ついにChatGPT plusの音声会話機能で利用できていた、テキストの読み上げ機能がAPIでも使えるようになりましたね✨
今回は、Postmanを使って実際にこのAPIを使って音声ファイルを作ってみたいと思います。
APIドキュメント確認
OpenAIのテキスト読み上げ機能のAPIドキュメントは以下にあります
https://platform.openai.com/docs/guides/text-to-speech
Postmanでリクエストを出してみる
ここから、APIの仕様に沿って、Postmanを使ってリクエストを作っていきたいと思います。
Collectionの作成
まずは、Collectionの作成を行います。Collectionとは、Requestをまとめる単位です。フォルダのようなものだと考えるとわかりやすいかもしれません。

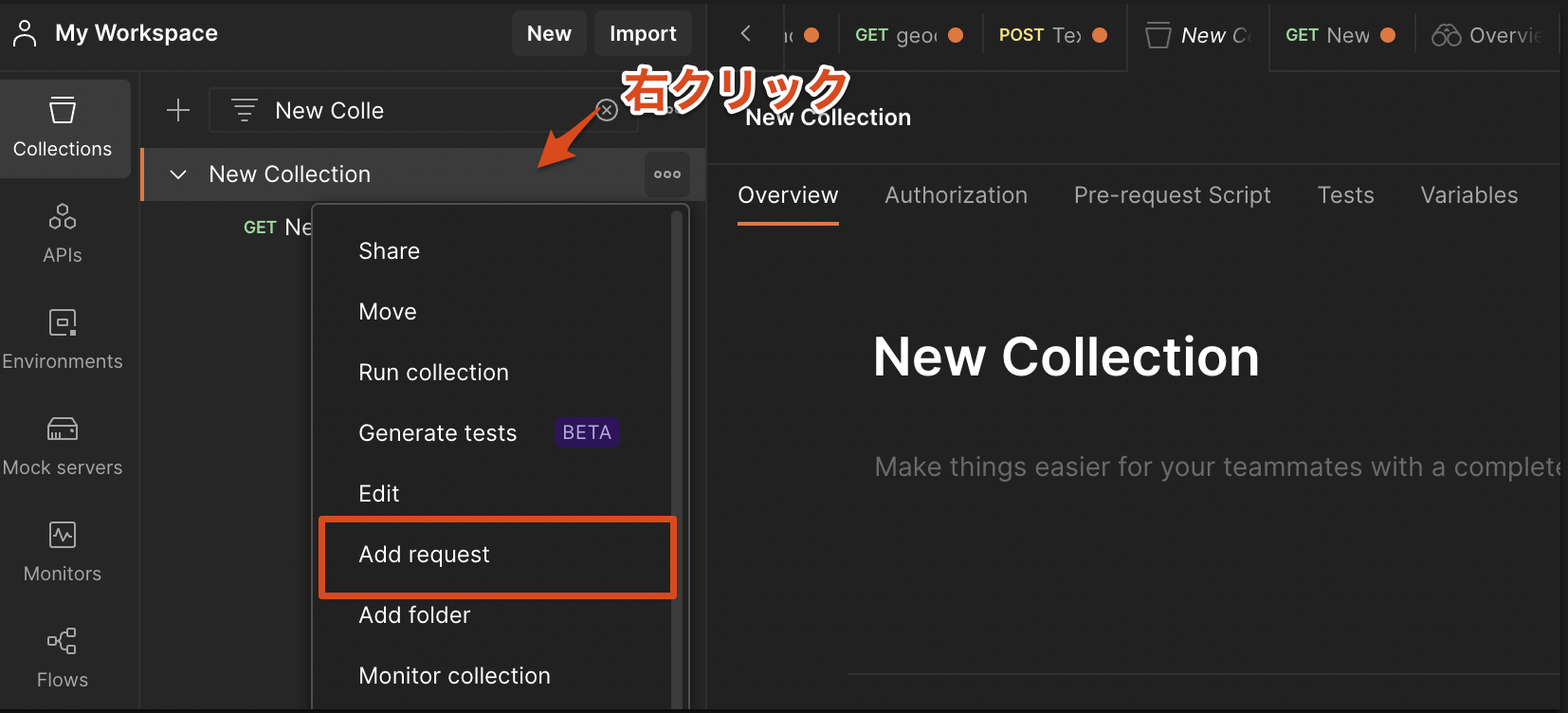
Requestの作成
次に、作成したCollectionを右クリックして > Add Collectionを選択することにより、Requestを作成します。
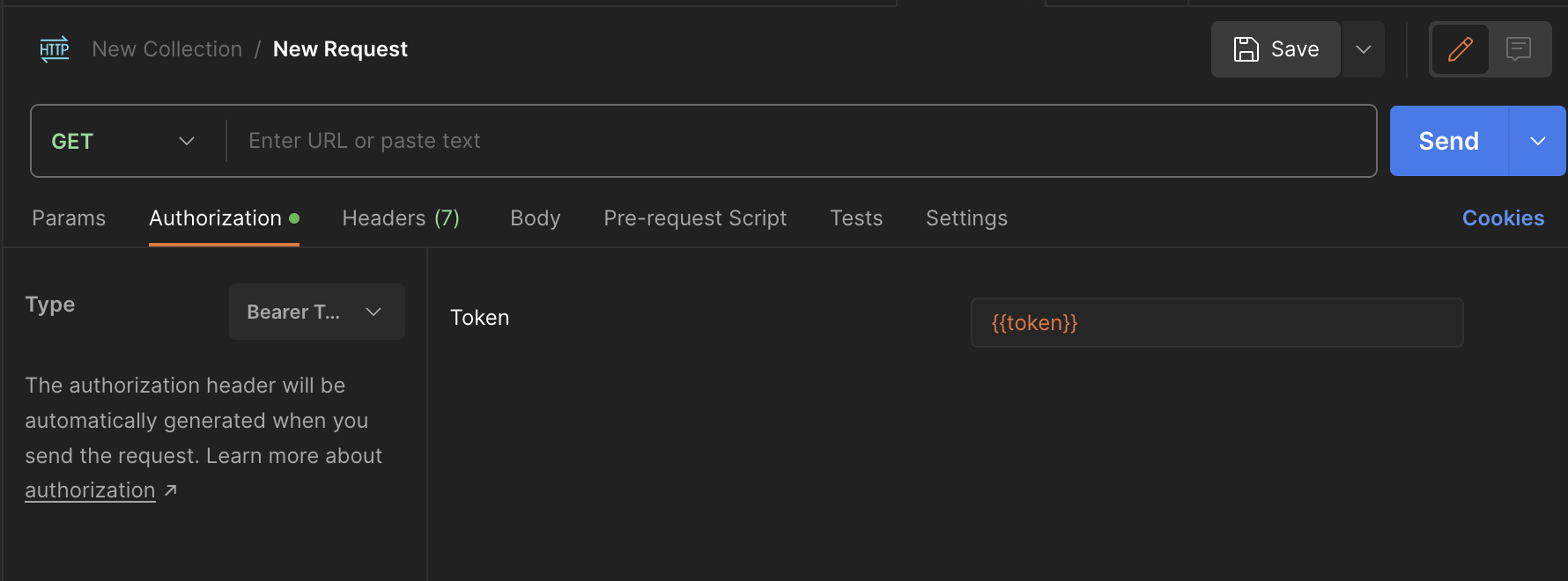
Authrizationの設定
Requestが作成できたら、Authorizationタブをクリックし、TypeにBearerTokenを選択し、Tokenの値にOpenAIから取得したAPI Keyを設定します。
Bodyの設定
最後に、Bodyの設定を行います。
Bodyタブを開き、rawを選択し、右側のプルダウンでJSONを選択し、下の入力エリアに以下の通りに値を設定します。

