はじめに
OCRを用いて画像から文字認識を行う機能をラインボットに組み込み、ライン上のサービスとして使用できるようにします。
そもそも読むことが出来ない漢字は調べようがないので、テキストでもいいので文字情報を取得できればと思いました。
今回はOCRサービスとしてGoogle Vision API (以下Vision API)を利用し、Pythonを用いて作成します。その他以下のサービスを使用します
・LINEDeveloper
・Heroku
完成版はこちら

画像を送信すると、画像上の文字をテキスト形式で返します。あと、ローマ字で都市名を入力すると一日の天気も返してくれます。
※APIをリクエスト制限を超えていない場合は動きます。
構成
root/
├ main.py
├ gcpapi.py
├ config
│ └ GCPの認証(JSON)
├ runtime.txt
├ requirements.txt
├ Procifile
└ README.m
環境設定
ラインボットの作成及びherekuへの連動については、以下のページを参照
Pythonでline bot 作ってみた
Python初心者! -LINE Botでオウム返し編
Pythonのバージョンは以下の通りです
Python 3.9.0
使用するライブラリは以下の通り
Flask 1.1.2
google-cloud-vision 2.3.1
line-bot-sdk 1.19.0
requests 2.25.1
今回は、Vision APIの利用について説明します。
Vison API
Vison APIとはGoogle Cloud Platformが提供する機械学習サービスの1つで、以下の情報が取得できます
・画像に写っているさまざまなカテゴリの物体を検出(ラベル検出)
・画像内のテキストに対してテキストを検出、抽出
・画像内の顔検出
・画像に含まれる不適切なコンテンツを検出(セーフサーチ検出)
・画像に含まれる人工建造物を検出(ランドマーク検出)
画像があれば実際にサイト上でOCRを試すことが出来るみたいなので実際にやってみます
試した画像

結果
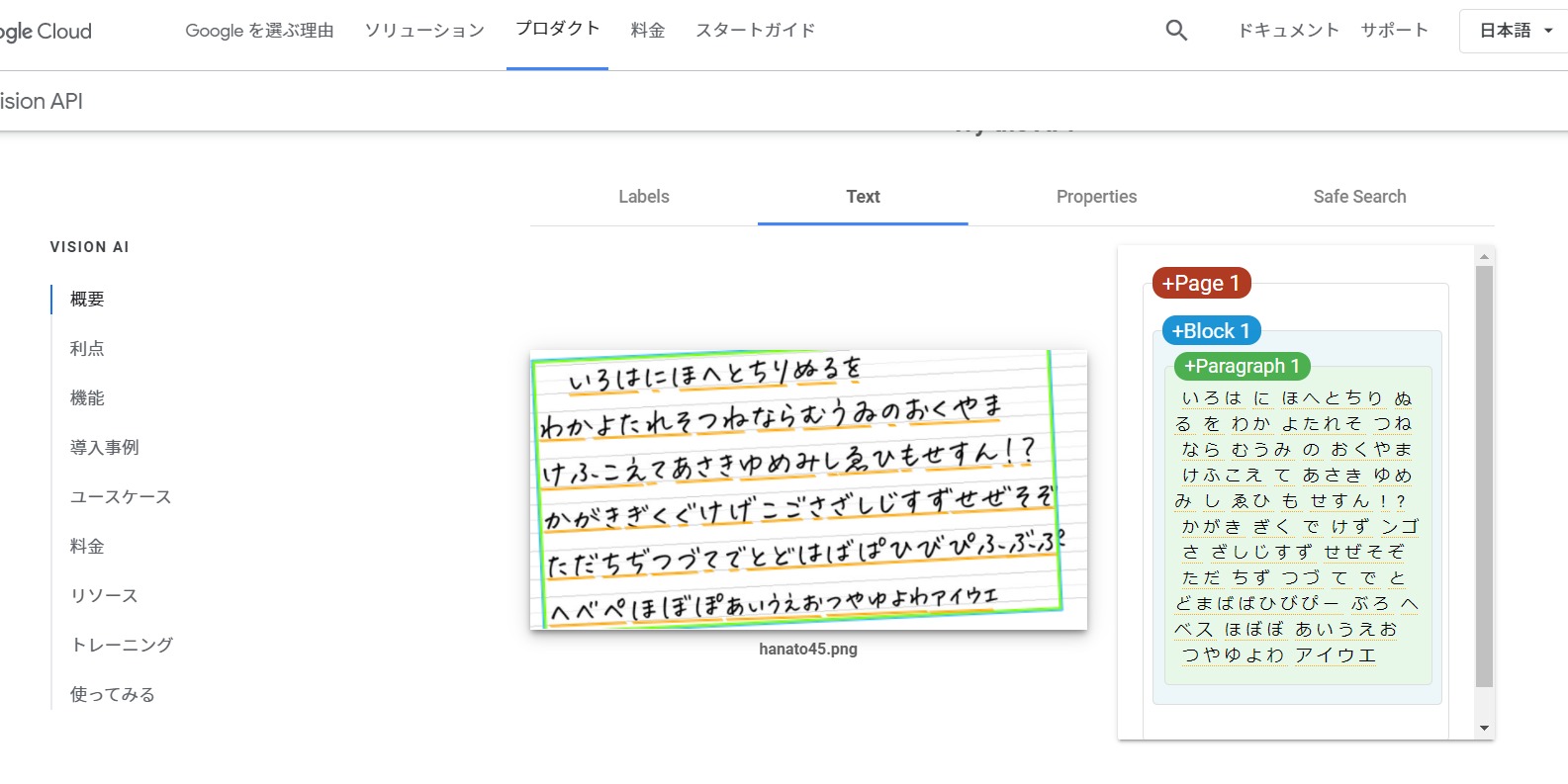
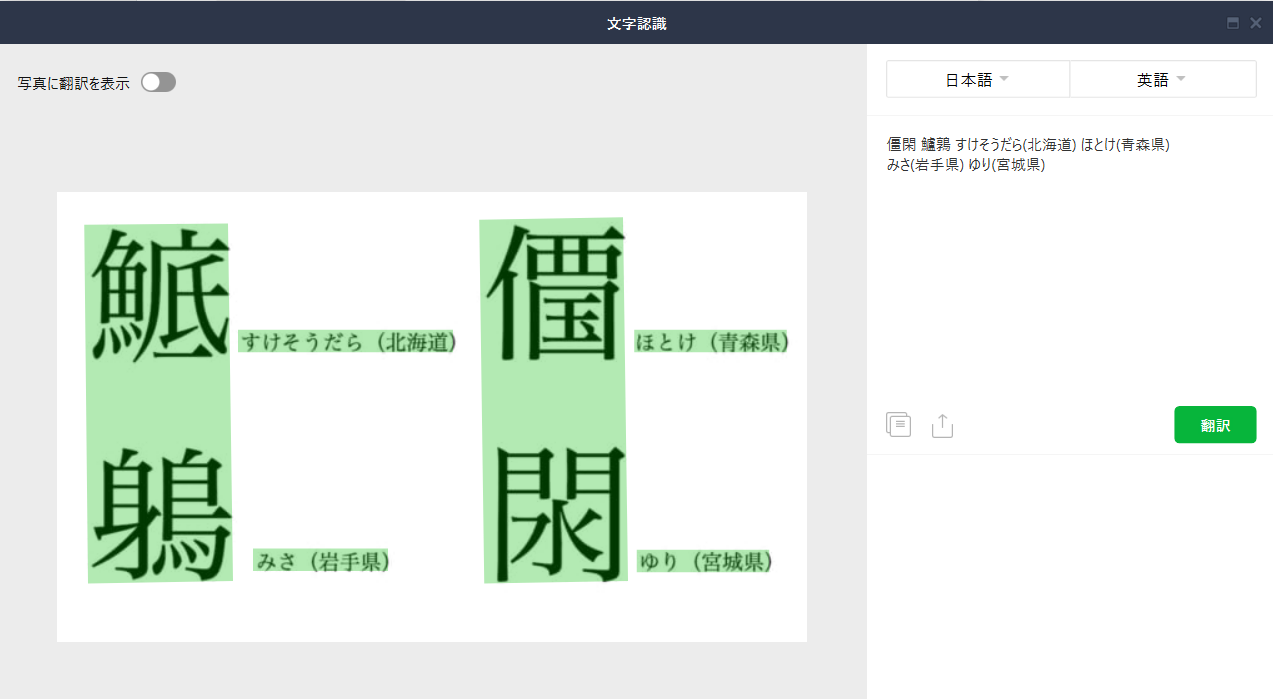
画像のテキストは大きな間違いはありませんでした。(いくつかご認識はありますが.....)
