こちらは「Qiita Engineer Festa 2023 で開催中の
「 新しくなったSkyWayを使ってみよう!」への投稿記事となります。
はじめは簡単なチャットアプリを作ろうと触り始めましたが すぐできてしまったので、
色々機能を足していたらなんだか不思議なアプリができました。
作ったもの
実装方法やSkyWayの使い勝手の話をする前にどんなものを作ったのか
↓これです↓
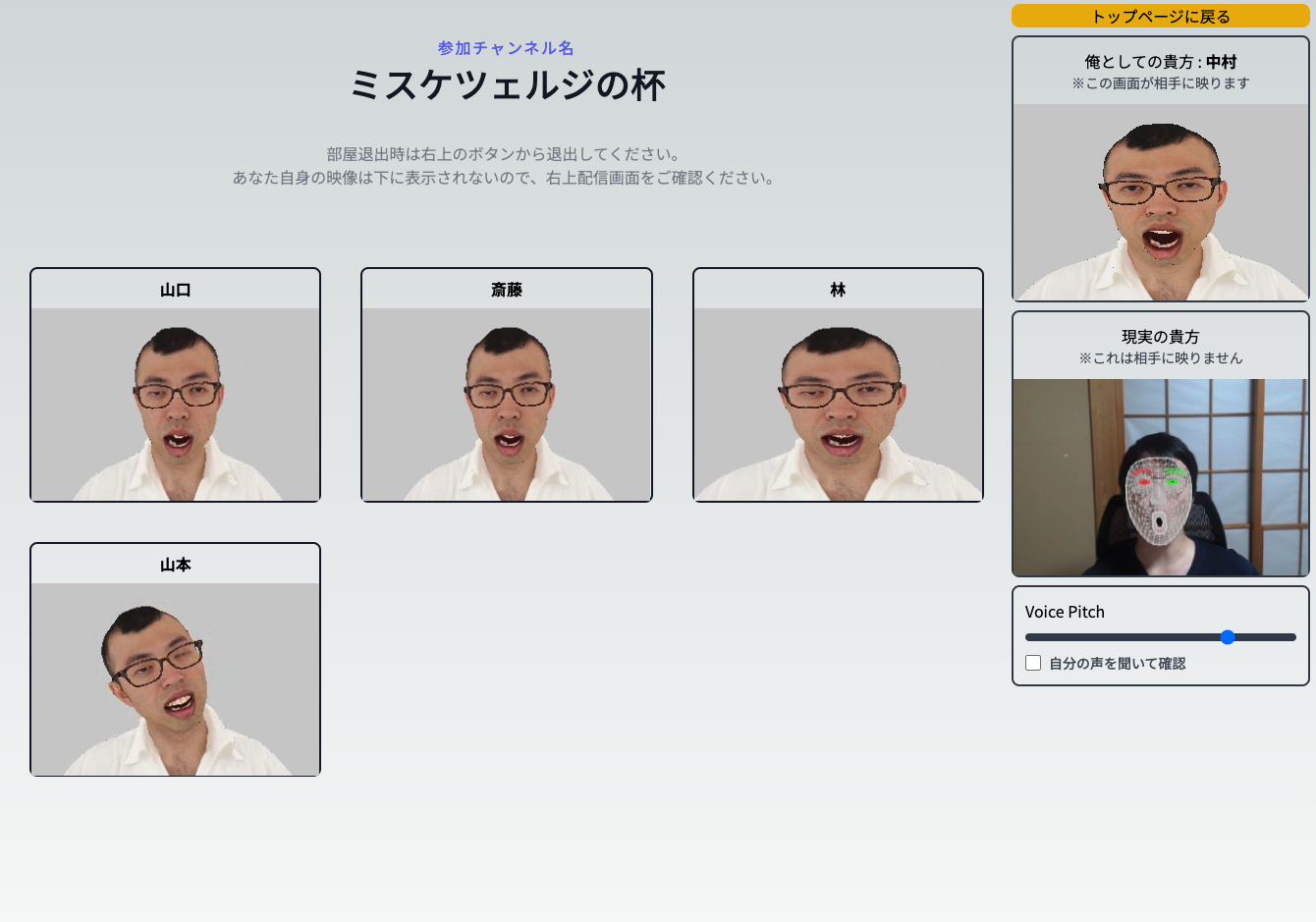
🤔?