{
"model": "tts-1",
"input": "いきなりですけどね うちのオカンがね 好きな朝ごはんがあるらしいんやけど」「あっ そーなんや」「その名前をちょっと忘れたらしくてね」「朝ごはんの名前忘れてもうて どうなってんねそれ」「でまあ色々聞くんやけどな 全然分からへんねんな」「分からへんの? いや ほな俺がね おかんの好きな朝ごはん ちょっと一緒に考えてあげるから どんな特徴ゆうてたかってのを教えてみてよ」「あのー甘くてカリカリしてて で 牛乳とかかけて食べるやつやって言うねんな」「おー コーンフレークやないかい その特徴はもう完全にコーンフレークやがな」「コーンフレークなぁ」",
//alloy, echo, fable, onyx, nova, and shimmer.
"voice": "alloy",
"speed": 1
}
結果確認
実行が完了すると、以下の様に再生ボタンが表示されます。クリックするとその音声を聞くことができます。
実際には音声データが返ってきているのですが、それをPostmanが検知して簡単に確認できるようにしてくれています。すごいですね👩🚀

実際に出力された音声ファイル
上記の手順で実際に出力された音声ファイルはこちらから確認できます。
日本語だとなぜか外国人訛りがありますが、とてもリアルで聞きやすい音声となっています。
英語の場合は、実際に人がしゃべっているのとほぼ区別がつかないレベルです。
まとめ
今回は、OpenAIのText to speechを使って、テキストの読み上げをしてもらいました。
これまでも文章の読み上げ機能は多くありますが、ここまで自然な音声を作ってくれるサービスはこれまでなかった気がします。
ここまで聞き取りやすい音声が出力できるとなると、Youtubeでのナレーション、Podcastの作成・・英語の勉強など、いろんな用途で利用ができそうですので、どんどん使っていきたいですね!