読者ターゲット
この記事は次のような人を対象にしています。
- 資格勉強や技術書の内容を 写真ベースで Anki に取り込みたい人
- Google DriveとApps Scriptを使った自動化パイプラインの実例を探している人
- OCR→テキスト整形→CSV→Ankiという現実的なワークフロー を知りたい人
- GASでDrive APIを使う際の実践的なコード例 を知りたい人

0.全体アーキテクチャ
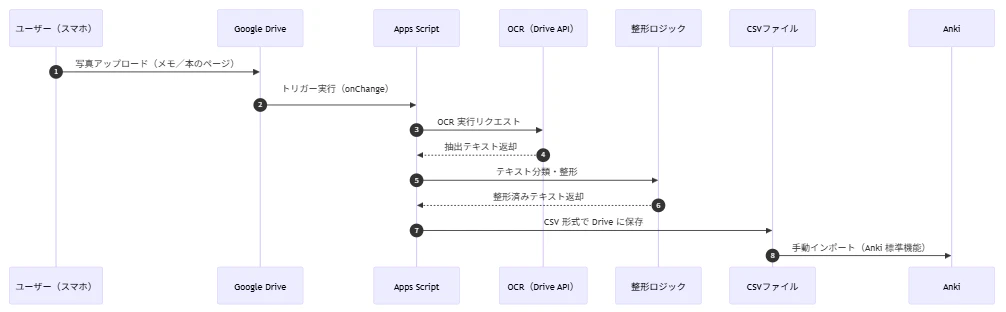
1.なぜこの仕組みを作ったか
資格勉強で「メモ」「本のページ」「黒板」「スライド」などを写真に撮ることが多く、これを手動でAnkiに転記するのが非常に手間でした。そこで、写真を撮るだけでAnkiカードが半自動生成されるパイプラインを構築しました。
2.使用技術
- Google Drive(写真の自動アップロード)
- Google Apps Script(トリガー処理・OCR・整形)
- Google Drive API(OCR)
- Anki(最終的なカード管理)
3.フローの詳細
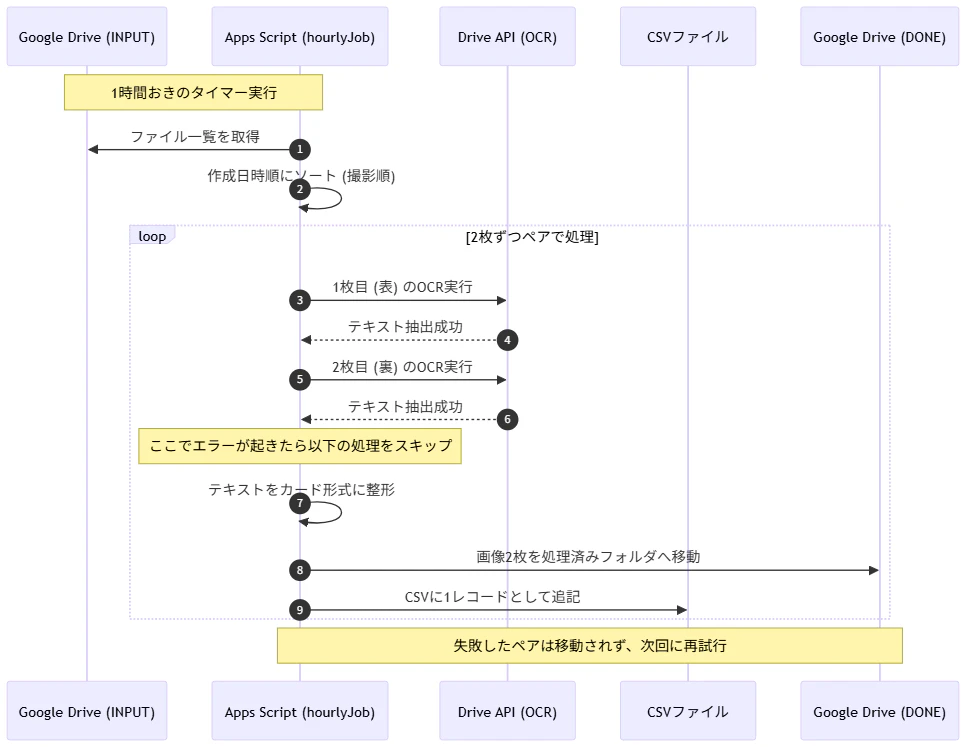
3-1.運用フロー
①スマホで写真を撮る
②Google Driveの特定フォルダに画像(※1)を、問題→解答→問題の順にアップロード(※2)。
- (※1)入れる画像は問題文と解答のみの部分にトリミングすること。
- (※2)Google Driveのファイルを直接参照する場合、インポートする前にGoogle Driveアプリから更新しないと、AnkiDroidでCSVファイルを選択するときにファイルが更新されないので注意
③定期実行間隔後(処理が重くならないように1時間間隔を想定)に出力されたCSVをAnkiDroidアプリにインポート(※3)
- (※3)あらかじめ暗記カード用のデッキを作成する必要あり。
3-2.処理フロー
① データの収集と整列
INPUT_FOLDER 内にある画像ファイルをすべて取得します。
ここで重要なのが 「作成日時順のソート」 です。スマホからアップロードされた順番(=撮影した順番)に並べることで、「1枚目が問題、2枚目が解答」というペアを確実に特定します。
② ペア成立のチェック
ファイル数が奇数だったり、1枚しかなかったりする場合は、無理に処理せず 「待機」 します。これにより、2枚目のアップロードが遅れている最中に中途半端なカードが作られるのを防ぎます。
③ OCRの実行(1枚ずつ)
Drive API を使って、画像から文字を抜き出します。
問題画像 → 表面用のテキストへ
解答画像 → 裏面用のテキストへ
この段階でAPIエラーや通信瞬断が起きると、即座に catch(エラー処理)へ飛びます。
④ 成功時のみの確定処理(Atomic操作)
「OCRが2枚とも成功した時だけ」 以下の処理をセットで行います。
リストに追加: CSVに書き込むためのメモリ上のリストに保存。
ファイルの移動: 元のフォルダから削除し、処理済みフォルダへ移動。
もしOCRが失敗した場合、移動処理(removeFile)に到達しません。その結果、画像は元のフォルダに残るため、「画像が消えたのにカードができていない」という事態を100%防げます。
⑤ CSVへの一括書き出し
ループがすべて終わった後、成功したカードたちをまとめて anki_cards_import.csv に書き込みます。
改行コード \r\n を付与し、Ankiが「1行=1カード」として認識できる形式で保存して完了です。