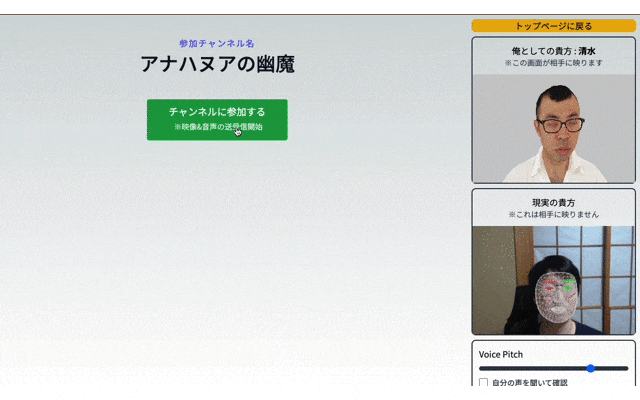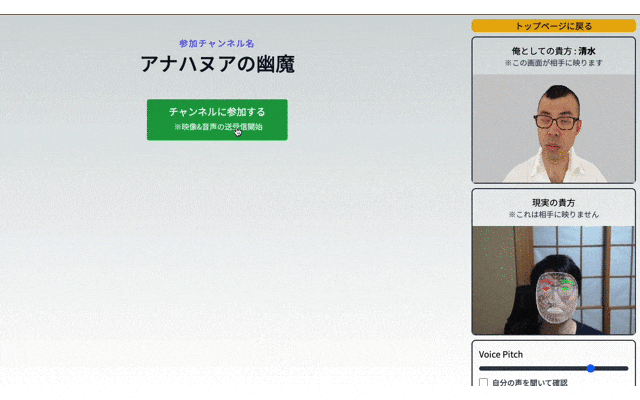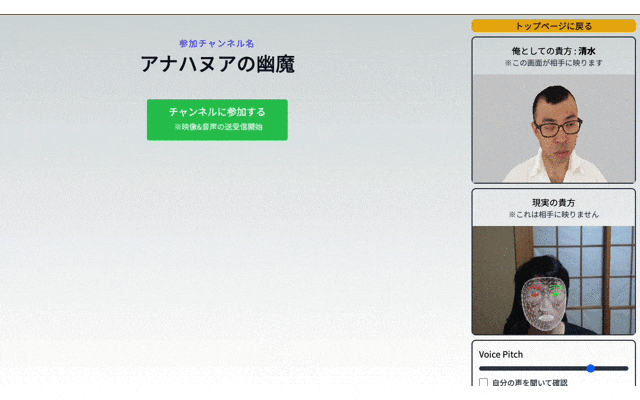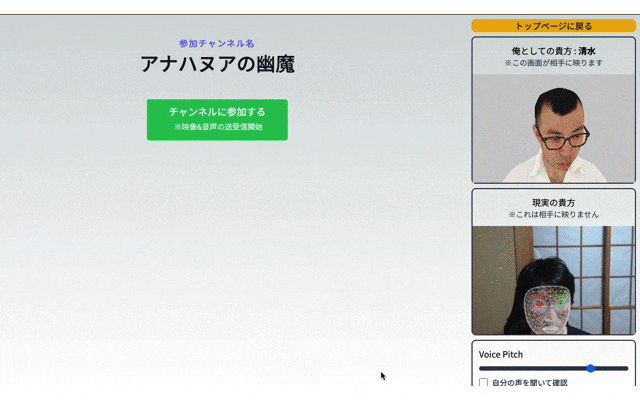
......
...