他にもラベルやロゴなどの情報も取得しているみたいです。
料金
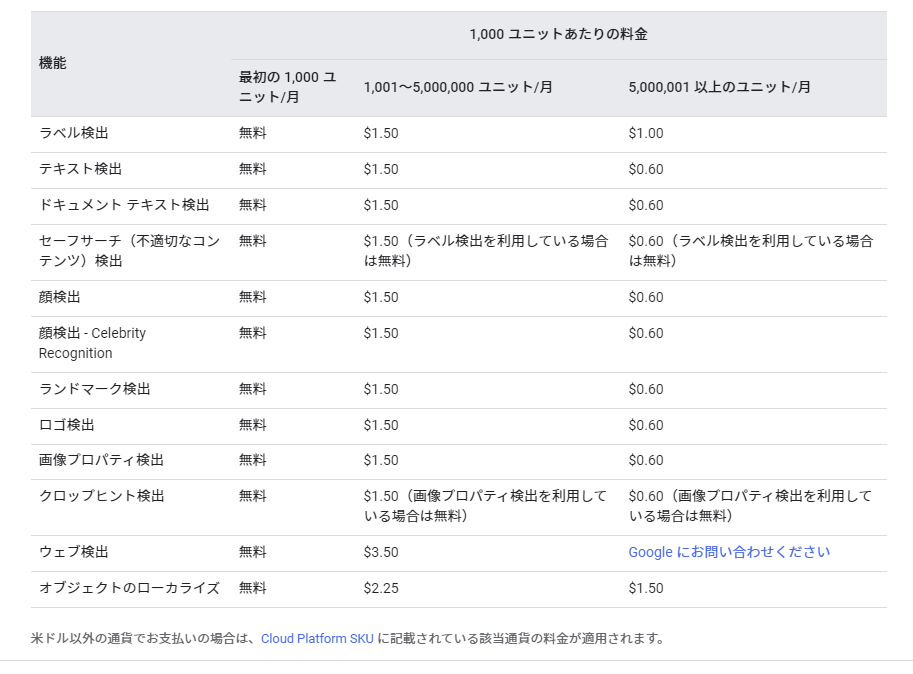
今回は無料枠なので1ヶ月で1000リクエストまで。
GCPへの登録
Vision APIを利用するためにはGCP(Google Cloud Platform)へ登録しないといけないみたいなので、さっそく登録します
AWSと同じで登録にクレカが必要です。ただ最初から自動従属課金制じゃないので膨大な請求がいきなり来ることはないかも???
認証情報の取得
Vision APIの登録まで完了すると、秘密鍵を含んだJSONファイルがダウンロードされます。ここまでの詳しい手順は以下の記事を参考にしました。
Google Cloud Vision APIのOCRを使ってPythonから文字認識する方法
文字認識
実際にこのレシートでAPIを飛ばしてみます
from pathlib import Path
from google.cloud import vision
p = Path(__file__).parent / 'image/test.png'#OCRに使用する画像ファイルのパス
client = vision.ImageAnnotatorClient()
with p.open('rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)#文字情報の取得
print(response.full_text_annotation.text)
はい、エラー頂きました
google.auth.exceptions.DefaultCredentialsError: Could not automatically determine credentials.