4.コードと環境構築
①以下をGASに貼り付ける
/**
* 定期実行エントリポイント
* 2枚の画像を「表・裏」としてペア処理し、成功時のみ移動・CSV保存を行う
*/
function hourlyJob() {
const props = PropertiesService.getScriptProperties();
const INPUT_FOLDER_ID = props.getProperty("INPUT_FOLDER_ID");
const DONE_FOLDER_ID = props.getProperty("DONE_FOLDER_ID");
const CSV_FOLDER_ID = props.getProperty("CSV_FOLDER_ID");
if (!INPUT_FOLDER_ID || !DONE_FOLDER_ID || !CSV_FOLDER_ID) {
console.warn("フォルダIDが未設定です。設定を確認してください。");
return;
}
const inputFolder = DriveApp.getFolderById(INPUT_FOLDER_ID);
const doneFolder = DriveApp.getFolderById(DONE_FOLDER_ID);
// ファイルを取得して作成日時順にソート(撮影順を担保)
let fileList = [];
const files = inputFolder.getFiles();
while (files.hasNext()) {
const file = files.next();
// 画像ファイルのみを対象とする
if (file.getMimeType().includes("image")) {
fileList.push(file);
}
}
fileList.sort((a, b) => a.getDateCreated() - b.getDateCreated());
// 2枚ペアに満たない場合は終了
if (fileList.length < 2) {
console.log("処理待ちの画像がペア(2枚)に満たないため、待機します。");
return;
}
let newCards = [];
// 2枚ずつペアにして処理
for (let i = 0; i < fileList.length - 1; i += 2) {
const frontFile = fileList[i];
const backFile = fileList[i + 1];
try {
console.log(`処理開始: ${frontFile.getName()} & ${backFile.getName()}`);
// 1. OCR実行(ここでエラーが起きると catch へ飛ぶ)
const frontText = runOcr(frontFile.getId());
const backText = runOcr(backFile.getId());
// 2. テキスト整形
const front = frontText.split("\n")[0].substring(0, 50); // 1行目をタイトルに
const back = backText.trim().replace(/\n/g, "<br>"); // 改行をHTMLに
// 3. 全ての処理が成功したとみなして、リストに追加
newCards.push([front, back]);
// 4. 成功した場合のみ、ファイルを移動