チャットルームに参加すると全員もれなく ジョイマン高木さん になります。
また声のピッチも上下できるので個人特定を著しく困難にした新時代匿名会議ツールです。
画面遷移図としてはこちら↓
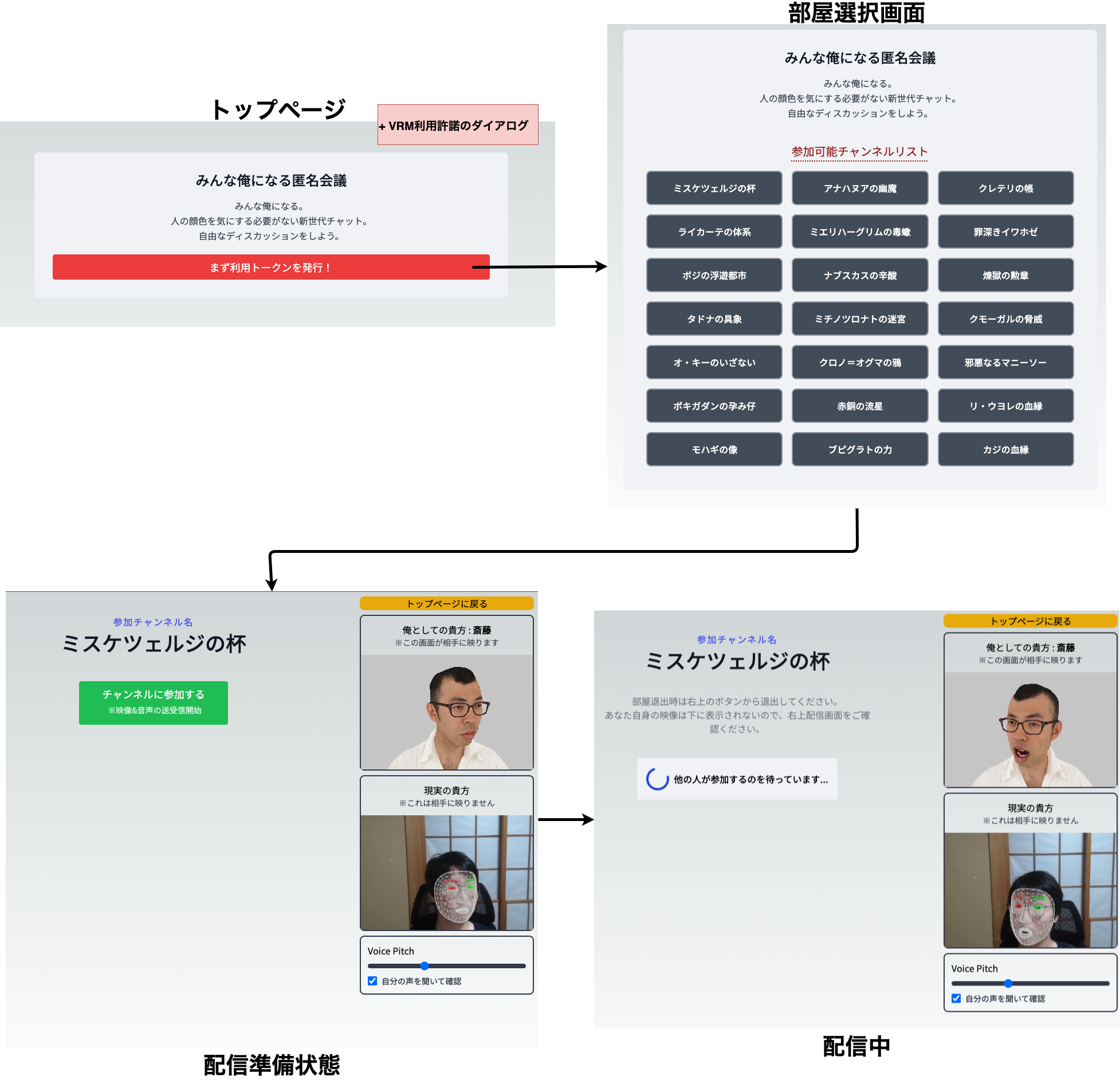
チャンネル名が中二病なのはカッコいいからです (ファンタジー用語メーカー利用)
PC版Chrome限定ではあるものの、ユーザーは特に準備することなく※1利用することができるのでお手軽ですね。
(複数デバイス対応までやるとレイアウト調整含めて大変になるのでそのへんは適当です。)
-
体験ページ (SkyWayの無料上限に到達したら使えないです)
- https://ore-chat.vercel.app/
- ID/PASS: qiita
- 追記) Netskopeなどを経由してアクセスしてる場合、配信が上手く行かない場合がありそうです
- 実装したコード全部
なぜ作った
以前テレビで 派遣ギャル会議なるもの を見て、面白いアイディアだと思ったのがきっかけです。
役職を隠し、敬語も禁止、そして名前も伏せる ことで誰しもが本音で話せる素敵空間を作り出す。
そんな空間を バーチャルでもできないかな? と思ったことと、
現代のツールとマシンを使えば意外と簡単にできるのでは? と思ってしまったからです。
そして最初は可愛いキャラ(VRM)にしようかと思ったんですが、
可愛い顔のアニメキャラから突然現実的で鋭い指摘をされたらトラウマになりそうだったので、
現実の人間 / 現実の表情モデルを採用しました。
規約が比較的自由で人間のモデルなんてあるか..? と思ってましたが
バーチャルジョイマン 高木 / VJ-TAKAGI という素晴らしいプロダクトを見つけたので今回利用させていただきました。
システム構成 & 実装
今回はSkyWayのSDKとして @skyway-sdk/coreを採用しています。
また他に@skyway-sdk/roomというのもあります。
Room (@skyway-sdk/room)
複数人で通信をするアプリケーションを作るための ライブラリ です。 通信方式を P2P と SFU の 2 種類から選択できます。
Core (@skyway-sdk/core)
