KaggleのTitanicで上位10%のスコアを出すことができたため、コードをメモしておきます。
スコア上昇のためにsklearn.ensemble.VotingClassifierを用いたアンサンブル学習を行いました。
ライブラリの読み込み
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
データの読み込み
pandas.dataframeを用いて、学習データ、テストデータ、提出データをデータフレームとして代入します。
train = pd.read_csv("/kaggle/input/titanic/train.csv")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
gender_submission = pd.read_csv("/kaggle/input/titanic/gender_submission.csv")
データの可視化
Survivedの可視化
seaborn.countplotを用います。
sns.countplot(x="Survived", data=train)
plt.show()
Survived、Pclass、Age、SibSp、Parch、Fareの関係の可視化
seaborn.pairplotを用います。
sns.pairplot(train[["Survived", "Pclass", "Age", "SibSp", "Parch", "Fare"]], hue="Survived")
plt.show()
Pclassの可視化
seaborn.countplotを用います。
sns.countplot(x="Pclass", hue="Survived", data=train)
plt.show()

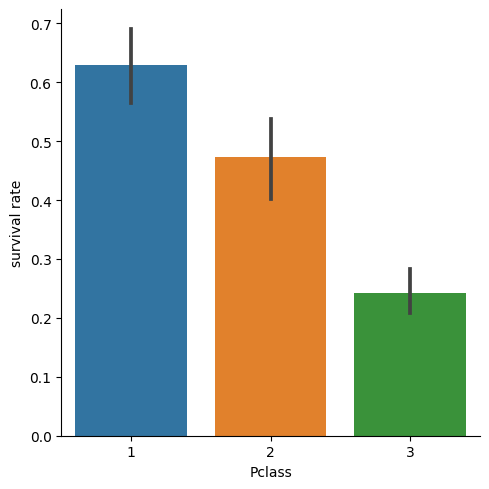
次に、seaborn.catplotを用います。
g = sns.catplot(x="Pclass",y="Survived", data=train, kind="bar")
g = g.set_ylabels("survival rate")
plt.show()
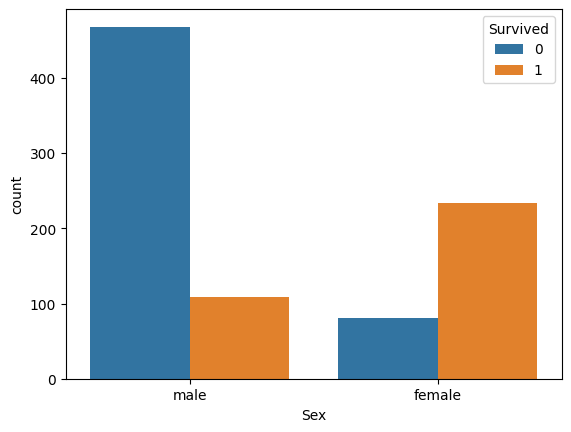
Sexの可視化
seaborn.countplotを用います。
sns.countplot(x="Sex", hue="Survived", data=train)
plt.show()
次に、seaborn.catplotを用います。
g = sns.catplot(x="Sex",y="Survived", data=train, kind="bar")
g = g.set_ylabels("survival rate")
plt.show()
Ageの可視化
seaborn.histplotを用います。
sns.histplot(data=train.dropna(subset=["Age"]), x="Age", hue="Survived", kde=True)
plt.show()
SibSpの可視化
seaborn.catplotを用います。
g = sns.catplot(x="SibSp",y="Survived", data=train, kind="bar")
g = g.set_ylabels("survival rate")
plt.show()
Parchの可視化
seaborn.catplotを用います。
g = sns.catplot(x="Parch",y="Survived", data=train, kind="bar")
g = g.set_ylabels("survival rate")
plt.show()
SibSp + Parchの可視化
seaborn.catplotを用います。
train["TotalFamily"] = train["SibSp"] + train["Parch"]
g = sns.catplot(x="TotalFamily", y="Survived", data=train, kind="bar")
g.set_ylabels("Survival rate")
plt.show()

Fareの可視化
seaborn.histplotを用います。
sns.histplot(data=train.dropna(subset=["Fare"]), x="Fare", hue="Survived", kde=True)
plt.show()