doneFolder.addFile(frontFile);
inputFolder.removeFile(frontFile);
doneFolder.addFile(backFile);
inputFolder.removeFile(backFile);
console.log(`処理成功・移動完了: ${frontFile.getName()}`);
} catch (e) {
// エラーが発生した場合はここに飛ぶ
// 移動処理(removeFile)をスキップするため、画像は INPUT_FOLDER に残ります
console.error(`エラーのためスキップしました(ファイルは残ります): ${frontFile.getName()} - ${e.toString()}`);
}
}
// 今回の実行で成功したカードがあればCSVに書き出し
if (newCards.length > 0) {
saveToCsv(CSV_FOLDER_ID, newCards);
console.log(`${newCards.length} 件のペアをCSVに出力しました。`);
}
}
/**
* CSVとしてGoogleドライブに保存・追記する
*/
function saveToCsv(folderId, cardDataList) {
const fileName = "anki_cards_import.csv";
const folder = DriveApp.getFolderById(folderId);
const files = folder.getFilesByName(fileName);
let csvContent = "";
let file;
if (files.hasNext()) {
file = files.next();
csvContent = file.getBlob().getDataAsString("UTF-8");
if (csvContent && !csvContent.endsWith("\n")) csvContent += "\r\n";
}
const newRows = cardDataList.map(card => {
const front = card[0].replace(/"/g, '""');
const back = card[1].replace(/"/g, '""');
return `"${front}","${back}"`;
}).join("\r\n");
csvContent += newRows + "\r\n";
if (file) {
file.setContent(csvContent);
} else {
folder.createFile(fileName, csvContent, MimeType.PLAIN_TEXT);
}
}
/**
* Drive APIを使用したOCR処理
*/
function runOcr(fileId) {
const resource = {
title: "ocr-temp",
mimeType: "application/vnd.google-apps.document"
};
// Files:copy が失敗しても呼び出し元(hourlyJob)の catch で捕捉される
const doc = Drive.Files.copy(resource, fileId, { ocr: true, ocrLanguage: "ja" });
const docFile = DocumentApp.openById(doc.id);