SkyWay を使うために必要な基本的な要素(Channel, Member, Stream, ...)を提供する ライブラリ です。 Room SDK でカバーできないような、SkyWay によって提供される機能をより細かに制御し最大限に利用したいユースケースに向いています。
大きく違うのがRoomとChannelという概念かと思いましたが、Roomの方にもChannelという用語があり具体的な使い分けがちょっとわからなかったです。
(コメントでご指摘ください...。)
なので より細かに制御し最大限に利用したいユースケース と書いてあったCoreにしました。
ただ半分くらい実装してから気づいたんですが、、、、
botを追加して色々制御しないとCore側でSFU通信できなかい感じだったので
@skyway-sdk/room でも良かったかなと思ってます。
手軽に多人数接続したいということであれば @skyway-sdk/room で充分事足りると思います。
インフラ構成
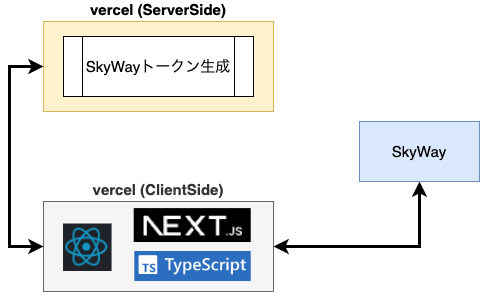
Vercel 完結になってます。
9.9割クライアント側で処理してますが、SkyWay認証用トークン作成のみサーバ側で処理してます。
クライアント ⇔ SkyWay間でほとんど処理が完結するので、
サーバでの通信量を気にしなくていいのも嬉しいポイント。
サーバ側も実装自体はシンプルにできました。(実装コード)
また各種シークレットキーはVercelのENVとして設定してユーザー露出は無いようになってます。
また配信のためのメディアPub/SubについてはすべてクラウドのSkyWayとSDKが処理してくれます。
内部の実装を知る必要や、別途サーバーを用意する必要ないのでWebRTC初心者でも触りやすいです。
アプリケーション実装
全体のデータの流れ概要図はこちら↓
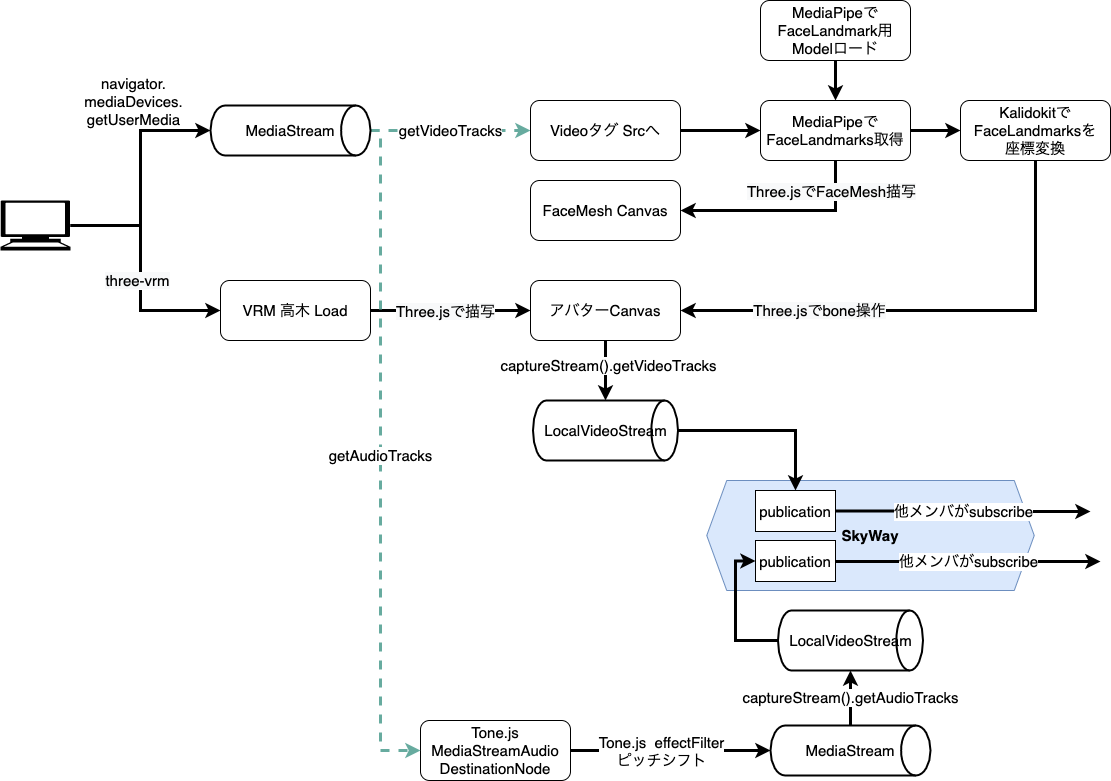
navigator.mediaDevices.getUserMediaを利用して
MediaStreamを掴んだ後にデータ加工をして、SkyWayへPublishしてる形になります。
一連の加工処理は全部クライアントで完結してるので、
負荷も抑えられ操作性も良くなっていると思われます。
上記のMediaStreamの流れを見ればわかるように、今回のデータ加工では映像と音声の2系統があります。
