これまでの踏跡
目次
全体設計
数値変換と必要なリスト作り
問題と変数と目的関数
制約変数
solveの結果
考察と今後の課題
補足:プログラム全容
全体設計
1.エクセルを取り込んで入力データを取得する
2.各種定数(今回プログラム中のm,d,aに当たる部分)をdataframeからリスト化する
3.問題の定義
4.変数と目的関数、制約条件の設定
5.solve()で解く
6.変数とその中身をシフト表に変換する
7.エクセルデータとして保存する
1.7.については組み合わせ最適化の問題ではないため割愛
今回は勤務者の要望として下記の生データを使用した。ひとまずは簡単化のために夜勤忌避だけ入れている。
import openpyxl
import pandas as pd
import numpy as np
import pulp
df_raw=pd.DataFrame({
'日付': {0: 1, 1: 1, 2: 2, 3: 2, 4: 3, 5: 3, 6: 4, 7: 4, 8: 5, 9: 5, 10: 6, 11: 6, 12: 7},
'昼夜': {0: 0, 1: 1, 2: 0, 3: 1, 4: 0, 5: 1, 6: 0, 7: 1, 8: 0, 9: 1, 10: 0, 11: 1, 12: 0},
'必要人数': {0: 2, 1: 2, 2: 2, 3: 2, 4: 2, 5: 2, 6: 2, 7: 2, 8: 2, 9: 2, 10: 2, 11: 2, 12: 2},
1: {0: '', 1: '忌避', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '', 12: ''},
2: {0: '', 1: '忌避', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '', 12: ''},
3: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '忌避', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '', 12: ''},
4: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '忌避', 8: '', 9: '', 10: '', 11: '', 12: ''},
5: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '忌避', 12: ''},
6: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '忌避', 12: ''},
7: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '忌避', 8: '', 9: '', 10: '', 11: '', 12: ''},
8: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '忌避', 11: '', 12: ''}})
数値変換と必要なリスト作り
df_raw=df_raw.replace("昼",0).replace("夜",1)
list_member = df_raw.columns.values[3:] #[1 2 3 4 5 6 7 8]
list_day =list(set(df_raw["日付"])) #[1, 2, 3, 4, 5, 6, 7]
list_action = list(set(df_raw["昼夜"])) #[0,1]
df=df_raw.replace("忌避",1)
組み合わせ最適化というよりはpandasの内容である。
処理が面倒なので昼夜は01に変換。
list_memberは元ファイルの4列目以降のcolumnsを抜き取って作成。中身は[1 2 3 4 5 6 7 8]
list_dayはset関数を使って日付に含まれるデータから重複削除してユニークな値だけを抜き取る。中身は[1, 2, 3, 4, 5, 6, 7]
list_actionもdayと同様にset関数でユニーク値だけを抜き取る。中身は[0,1]
list_memberと他の2つのリストで若干表示が違い、list_memberはカンマなし、他はカンマありだが、作業に支障が出なかったので良しとする。
問題と変数と目的関数
# 問題の宣言
ShiftScheduling = pulp.LpProblem("ShiftScheduling", pulp.LpMinimize)
# 変数宣言
x = {}
for m in list_member:
for d in list_day:
for a in list_action:
x[m, d, a] = pulp.LpVariable("x({:},{:},{:})".format(m,d,a), 0, 1, pulp.LpInteger)
# 目的関数:毎日の参加人数を最小化する
ShiftScheduling += sum(x[m, d, a] for m in list_member for d in list_day for a in list_action),"Target"
問題と変数の宣言に対し、前回からの変更点は無し。
変数の数も変わらず8人7日2勤務の112個。
目的関数は変更あり。
前回は参考サイトを元に「特定の人員の参加回数を最小にする」というものにしていた。
しかし、シフト勤務では通常そのようなことはないため、**「全変数の合計値を最小化」**という形に変更。
この問題では、x(m,d,a)==1のとき、勤務者mがd日のa勤務で出勤、というカウントになる仕組みのため、全変数の最小化ということは、
「全シフトに2人ずつ参加する状態:目的関数=14シフト*2人=28」が理論上最小値であり、人件費が最も安い状態である。
※勤務者間の給与差はひとまず無視する
