像から抽出した文字列を転記するシートのID。転記させるスプレッドシートのURLの /d/ と /edit の間の文字列。 -
SHEET_NAME
画像から抽出した文字列を転記するシート名
Google Drive(マイドライブなど)
┃
┣ [実行ボタン](図形描画) <--- ★ユーザーはここを押すだけ!
┃ ┗ スクリプト「processImagesToSheet」を割り当て
┃
┣ [■入力用フォルダ] (INPUT_FOLDER_ID)
┃ ┗ □画像ファイルA.jpg(処理待ち)
┃ ┗ □画像ファイルB.png
┃
┣ [■処理済みフォルダ] (DONE_FOLDER_ID)
┃ ┗ □画像ファイルC.jpg(処理完了後に自動移動)
┃
┗ [■転記用スプレッドシート] (SPREADSHEET_ID)
┃
┣ □[Gas] スクリプトエディタ (ここにコードを記述)
┃ ┗ □スクリプトプロパティ (各IDを保存)
┃
┗ □「シート1」(SHEET_NAME)
┗ 1行目:[No] [画像名] [読み取り内容] <-- ヘッダー
┗ 2行目:[ 1] [画像A] [OCRテキスト...] <-- 追記データ
4.Google Drive API の有効化
このスクリプトは、Googleドライブの高度な機能(OCR)を利用するために「Google Drive API」を使用します。以下の設定を行わないと、実行時に ReferenceError: Drive is not defined というエラーが発生します。
GASエディタでの設定
- GASエディタを開く
- スプレッドシートの [拡張機能] > [Apps Script] をクリック。
「サービス」を追加する
エディタ左側のメニューにある「サービス +」ボタンをクリックします。
Drive APIを選択
リストの中から「Drive API」を探して選択します。
追加を確定
- バージョンは最新(デフォルト)のままで、「追加」ボタンを押します。
- 左側のサービス一覧に「Drive」が表示されれば準備完了です。
5.ソースコード
スクリプトエディタに以下を貼り付ける。
/**
* フォルダ内の全画像をOCRしてスプレッドシートに転記
*/
function processImagesToSheet() {
const props = PropertiesService.getScriptProperties();
const INPUT_FOLDER_ID = props.getProperty("INPUT_FOLDER_ID");
const DONE_FOLDER_ID = props.getProperty("DONE_FOLDER_ID");
const SPREADSHEET_ID = props.getProperty("SPREADSHEET_ID");
const SHEET_NAME = props.getProperty("SHEET_NAME");
if (!INPUT_FOLDER_ID || !DONE_FOLDER_ID) {
console.warn("プロパティにフォルダIDを設定してください。");
return;
}
const inputFolder = DriveApp.getFolderById(INPUT_FOLDER_ID);
const doneFolder = DriveApp.getFolderById(DONE_FOLDER_ID);
// --- スプレッドシートの指定処理 ---
let ss;
if (SPREADSHEET_ID) {
ss = SpreadsheetApp.openById(SPREADSHEET_ID);
} else {
// ID指定がない場合は、スクリプトが紐付いているシートを開く
ss = SpreadsheetApp.getActiveSpreadsheet();
}
let sheet = ss.getSheetByName(SHEET_NAME);
// 指定したシート名が存在しない場合の予備処理
if (!sheet) {
console.warn(`シート「${SHEET_NAME}」が見つかりません。アクティブなシートを使用します。`);
sheet = ss.getActiveSheet();
}
// ------------------------------
// 1. フォルダ内の画像ファイルを取得(作成日時順にソート)
let fileList = [];
const files = inputFolder.getFiles();
while (files.hasNext()) {
const file = files.next();
if (file.getMimeType().includes("image")) {
fileList.push(file);
}
}
fileList.sort((a, b) => a.getDateCreated() - b.getDateCreated());
if (fileList.length === 0) {
console.log("処理対象の画像が見つかりませんでした。");