配信方法についてはAudioもVideoも差異はほぼなくSkyWayが吸収してくれてますが、
加工については結構面倒な事やってるので、 映像加工 音声加工 配信の3パートに分けて説明していきます。
映像加工
今回はカメラから入力された映像を加工したかったので 一旦Three.jsでCanvasに描画した後、再度MediaStreamを取得してSkyWayに流してます。
クライアントサイドで加工する実装はMyVideo Componentに集約してあります。
- 利用してる主要ライブラリ
-
MediaPipe
- 顔座標検知
-
Three.js
- Canvas描写 etc
-
@pixiv/three-vrm
- Three.jsでVRMを取り扱う
-
kalidokit
- 座標変換処理
- 既にdeprecatedでMediaPipeに統合
- ただLandmarkからの座標変換処理部分だけ使いたかったので部分的利用
-
MediaPipe
↓顔認識の主要箇所抜粋↓
// カメラからMediaStreamを取得した後
const mediaStream = await navigator.mediaDevices.getUserMedia({
audio: true,
video: {
width: CANVAS_SIZE.width,
height: CANVAS_SIZE.height,
},
});
// MediaPipeでFaceLandmark用モデルを初期化
// QuickStart
// └ https://developers.google.com/mediapipe/solutions/vision/face_landmarker/web_js
faceLandmarker = await FaceLandmarker.createFromOptions(vision, {
baseOptions: {
modelAssetPath: `https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task`,
delegate: "GPU",
},
numFaces: 1,
runningMode: "VIDEO",
});
// FaceLandmarkの結果をもとにMeshを自分の顔に上書き描写
// (...ロックマンXのシグマとかスターフォックスのボスを思い出す...)