制約変数
# 条件1 全時間帯で最低2人が参加
for d in list_day:
for a in list_action:
ShiftScheduling += pulp.lpSum(x[m, d, a] for m in list_member) >= 2
# 条件2 #各勤務者は絶対に週3回は出勤する
for m in list_member:
ShiftScheduling += pulp.lpSum(x[m, d, a] for d in list_day for a in list_action) >= 3
# 条件3 夜勤の忌避要望に答える
list_A=[]
list_B=[]
for m in list_member:
df_NG=df[df[m]==1.0]
list_A = [m,df_NG["日付"].iloc[-1],df_NG["昼夜"].iloc[-1]]
list_B.append(list_A)
# 日付=1,昼夜=1,member=1のとき、忌避フラグが立っている。memberを1~8まで動かしながら、
# [日付列の値、昼夜列の値,memberの値]という形のリストを積み重ねていけば良い
for m,d,a in list_B:
ShiftScheduling += x[m, d, a] == 0, "Constraint_NG_{:}_{:}_{:}".format(m,d,a)
制約条件1:全時間帯で最低2人が参加
x(m,d,a)のdとaを固定した状態での全組み合わせの総和は「各シフトごとの出勤人数」を意味することになる。
なので、Σ>=2とすれば、「全時間帯で最低2人が参加」が表せる。
※今のところ、制約条件の名前をつける意義がよくわかっていないので、ひとまず名前は付けていない。
制約条件2:各勤務者は絶対に週3回は出勤する
条件1とは逆に、x(m,d,a)のmの部分を固定したときの全組み合わせの総和を取れば、それは「特定の勤務者の出勤回数」を意味するはず。
制約条件3:夜勤の忌避要望に答える
これについては参考にできる式があるわけではないので、ひとまず力技で実装した。
空のリスト2種ABを作る → dataframeから「勤務者」列の値がmかつセルの値が1(=忌避)の部分を抜き出す
→ この時、x(m,d,a)のmはfor文で固定されていて、d,aはdataframeの日付列・昼夜列の値を.iloc[-1]で取り出せば得られる
→ これにより夜勤忌避のときの(m,d,a)がlistとして完成する(list_A)
→ 同じ作業をmの全組み合わせで繰り返し、list_Aの内容を空のリストlist_Bに積み上げていけば、
「全ての夜勤忌避のmdaの組み合わせリスト」が完成する。
[[1, 1, 1], [2, 1, 1], [3, 3, 1], [4, 4, 1], [5, 6, 1], [6, 6, 1], [7, 4, 1], [8, 6, 0]]
後は、list_Bからm,d,aの組み合わせを取り出して、x(m,d,a)==0 とすれば、
「夜勤の忌避要望が出た日には出勤させない」という制約条件が組み込める。
ただし、この方法は「夜勤忌避を各自1回しか出せない」という前提でのもの。
夜勤忌避が2回あると成立しないので、もう少し練り込む必要がある。
solve()の結果
>>>results = ShiftScheduling.solve()
>>>print("optimality = {:}, target value = {:}".format(pulp.LpStatus[results], pulp.value(ShiftScheduling.objective)))
optimality = Optimal, target value = 28.0
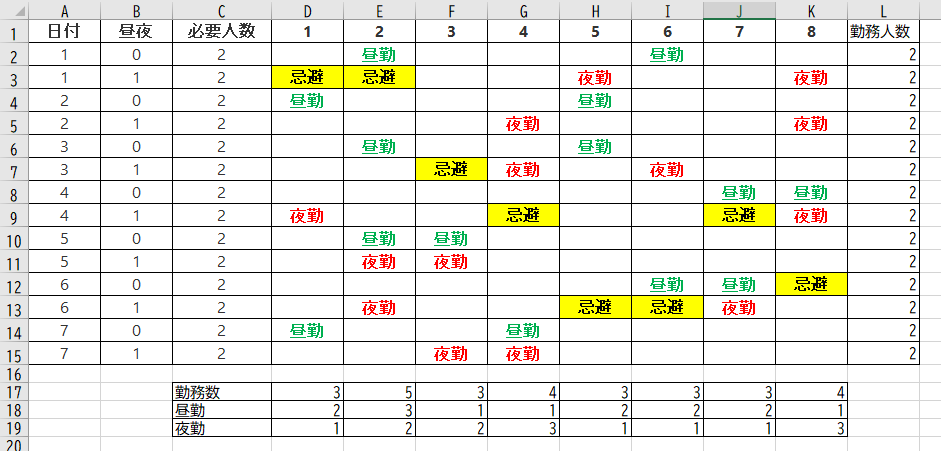
結果がこちら。計算は問題なく成功し、目的関数(全出勤回数)=28。
変数から表を再生成する機能は未実装なので、f文字列で出力した結果を手作業で打ち直した。
見て分かる通り、勤務者2の不満が爆発する計算結果となっている。
勤務者2だけ勤務5回は良い勤務シフトとは言えない。
また、昼勤と夜勤のバランスも悪く、昼1夜3の勤務者8と、昼2夜1の勤務者5の負担差も衝突を生みそうだ。
考察と今後の課題
必要となる追加仕様
・7日目の夜勤が不要であること
→これは、d,aの組み合わせをset()関数で個別に取り出しているから起きることなので、d-aを接続した状態で
取り出し、そこに存在する組み合わせをd,aとして使うようにすれば実現できる気がする
・変数から勤務表を再生成する機能
割と切実に必要である。
.variables()を使えばx(m,d,a)の値は取れるが、それをどうやってdataframeに戻すか、まだ良い方法が見つかっていない。
必要となる追加制約関数
・連続勤務は不可
→dとaの差を見れば、連続勤務の関係にあるかどうかは分かるはず。
例えばd=1,a=0とd=1,a=1は連続勤務になる。差はd-d=0,a-a=1。
同じくd=1,a=1とd=2,a=0は連続勤務、差はd-d=1,a-a=1。
しかしd=1,a=1とd=2,a=1は連続勤務ではない。差はd-d=1,a-a=0
よって、(d-d=0 & a-a=1) | (d-d=1 &a-a=1)となる全ての組み合わせを準備し、
mが同じ時は総和が1以下になるように制約すれば良いはず。
ただ、日数と人数が増えると計算量が莫大になりそうな気がする・・・。
・夜勤忌避は制約ではなく目的に合わせ込みたい
実際の勤務希望表では、夜勤忌避や有給希望など、多岐に渡る要望があるので、
全部を制約条件で必須にしてしまうと、勤務表は成立しない。
どこかで妥協が必要な条件、というのはむしろ目的関数に入れるべきと思われる。
・新人だけで勤務を埋めるのは不可
dataframe上に新人であることを表す値をどこかに入れる必要がある
新人フラグをnとして、m-nの組み合わせで縛るのが良いか?
