概要
KaggleやSIGNATE等のデータ分析コンペに挑戦する際、分析課題と背景を読み込んだ後、まずはcsv等をぱぱっと可視化してデータの全体像を把握することから始めると思います (探索的データ分析ともいいます)。
Pythonでいうと、df.info()で欠損値やデータ型を確認して、df.describe()で要約統計量を確認して…という流れですね。
そこをもっともっと効率化したい。ただ、統計ソフトは持っていない。
そこで、そのような「データの簡単な可視化」を行えるWEBアプリを試作してみました。
DEMO
こちらからアクセス可能です。
要件定義 (ざっくり)
今回作成するアプリは、業務で使う本格的な統計アプリではなく、あくまでデータの一次確認用のアプリとして位置付けます。
試作版リリースにあたり、最低限必要な機能を列挙してみます。
- csvを読み込めること
- データのサンプルサイズ、カラム数が分かること
- 各カラムの欠損値の個数が分かること
- 各カラムの要約統計量 (平均値、中央値、四分位数)が分かること
- 各カラムのデータ分布がヒストグラムで表示されること
- カテゴリ変数については、その割合が円グラフで表示されること
- 相関係数が分かり、ヒートマップとして表示されること
- 簡単な重回帰分析と、その予測精度が分かること
おおよそこれくらいでしょうか。
今回はこれらの機能を、WEBアプリの作成にも使えるpythonを使って実装していきます。
技術選定
要件定義で列挙した機能であれば、SPA (Single Page Application)が最も使いやすそうです。
(何しろ、素早く簡単にデータの中身を確認したい、というのが最初にして最大のモチベーションでしたからね)
今回は作成工数を1日以内を目標として、streamlitを使用することとしました。1
また、グラフ描画はPlotly、重回帰分析は一般的に使用されているstatsmodels.apiを使用します。2
streamlit, plotlyに関する詳細な説明は、他にもたくさん記事がありますので、そちらをご参照くださいませ。
基本設計 (画面レイアウト)
SPAなので、Google Slideでサクッとレイアウトを検討します。
本来であればsidebarの幅、それぞれの項目の高さ、幅など細かく設計していくべきなのですが、今回はstreamlitを使用するため割愛しました。
(streamlitはこのあたりを割愛して機能開発に集中できるのが良いところです)
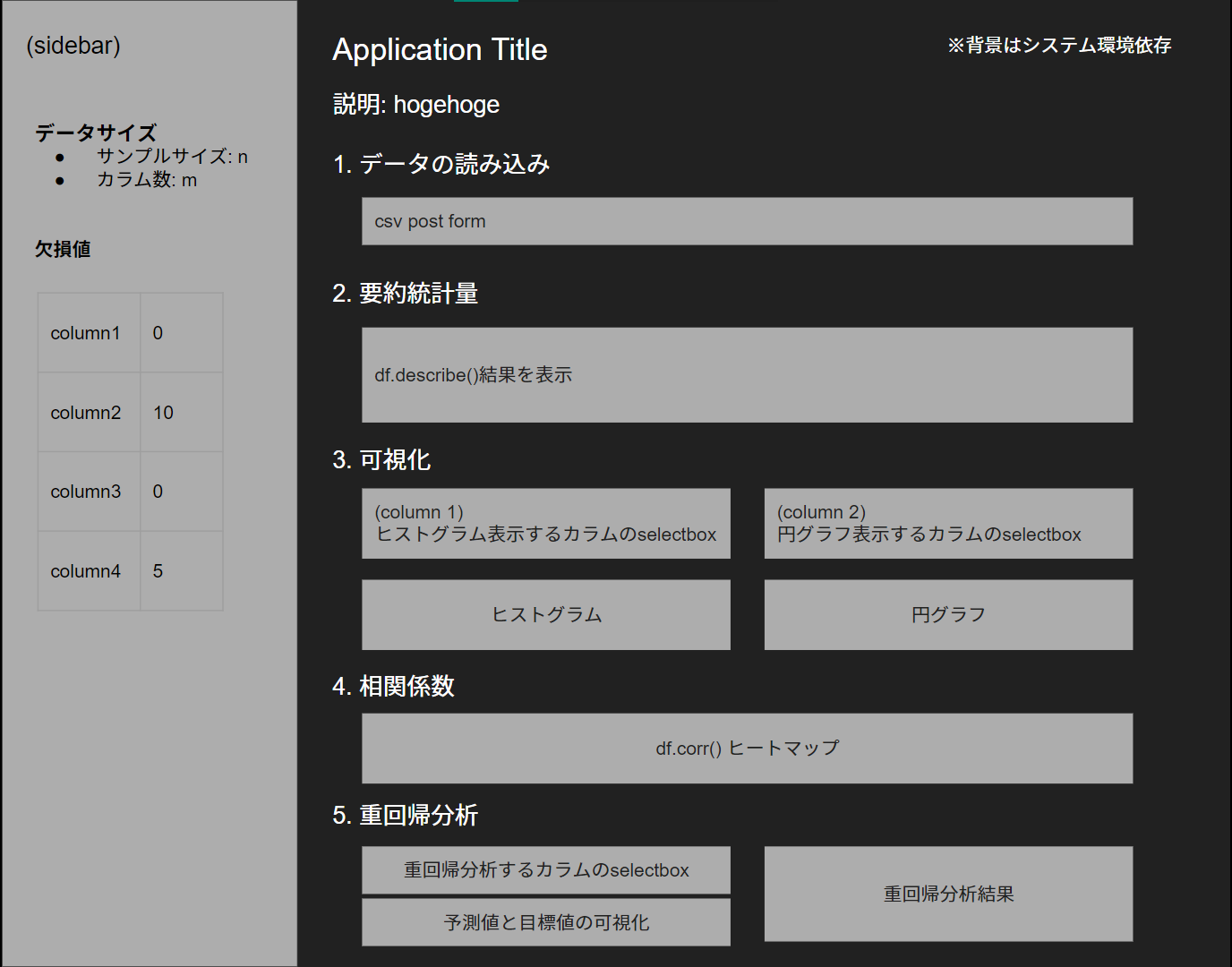
個人制作なので詳細設計は省きます。
実装
ページ全体のレイアウトを実装
- paddingは、
st.write("#")で実装しています。
(<h1>タグの文字列を空にして、h1分のスペースだけ空ける。) - 途中でエラーを吐いてページレンダリングが止まると困るので、try, exceptで例外処理をしておきます。
# ページタイトルと表示設定
st.set_page_config(page_title="basic statistics app", layout="wide")
st.title("Basic Statistics App")
st.write("#")
# 1. データを読み込む
st.subheader("1. データをアップロードする")
try:
# 2. 要約統計量の確認
st.write("#")
st.subheader("2. 要約統計量の確認")
st.sidebar.write("# データサンプルサイズ")
# 3. 各データの分布/割合を確認
st.write("#")
st.subheader("3. 各データの分布を確認")
# 4. 相関係数の表示
st.write("#")
st.subheader("4. 相関係数")
# 5. 重回帰分析
st.write("#")
st.subheader("5. 重回帰分析")
except:
st.error(
"""
エラーが発生しました。