return;
}
let results = [];
// --- Noの初期値計算 ---
let lastRow = sheet.getLastRow();
// もし最終行が0(空)なら、ヘッダーもないので0からスタート
// もし最終行が1以上なら、1行目はヘッダーとみなして「最終行 - 1」を現在の件数とする
let currentNo = lastRow > 0 ? lastRow - 1 : 0;
// 2. 1枚ずつ順番にOCR処理
for (let i = 0; i < fileList.length; i++) {
const file = fileList[i];
const fileName = file.getName();
try {
console.log(`解析開始 (${i + 1}/${fileList.length}): ${fileName}`);
// OCR実行
const extractedText = extractText(file.getId());
// [No, 画像名, 読み取り文字列] の形式で配列に追加
// 改行をスペースに置換して、1つのセルに収まりやすく整形
const cleanText = extractedText.trim().replace(/\n/g, " ");
results.push([
++currentNo,
fileName,
cleanText
]);
// 成功したら「処理済みフォルダ」へ移動
doneFolder.addFile(file);
inputFolder.removeFile(file);
} catch (e) {
console.error(`エラー発生 (${fileName}): ${e.toString()}`);
}
}
// 3. スプレッドシートの最終行に一括追記
if (results.length > 0) {
const targetRange = sheet.getRange(sheet.getLastRow() + 1, 1, results.length, 3);
targetRange.setValues(results);
console.log(`${results.length} 件の転記が完了しました。`);
}
}
/**
* Drive API を使用したOCR処理
*/
function extractText(fileId) {
const resource = {
title: "temp_ocr_" + new Date().getTime(),
mimeType: "application/vnd.google-apps.document"
};
// Googleドキュメントとしてコピー(OCRを有効化)
const tempFile = Drive.Files.copy(resource, fileId, { ocr: true, ocrLanguage: "ja" });
const doc = DocumentApp.openById(tempFile.id);
const text = doc.getBody().getText();
// 一時ファイルはすぐに削除
Drive.Files.remove(tempFile.id);
return text;
}
※フローは以下
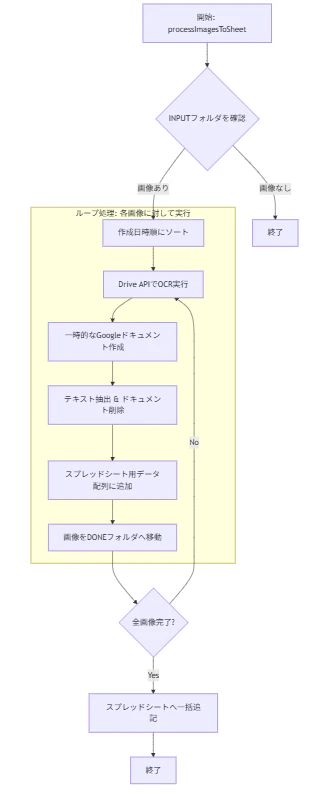
6.実行ボタンの設置と紐付け
スプレッドシート上に「実行ボタン」を作成し、スクリプトをワンクリックで動かせるように設定します。
①ボタンの作成(済みの場合は次へ)
メニューの [挿入] > [図形描画] を選択します。
「図形」アイコンから好きな形(ボタン風の四角など)を選び、テキストで「画像から文字列抽出」と入力して保存します。
②スクリプトの割り当て
- スプレッドシート上に配置されたボタン(図形)を 右クリック
- 右上の [︙](三点リーダー) をクリックし、[スクリプトを割り当て] を選択
- 入力欄に、実行したい関数名processImagesToSheetを入力し、[OK] を押下

3. 実行テスト
ボタンを左クリック
初回実行時は「承認」を求めるポップアップが出ますので、画面の指示に従って許可してください(自分のアカウントを選択 → 詳細 → 安全ではないページに移動 → 許可)。
実行後
2ファイル分実行してみましたが、以下のように転記されました。
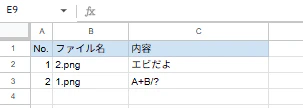
解説・ポイント
-
デグレード版のメリット
ペア処理などの制約をなくしたことで、写真が1枚だけでも、奇数でも、どんな順番でもエラーなく「とにかくリスト化」することを優先しています。 -
No.の自動採番
sheet.getLastRow() を基準にしているため、すでにデータがあるシートに追記しても番号が連続します。 -
一括書き込み(setValues)
1行ずつ appendRow するのではなく、最後にまとめて書き込むことで、処理速度の向上とスプレッドシートへの負荷を軽減しています。
感想
画像を抽出したいときに便利だったので、有効活用します。