const text = docFile.getBody().getText();
// OCR用の一時ドキュメントは必ず削除
Drive.Files.remove(doc.id);
return text;
}
/**
* テキスト分類と整形ロジック(表面をより具体的に修正)
*/
function classifyAndFormat(text) {
const lines = text.split("\n").filter(x => x.trim().length > 0);
const isQuestion = text.includes("とは") || text.includes("?");
if (isQuestion) {
const front = lines[0]; // 最初の1行を質問文にする
const back = lines.slice(1).join("<br>");
return { front, back };
}
// 要点抽出の場合も、最初の1行をタイトル的に使う
const front = lines[0].substring(0, 20) + "..."; // 最初の20文字をタイトルに
const back = lines.slice(0, 5).join("<br>");
return { front: front, back: back };
}
function extractQuestion(text) {
return text.split("\n")[0];
}
function extractAnswer(text) {
return text.split("\n").slice(1).join("<br>");
}
function summarize(text) {
const lines = text.split("\n").filter(x => x.trim().length > 0);
return lines.slice(0, 5).join("<br>");
}
②Google Drive API の有効化手順
このスクリプトは、Googleドライブの高度な機能(OCR)を利用するために「Google Drive API」を使用します。以下の設定を行わないと、実行時に ReferenceError: Drive is not defined というエラーが発生します。
GASエディタでの設定
- GASエディタを開く
- スプレッドシートの [拡張機能] > [Apps Script] をクリック。
「サービス」を追加する
エディタ左側のメニューにある「サービス +」ボタンをクリックします。
Drive APIを選択
リストの中から「Drive API」を探して選択します。
追加を確定
- バージョンは最新(デフォルト)のままで、「追加」ボタンを押します。
- 左側のサービス一覧に「Drive」が表示されれば準備完了です。
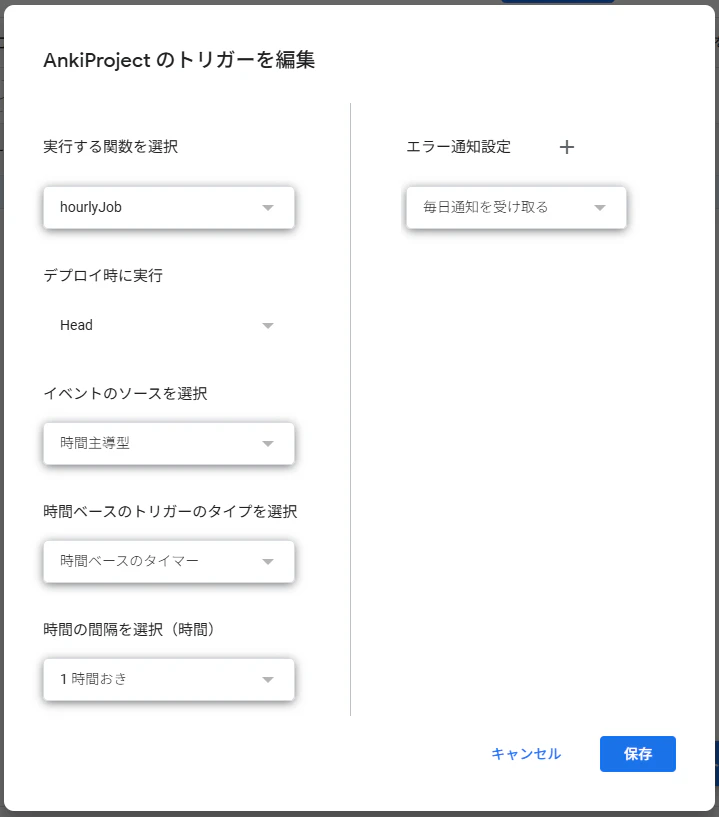
③トリガー設定
Apps Script→トリガー
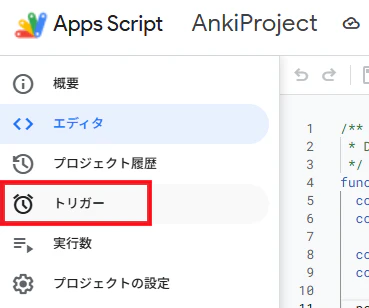
トリガーを追加を押下
画像の通り設定
※フォルダにファイルがアップロードされたらことをトリガーとしたかったが、UIのバグなのか出てこなかったため時間主導型に変更
フォルダ構成
④プロパティにIDを設定
・Apps Script の画面を開く
右上の「歯車」ではなく、左側メニューの 「プロジェクトのプロパティ」 を開く。

・「スクリプトのプロパティ」タブを選ぶ