7,8が新人で、n=1なら新人とした時に、[m,n]=[1,0][2,0]……[7,1][8,1]という感じで管理すれば、
後はd,a:固定でn=1の総和を取れば良いはず。
目的関数の変更
・合計勤務回数は少ないほうが良い
・勤務者の要望はなるべく多く聞ける方が良い
・勤務者間の業務負荷はなるべく均一な方が良い
これらの評価は、全て「なるべく叶えたい」というものであり、制約ではなく目的関数である。
ただ、pulpは目的関数を一つしか持てないので、この3つを全て評価できる評価式のようなものを準備し、
評価式を最小化することでより良い勤務シフトが組めるようになるはず
プログラム全容
import openpyxl
import pandas as pd
import numpy as np
import pulp
df_raw=pd.DataFrame({
'日付': {0: 1, 1: 1, 2: 2, 3: 2, 4: 3, 5: 3, 6: 4, 7: 4, 8: 5, 9: 5, 10: 6, 11: 6, 12: 7},
'昼夜': {0: 0, 1: 1, 2: 0, 3: 1, 4: 0, 5: 1, 6: 0, 7: 1, 8: 0, 9: 1, 10: 0, 11: 1, 12: 0},
'必要人数': {0: 2, 1: 2, 2: 2, 3: 2, 4: 2, 5: 2, 6: 2, 7: 2, 8: 2, 9: 2, 10: 2, 11: 2, 12: 2},
1: {0: '', 1: '忌避', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '', 12: ''},
2: {0: '', 1: '忌避', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '', 12: ''},
3: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '忌避', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '', 12: ''},
4: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '忌避', 8: '', 9: '', 10: '', 11: '', 12: ''},
5: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '忌避', 12: ''},
6: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '', 11: '忌避', 12: ''},
7: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '忌避', 8: '', 9: '', 10: '', 11: '', 12: ''},
8: {0: '', 1: '', 2: '', 3: '', 4: '', 5: '', 6: '', 7: '', 8: '', 9: '', 10: '忌避', 11: '', 12: ''}})
# 数値変換と必要なリスト作り
df_raw=df_raw.replace("昼",0).replace("夜",1)
list_member = df_raw.columns.values[3:]
list_day =list(set(df_raw["日付"]))
list_action = list(set(df_raw["昼夜"]))
df=df_raw.replace("忌避",1)
# 問題の宣言
ShiftScheduling = pulp.LpProblem("ShiftScheduling", pulp.LpMinimize)
# 変数宣言
x = {}
for m in list_member:
for d in list_day:
for a in list_action:
x[m, d, a] = pulp.LpVariable("x({:},{:},{:})".format(m,d,a), 0, 1, pulp.LpInteger)
# 目的関数
ShiftScheduling += sum(x[m, d, a] for m in list_member for d in list_day for a in list_action),"Target"
# 制約条件
for d in list_day:
for a in list_action:
ShiftScheduling += pulp.lpSum(x[m, d, a] for m in list_member) >= 2
for m in list_member:
ShiftScheduling += pulp.lpSum(x[m, d, a] for d in list_day for a in list_action) >= 3
list_A=[]
list_B=[]
for m in list_member:
df_NG=df[df[m]==1.0]
list_A = [m,df_NG["日付"].iloc[-1],df_NG["昼夜"].iloc[-1]]
list_B.append(list_A)
for m,d,a in list_B:
ShiftScheduling += x[m, d, a] == 0
# 出力
results = ShiftScheduling.solve()
print("optimality = {:}, target value = {:}".format(pulp.LpStatus[results], pulp.value(ShiftScheduling.objective)))
for v in ShiftScheduling.variables():
print(f"{v} = {pulp.value(v)}")
これをGoogle colaboratoryで動かせば動いた。