// FaceLandmark構造
// └ https://storage.googleapis.com/mediapipe-assets/Model%20Card%20Blendshape%20V2.pdf
drawingUtils.drawConnectors(
landmarks,
FaceLandmarker.FACE_LANDMARKS_TESSELATION,
{ color: "#C0C0C070", ...commonDrawParams }
);
↓アバター初期化と表情反映処理の主要箇所抜粋↓
// VRMモデルをThree.jsで扱うためのパッケージとしてpixivが作ったnpmがあったので利用
// @pixiv/three-vrm
// └ https://github.com/pixiv/three-vrm
import { VRM, VRMLoaderPlugin } from "@pixiv/three-vrm";
// VRMロード
modelLoader.register((parser) => {
return new VRMLoaderPlugin(parser);
});
modelLoader.load(
"/vj_takagi.vrm",
(gltf) => {
loadedVrm = gltf.userData.vrm;
loadedVrm.scene.rotation.y = Math.PI;
loadedVrm.scene.scale.setScalar(50);
putArmStraightDown(loadedVrm);
threeScene.add(loadedVrm.scene);
const light = new THREE.PointLight(0xffffff);
light.position.set(2, 2, 2); // ライトの位置を設定
threeScene.add(light);
renderer.setSize(CANVAS_SIZE.width, CANVAS_SIZE.height);
renderer.render(threeScene, threeCamera);
},
(progress) =>
console.log(
"Loading model...",
100.0 * (progress.loaded / progress.total),
"%"
),
(error) => console.error(error)
);
// モデルのboneを操作して魂を注入
// VRM操作はlibにまとめましたのでそちらを見てもらったほうが確実
// └ https://github.com/TakeshiOnishi/OreChat/blob/main/lib/controlVRM.ts
const expressonManager = targetVrm.expressionManager;
// 「い」の口の形に適用
expressonManager.setValue('ih', Vector.lerp(faceResolve.mouth.shape.I, expressonManager.getValue('ih') || 0, 0.5));
// 左瞼を閉じる
expressonManager.setValue('blinkLeft', Vector.lerp(Utils.clamp(1 - faceResolve.eye.r, 0, 1), expressonManager.getValue('blinkLeft') || 0, 0.5));
// 初期ポーズが T なので腕を下ろす
targetVrm.humanoid.setRawPose({
'rightUpperArm' : {
rotation: [ 0.000, 0.000, -0.454, 0.891 ],
},
'leftUpperArm' : {
rotation: [ 0.000, 0.000, 0.454, 0.891 ],
},
})
音声加工
音声は映像ほど手を入れておらず、ピッチを上げ下げするだけの簡易的な実装になってます。
- ここで利用してる主要ライブラリとしては
- Tone.js
- 以上
ピッチ操作をした時にノイズが大きく感じましたが、
isseus見る感じ簡単に対応できそうもなかったので改善は断念。 (重要な箇所なのに...)
とりあえずSkyWayのNoiseSupressionだけ有効化。
↓音声加工主要処理↓
// 映像同様にマイクからMediaStream取得後分離
const mediaStream = await navigator.mediaDevices.getUserMedia({
audio: true,
....
});
// もとのAudiotrackを消して EffectをかけたAudioTrackを追加してMediaStreamへ
const micAudio = new Tone.UserMedia();
await micAudio.open();
const shifter = new Tone.PitchShift(myVoicePitch);
micAudio.connect(shifter);
setPitchShifter(shifter);
const effectedDest = Tone.context.createMediaStreamDestination();
shifter.connect(effectedDest);
const oldTrack = mediaStream.getAudioTracks()[0];
mediaStream.removeTrack(oldTrack);
const effectedTrack = effectedDest.stream.getAudioTracks()[0];
mediaStream.addTrack(effectedTrack);
audioRef.current!.srcObject = new MediaStream(mediaStream.getAudioTracks());
配信 (映像音声 送受信)
配信はSkyWayに任せっきりです。
下記コードが長いですが実際に送信してるのは
await mememe.publish(myVideoInputStream);だけです。
メンバー名に日本語を使うとエラーになったので、metadataに格納して日本語表示を実現してます。
ちなみに今回のサービスではFakerを利用して偽名生成してます。
↓配信主要箇所↓
// 偽名生成
import { faker } from '@faker-js/faker/locale/ja';
setMyName(faker.person.lastName());
// SkyWayを初期化してChannelに参加 (この時点では何も配信も受信もしていない)
const context = await SkyWayContext.Create(skywayToken);
myChannel = await SkyWayChannel.FindOrCreate(context, {
name: JA_CHANNEL_MAPPINGS[myChannelName],