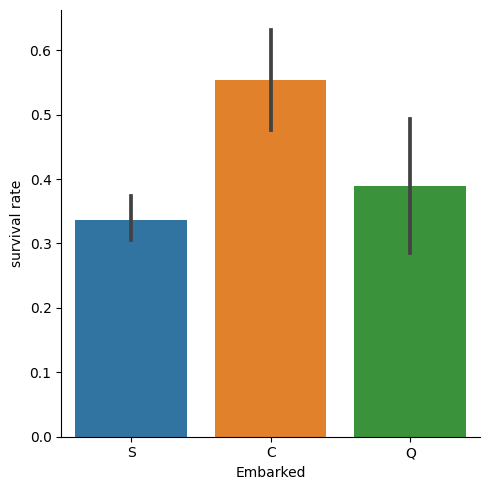
Embarkedの可視化
seaborn.catplotを用います。
g = sns.catplot(x="Embarked",y="Survived", data=train, kind="bar")
g = g.set_ylabels("survival rate")
plt.show()
データ前処理
データの読み込み
train = pd.read_csv("/kaggle/input/titanic/train.csv")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
gender_submission = pd.read_csv("/kaggle/input/titanic/gender_submission.csv")
trainとtestの連結
pandas.concatを用いて、データフレームを結合します。
data = pd.concat([train, test], sort=False)
欠損値の確認
pandas.isnull、pandas.DataFrame.sumを用いて、欠損値をカウントします。
data.isnull().sum()
ラベルエンコーディングと欠損値の補完
Sex
ラベルエンコーディングにはsklearn.preprocessing.LabelEncoderを用います。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['Sex'] = le.fit_transform(data['Sex'])
data.head()
femaleが0、maleが1となりました。
Age
欠損値を中央値で置換します。
data['Age'].fillna(data['Age'].median(), inplace=True)
Fare
欠損値を平均値で置換します。
data['Fare'].fillna(np.mean(data['Fare']), inplace=True)
Embarked
pandas.DataFrame.fillnaを用いて欠損値をSで置換した後、ラベルエンコーディングを行います。
data['Embarked'].fillna(('S'), inplace=True)
data['Embarked'] = le.fit_transform(data['Embarked'])
data.head()
Cが0、Qが1、Sが2となりました。
TotalFamily (SibSp + Parch)の作成
data["TotalFamily"] = data["SibSp"] + data["Parch"]
Name、PassengerId、Ticket、Cabinの削除
データ分析に用いない列、Name、PassengerId、Ticket、Cabinを削除します。
delete_columns = ['Name', 'PassengerId', 'Ticket', 'Cabin']
data.drop(delete_columns, axis=1, inplace=True)
学習データとテストデータの抽出
train = data[:len(train)]
test = data[len(train):]
y_train = train['Survived']
X_train = train.drop('Survived', axis = 1)
X_test = test.drop('Survived', axis = 1)
学習
RandomForestClassifier、GradientBoostingClassifier、KNeighborsClassifier、SVC、VotingClassifierを用いて、学習を行います。
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, VotingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
clf_rf = RandomForestClassifier(max_depth=2, random_state=0)
clf_gb = GradientBoostingClassifier()
clf_knn = KNeighborsClassifier()
clf_svc = make_pipeline(StandardScaler(), SVC(probability=True))
ensemble_clf = VotingClassifier(estimators=[('rf', clf_rf), ('gb', clf_gb), ('knn', clf_knn), ('svc', clf_svc)], voting='soft')
ensemble_clf.fit(X_train, y_train)
予測を行い、予測結果を表示します。
y_pred = ensemble_clf.predict(X_test)
y_pred[:10]
array([0., 0., 0., 0., 0., 0., 0., 0., 1., 0.])
スコアを表示します。
ensemble_clf.score(X_train, y_train)
スコアは0.8821548821548821でした。
データの出力
提出データをsubmission.csvとして出力します。
sub = gender_submission
sub['Survived'] = list(map(int, y_pred))
sub.to_csv("submission.csv", index=False)
提出した結果と順位を以下に示します。

15994人中1508位(2024年1月7日現在)と、上位10%のスコアを出すことができました。
もう一度同じコードで提出してみました。

スコアが0.79425に上昇し、16104人中1276位(2024年1月9日現在)と、上位8%のスコアを出すことができました。
アンサンブル学習によりスコアが上昇することを実感しました。
他のコンペにもアンサンブル学習を用いて挑戦したいです。
参考文献
https://qiita.com/upura/items/3c10ff6fed4e7c3d70f0
https://www.kaggle.com/code/sishihara/upura-kaggle-tutorial-01-first-submission
https://ct-innovation01.xyz/DL-Freetime/kaggle-003/
https://qiita.com/kunishou/items/bd5fad9a334f4f5be51c