Please set GOOGLE_APPLICATION_CREDENTIALS or explicitly create credentials and re-run the application.
For more information, please see https://cloud.google.com/docs/authentication/getting-started
認証情報が設定されてないとの事。上記のエラーコードのURLに設定の説明があるのでそちらで設定方法を確認します。先ほど取得したJsonファイルのパスを設定するとのことです。
JSONファイルの設定方法
すべてJSONファイルへのパスを設定します。
MaCの場合
export GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"
Windows(PowerShell)の場合
$env:GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"
Windows(コマンドライン)の場合
set GOOGLE_APPLICATION_CREDENTIALS=KEY_PATH
設定したところでもう一回実行
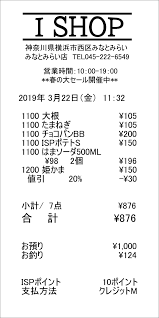
I SHOP
神奈川県横浜市西区みなとみらい
みなとみらい店 TEL045-222-6549
営業時間:10:00-19:00
*春の大セール開催中!
2013年3月22日(金) 11:32
1100 大根
・
・
・
・
10ポイント
クレジットM
一言一句違わずいけてました。
他にも特徴的な画像ファイルで試しましたが、体感では文字が入っている画像の正答率は90%程度でした。
また、まったく文字情報を含んでいない画像に対しては文字情報は帰ってきませんでした。
LINEbotへの組み込み
いざ、linebotに組み込みます!
APIの呼び出し部分
from google.cloud import vision
def image_to_text(imagecontent):
client = vision.ImageAnnotatorClient()
image = vision.Image(content=imagecontent)
response = client.document_text_detection(image=image)#文字情報の取得
return response.full_text_annotation.text
ライン上で画像を受けって返信する箇所
import gcpapi
# 省略
@handler.add(MessageEvent, message=ImageMessage)
def handle_image(event):
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)
res=gcpapi.image_to_text(message_content.content)#テキスト
try:
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=res))
except Exception as e:
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text="errorが発生しました"))
最後にherokuの環境変数の設定(json)を反映させる
heroku config:set GOOGLE_APPLICATION_CREDENTIALS='config/jsonファイル名'
herokuにも環境設定でファイルをパスでそのまま割り当ててもいい事を知らなくて1時間無駄にしました。
実装したサービス
実際に画像を送信してみます

結果(画像小さくて、すいません)
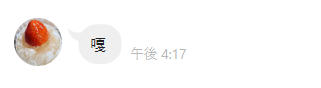
なんか違うくね.......
気を取り直して
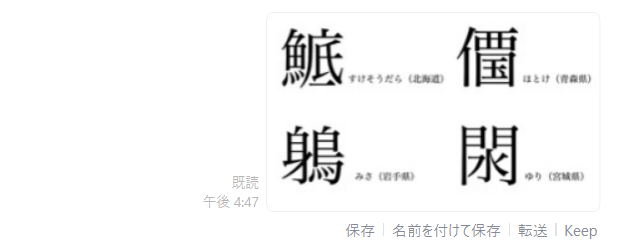
結果
漢字ってやっぱり判別が難しんですよね、分かります。
そもそも、画像の構成要素として漢字一文字を想定しておらず一つの文章単位で認識の対象にしているんですかね。どんな文字が来るか分からない上での、認識はこの程度が限界な気がします。漢字のみを対象としているサービスを探す方が正確なんですかね。
もう少し深堀っていく余地ありですが、簡単な文章では使えそうなので、これはこれで使っていきたいと思います。
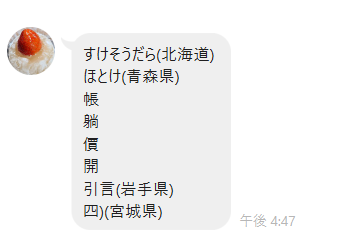
※余談ですがラインの文字認識のサービス結果も載せておきます(やっぱり漢字は難しんですね)