metadata: myChannelName,
});
mememe = await myChannel.join({
metadata: myName,
});
// CanvasからVideoTrackを取得して LocalStreamに流し込んでpublish (これで配信)
// 音声も類似なので省略
const avatarCanvas = myVideoRef.current?.getElementsByClassName("refAvatarCanvas").item(0) as HTMLCanvasElement;
if (avatarCanvas) {
const myVideoInputStream: LocalVideoStream = new LocalVideoStream(
avatarCanvas.captureStream().getVideoTracks()[0]
);
await mememe.publish(myVideoInputStream);
toast(`映像配信が開始されました`, { icon: "🎥" });
} else {
toast.error(
"映像初期化に何かしらエラーが発生しました。\nページを更新等してお試しください。"
);
}
// 映像と音声を受信して、HTMLMEdiaElementにStreamを繋ぐ (ここで初めて映像音声受信)
const subscribeAndAttach = async (publication: Publication) => {
if (publication.publisher.id === mememe.id) return;
const { stream } = await mememe.subscribe<
RemoteAudioStream | RemoteVideoStream
>(publication.id);
let mediaElement;
const memberDiv = memberListRef.current?.getElementsByClassName(`member-${publication.publisher.id}`).item(0) as HTMLDivElement;
switch (stream.track.kind) {
case "video":
mediaElement = memberDiv.getElementsByTagName("video").item(0) as HTMLVideoElement;
break;
case "audio":
mediaElement = memberDiv.getElementsByTagName("audio").item(0) as HTMLAudioElement;
break;
default:
return;
}
stream.attach(mediaElement);
};
// 現在チャンネルにいるユーザを全部Subscribeしてから新規参加にもSubscribe対応
myChannel.publications.forEach(subscribeAndAttach);
myChannel.onStreamPublished.add((e) => subscribeAndAttach(e.publication));
他に補足とか
- Next.js v13を利用
- Basic認証はNext.js middleware
- Recoilで状態管理 (一部Stateを永続化)
- 映像送受信ComponentでDynamicImportsを利用
-
@skyway-sdk/core/dist/media/stream/local/media.jsにて -
error ReferenceError: RTCPeerConnection is not defined発生のため
-
感想
SkyWayで映像や音声を加工してみたエントリーはいくつかありましたが、
SkyWayの古いバージョンの記述が多く参考にできなかったものが多かったです。
そのため、これまでのSkyWay(以降、旧SkyWayと言います)との後方互換性がなく、旧SkyWayに関するこれまでのQiita記事は新SkyWayにはそのまま活用できません。
https://qiita.com/official-events/93564ad363199fa7999c
なので今回のケースのようにトリッキーな使い方をするときは少しだけ大変かもしれません。
ただ基本的な利用であればクイックスタートでサクッと実装できる印象を受けました。
この辺はある程度エントリーが増えたりすれば、より触りやすくなるだろうと思います。
今回のQiita Engineer Festへの協賛もその一環なので、
今後もこうしたキャンペーンとともにエントリーが増えそうな気もします。
また開発体験としてはTypeScriptのサポートがあったため非常に快適でした。
日本語も充実していたのは珍しくて驚き。
ここまでしっかりしてるとドキュメント見ないでもある程度予測で書けるので嬉しいポイント。
↓ NeoVim画面
細かいですが、サイトトップページのメニュー順も開発者寄りで気分が上がる。
リンク先のドキュメントページもかなり充実してたので、それ含めて開発はしやすかったです。

一つ要望があるとすれば、管理画面にあるデータ通信量を日別に見る機能があると良いと思いました。
月別の確認はできるのですが、日々の利用状況から月末利用予測したりピーク曜日を特定したり…… と色々安心して使えるようになるかなと思ったからです。
最後に...
業務領域がこの辺と全く絡んでこないので、大規模な利用時の料金試算などは見ていないです。
逆に憶測で適当なことは言えないので、他の人のエントリーを見ていただければと思います。
とはいえ、今回個人開発してみた時には非常に満足な体験をすることができました。
...出来上がってみれば、いつものようにネタアプリ感が否めないですが。
余談余白
- 会議中のしかめっ面には警告を出して一定時間無視すると部屋から追放とかも面白そう。
- 今回は破壊的変更が多くなってる技術が多かったのでmigrationガイド見るのが大変だった
- 初めて触るのが大半だったので、過去のやってみた系の記事が参考にできないパターンが多かった
- 今回の記事で使った技術の大半は普段私が使ってるものではなく不正確な箇所もあると思います。その際はコメントでご指摘くださると幸いです。
参考にした記事等
- SkyWayクイックスタート
- SkyWay認証認可実装サンプル
- バーチャルジョイマン 高木 / VJ-TAKAGI
- 【JavaScript】Web Speech APIで喋らせたものをイケボにしてWebRTCに流し込め…なかった話【失敗】
- SkyWayとTone.jsを使って、ボイスチェンジャー付きボイスチャットアプリを作る
- ファンタジー用語メーカー
注釈
- ※1: ジョイマン高木さんのVRMは
株式会社よしもとクリエイティブ・エージェンシーが提供している素材なので、利用する際はホームページにある規約を確認の上同意してご利用ください。- 今回のアプリは利用前に同意確認するダイアログがでてきます。