"""
)
1. データのアップロード
streamlitの場合は下記コードでcsvアップロード/データフレーム表示します。
uploaded_file=st.file_uploader("csvファイルをアップロードしてください。", type='csv')
if uploaded_file is not None:
df = pd.read_csv(uploaded_file)
# データサンプルの表示
st.dataframe(df.head(5))
2. 要約統計量の表示
- データフレームを表示する際には、
st.dataframeがおすすめです。表内の値が検索できるなど、インタラクティブなテーブルとして表示されます。(st.tableでもデータフレームは表示できるのですが、インタラクティブではありません。)
# 2. 要約統計量の確認
st.write("#")
st.subheader("2. 要約統計量の確認")
if uploaded_file is not None:
# サイドバーの設定
st.sidebar.write("# 基本情報")
st.sidebar.write(f"### サンプルサイズ: {df.shape[0]}")
st.sidebar.write(f"### カラム数 : {df.shape[1]}")
st.sidebar.write("##")
st.sidebar.write("### 欠損値")
st.sidebar.write("各カラムの欠損値")
# 欠損値の表示
null_df = pd.DataFrame(df.isnull().sum(), columns=["null"])
st.sidebar.dataframe(null_df)
# TODO: 欠損値をどう埋めるか?を処理できるようにする。
# 要約統計量の表示
st.write("###")
st.write("##### 要約統計量 (数値データのみ)")
# TODO: カテゴリ変数に対応したいが、時系列データはdescribeでエラーをはくので、要改善
# st.write(df.describe())
st.dataframe(df.describe())
3. データの可視化
# 3. 各データの分布/割合を確認
st.write("#")
st.subheader("3. 各データの分布を確認")
if uploaded_file is not None:
# ページカラムを2つに分割
left_column, right_column = st.columns(2)
# カラム数が10を超えるとグラフ化に時間を要してしまうので、グラフ化するカラムを初期値10までに制限
left_column.write("##### 分布の確認")
cols_list = list(df.columns)
options_hist = left_column.multiselect(
'ヒストグラムで表示するカラムを選択 (初期値は最初の10カラム)',
cols_list,
cols_list[:10])
## 検証開始
if len(options_hist) > 0:
rows = int(math.ceil(len(options_hist) / GRAPH_COLS))
# グラフ描画エリアの設定
fig = make_subplots(
rows=rows, cols=GRAPH_COLS,
subplot_titles=options_hist
)
# n行5列でグラフを描画
for n, option in enumerate(options_hist):
row = int(n // GRAPH_COLS) + 1
col = int(n % GRAPH_COLS) + 1
fig.add_trace(
go.Histogram(x=df[option], name=option),
row=row, col=col
)
if col == 1:
fig.update_yaxes(title_text="counts", row=row, col=col)
# グラフエリアの縦横長とgapの設定
fig.update_layout(bargap=0.2)
left_column.plotly_chart(fig, use_container_width=True)
4. 相関係数 (ヒートマップ)の表示
st.write("#")
st.subheader("4. 相関係数")
if uploaded_file is not None:
fig = px.imshow(df.corr(), text_auto=True)
st.plotly_chart(fig, use_container_width=True)
5. 重回帰分析
-
df.describe()や(OLSの)result.summary()を実行して表示される結果については、st.text()を使うときれいに表示されて便利です。
st.write("#")
st.subheader("5. 重回帰分析")
if uploaded_file is not None:
scaler = StandardScaler()
cols_x = list(df.columns)
left_column, right_column = st.columns(2)
options_multi_reg = left_column.multiselect(
'説明変数を選択してください。',
cols_x,
cols_x
)
option_target = left_column.selectbox(
'目的変数を選択してください。',
cols_x
)
if len(options_multi_reg) > 0 and (left_column.button("重回帰分析 開始")):
# left_column.write("分析を開始しました。")
x = df[options_multi_reg]
y = df[option_target]
x_scaled = scaler.fit_transform(x)
multi_OLS = sm.OLS(y, sm.add_constant(x_scaled))
result = multi_OLS.fit()
left_column.write("分析が終了しました。結果を表示します。")
right_column.text(result.summary())
left_column.write(f"自由度調整済決定係数は{result.rsquared_adj:.2f}でした。")
pred = result.predict(sm.add_constant(x_scaled))
num = list(range(0, len(x)))
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=num, y=y,
mode='markers',
name='target'))
fig.add_trace(go.Scatter(x=num, y=pred,
mode='markers',
name='prediction'))
fig.update_xaxes(title_text="Sample No.")
fig.update_yaxes(title_text="Target / Prediction Value")
left_column.plotly_chart(fig, use_container_width=True)
以上で実装は完了です。
検証
数種類のcsv (カテゴリ変数を含んでいたり、大容量だったり)を準備して、アップロードから可視化/重回帰分析が問題なく行えるか確認します。
すべてのcsvに対して問題なく分析が行えることを確認し、完成です。
今後の予定
正直、まだ試作段階なので機能が全く充実していません。
自分自身でも何回か使っていて、欲しいなと思う機能が複数あったので、引き続き機能追加していきたいと思います。
P.S.
Dashにも挑戦してみたい。