pythonを用いたExcel作成プログラムの可読性について
議論したいこと
後述するプログラムの可読性、記法、処理についてアドバイス等があればお伺いしたい
どうにかこうにかマクロ代わりのプログラムが完成し、それっぽい出力ができる形にはなったものの、周囲にチェックできる人がいないため、出来栄えが分からない・・・。
仕様
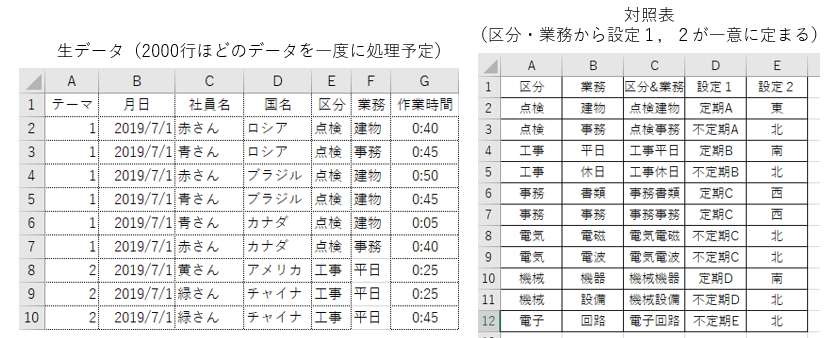
基本要求は「生データに対してプログラムを実行したら整理済みエクセル、グラフ付き表、カレンダーの3つが出力される」事。
対照表と、グラフ付き表のフォーマットは事前準備済み。
注記:(現時点でカレンダーはデータ抜き取りのみ実装)
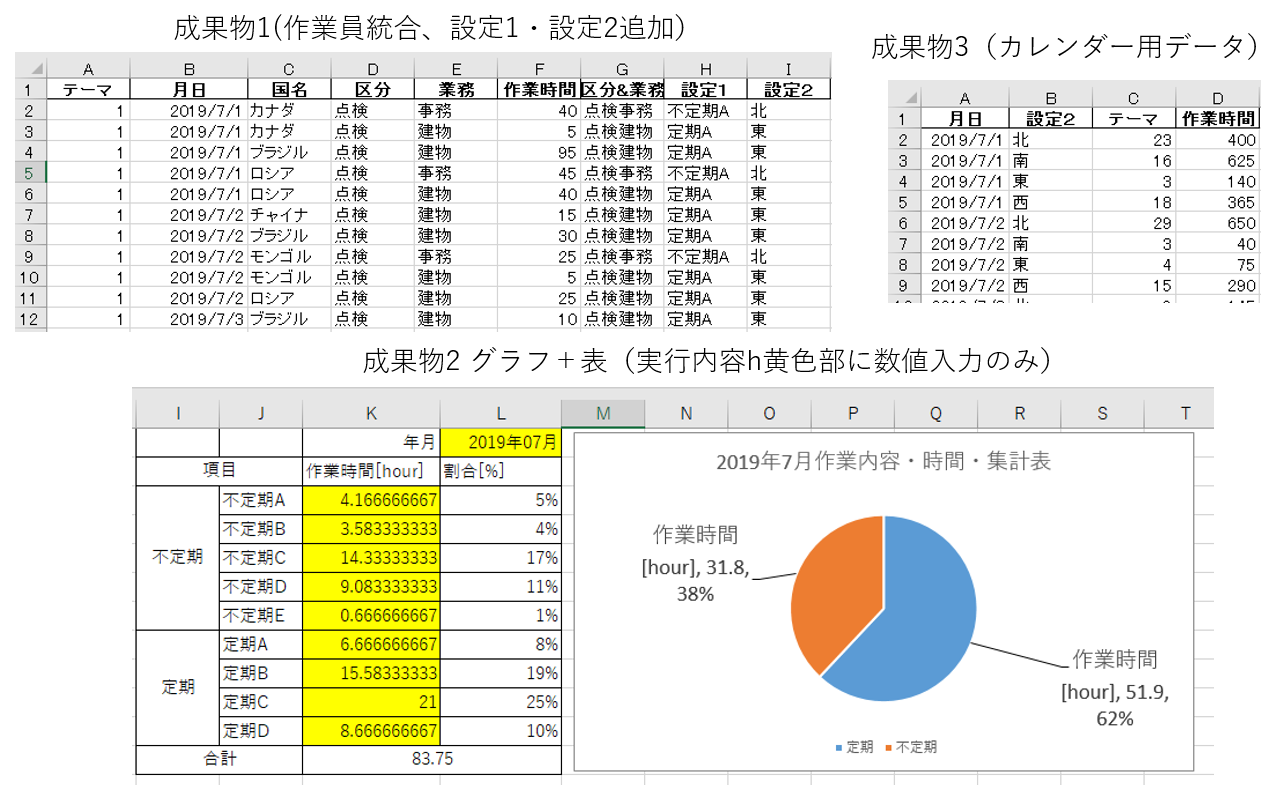
現時点での入出力は下図のようになっている(生データ・成果物1・成果物3は抜粋したデータ)。
(使ったxlsxファイルを共有する上手い方法が思いつかず。良策あればご教示いただきたく)
現行品のソースコード
現行品
import openpyxl
import copy
import pandas as pd
datasheet_raw=pd.read_excel('/content/drive/My Drive/Colab Notebooks/rawdata.xlsx')
#まず、「対照表から設定1/設定2を与える+不要な作業員情報を統合する」処理後のエクセルを成果物1として保管する
datasheet_raw["作業時間"] = pd.to_datetime(datasheet_raw["作業時間"],format="%H:%M:%S")
datasheet_raw["作業時間"] = datasheet_raw["作業時間"].dt.minute #作業時間を文字列から数値[分]に変換
datasheet_raw=datasheet_raw.groupby(["テーマ","月日","国名","区分","業務"],as_index=False).sum()
#作業員の名前が不要なので集約する
table_master = pd.read_excel('/content/drive/My Drive/Colab Notebooks/table_master.xlsx')
datasheet_process = datasheet_raw.merge(table_master, on=['区分', '業務'], how='left')
#merge関数を使って対照表と生データを結合することで設定1・設定2を付与
datasheet_process.to_excel('/content/drive/My Drive/Colab Notebooks/output1.xlsx', index=False) #成果物1が完成
#グラフ生成用のエクセルに値を打ち込み、成果物2として保管する
databook_graph=openpyxl.load_workbook('/content/drive/My Drive/Colab Notebooks/graph_master.xlsx')
datasheet_graph=databook_graph.active
month_data = datasheet_process.iat[0,1].strftime("%Y年%m月")
#生データは毎月1日~月末のデータなので”月日”列からYYYY年M月のデータを適当に持ってくる
datasheet_graph.cell(1,12).value=month_data
setting1 = datasheet_process.groupby(["設定1"],as_index=False).sum()
setting1 = setting1.iloc[:,2]/60 #設定1ごとの作業時間を単位[hour]の9行1列データとして取り出す(設定1は9種類固定)
for i in range(1,10):
datasheet_graph.cell(i+2,11).value=setting1[i-1] #エクセルの3行11列から11行11列までsetting1[0]~[8]を代入
databook_graph.save('/content/drive/My Drive/Colab Notebooks/output2.xlsx') #完成したグラフ生成用エクセルを保管
#月日と設定2で集計したエクセルを成果物3として保管する(最終的にはこれからカレンダーを制作して完成となる)
datasheet_complete =datasheet_process.groupby(["月日","設定2"],as_index=False).sum()
datasheet_complete.to_excel('/content/drive/My Drive/Colab Notebooks/output3.xlsx', index=False)
0 likes