「スクリプトのプロパティ」→「追加」

⑤Ankiアプリへの取り込み手順
CSVが出力された後は、以下の手順でスマホやPCのAnkiに取り込めます。
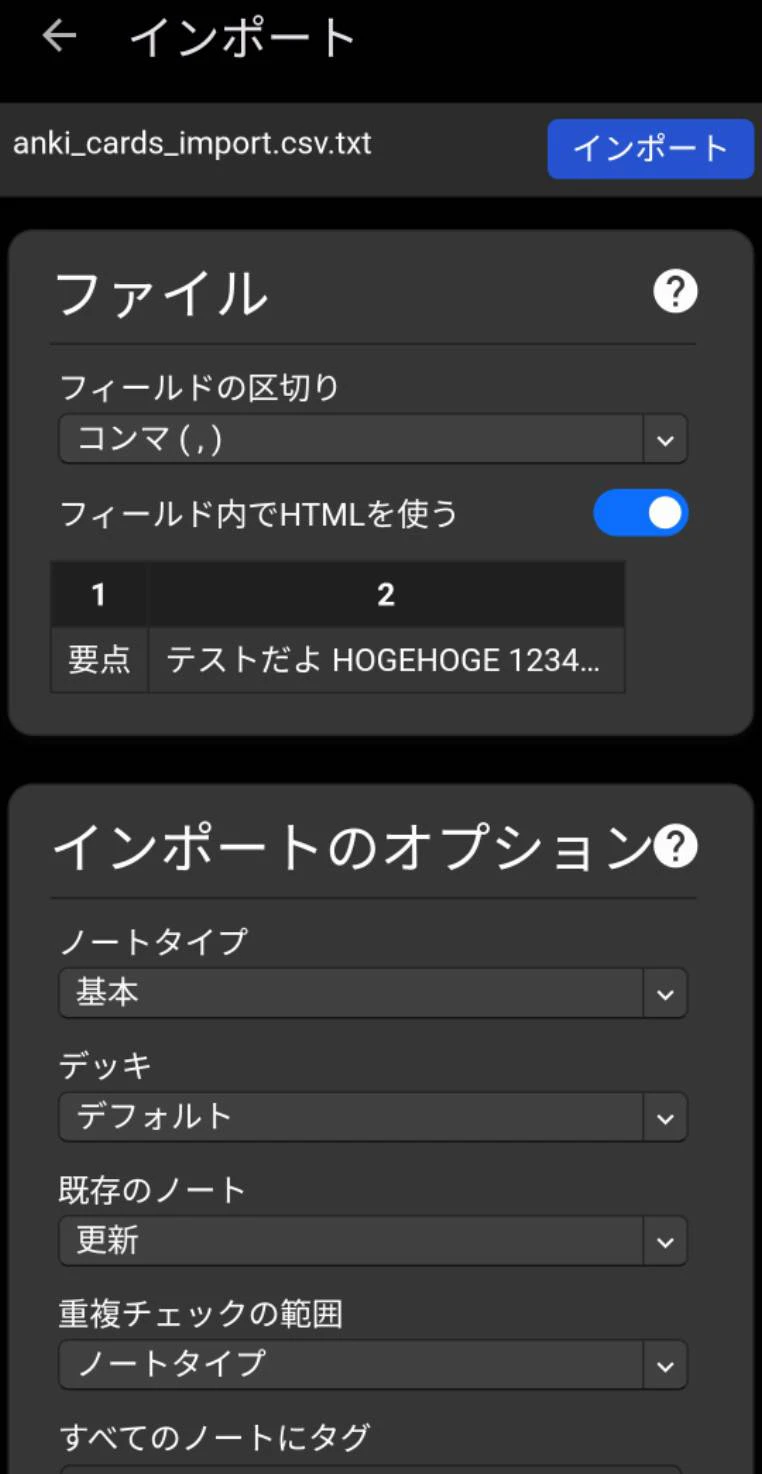
インポート: Ankiの「ファイルを読み込む」メニューからGoogleドライブの「anki_csv」フォルダの「anki_cards_import.csv」を選択。


⑥工夫した点
1.インポートエラーを防ぐ「CSV整形ロジック」の強化
一括インポート時に「1つのカードにまとまってしまう」問題を回避するため、以下の処理を実装しました。
- \r\n (CRLF) を明示的に使用し、Ankiが「1行 = 1カード」と正しく認識するように修正(改行コードの厳密化)
- テキスト内に " が含まれていてもCSV構造が壊れないよう、"" に置換する処理を追加(ダブルクォートのエスケープ)
2. 空振り(エラー)防止のガードレール実装
定期実行(トリガー)時に、フォルダが空だとエラーメールが飛んでくる問題を解決しました。
- files.hasNext() で、ファイルがある時だけ処理を開始(存在チェック)
- CSVファイル自体や画像以外のゴミファイルをOCR対象から除外(MIMEタイプ判定)
3. 表面(Front)の重複対策
- 課題
表面がすべて「要点抽出」だと、Ankiインポート時に「重複」とみなされて1枚しか登録されない(設定による)。
項目区切り: 「カンマ」を選択。
HTMLの許可: 「フィールドにHTMLが含まれる」に必ずチェックを入れる(< br >タグを改行として処理するため)。
整理: 取り込み終わったCSVファイルは、二重登録を防ぐためドライブ上から削除またはリネームしておきます。
暗記カードの表面の文字を修正:
現状コードでは、暗記カードの表面が「要点」で固定になっているので、登録するときに、お好きなものに書き換えます。
5.実際に使ってみた感想
写真を撮るだけで暗記カードが作れるため、手でノートをまとめる必要性が少なくなりました。OCRの精度も無料で使えるのであれば全然利用できると感じました。メモ・本・黒板など認識できました。また他のPython等で使用できるOCR機能である
Google Cloud Vision Pro APIとは異なり、クレジットカードの登録も不要なので運用コストを抑えられるところも比較するとコストパフォーマンスがいいと感じました。
6.今後の改善案
ここまでで現在のワークフローと実装の全体像を説明しました。実際に運用してみると、いくつか改善したいポイントが見えてきました。以下の表では、課題・原因・改善案・コスト・効果を整理しています。「どこから手を付けるべきか」を判断する材料としてまとめています。
| 課題 | 原因 | 改善案 | コスト | 効果 |
|---|---|---|---|---|
| CSV 取り込みが手動 | GAS→AnkiConnect 不可 | ローカル Python 化 | 中 | 高 |
| 画像に不要部分が写る | スクショ全体が対象 | トリミング or Vision API | 中 | 中 |
| 1画像=1カード | 単純設計 | LLM で複数カード抽出 | 高 | 高 |
| 要約精度が低い | ルールベース | Gemini / Claude API | 中 | 高 |
特に効果が高いのは「ローカルPython化」と「複数カード抽出」です。
ただし実装コストも高いため、まずはVision APIによる不要部分の除去から
着手するのが現実的です。