概要
GKEに用意されているノードの自動アップグレードは便利ですが、インスタンスの再起動を考慮していない構成・設定だとアプリケーションサービスが停止します。
解決している問題は少ないですがアプリケーションサービスが停止するケースと解決方法をまとめました。
環境
- Kubernetes(GKE): >= v1.6
アプリケーションサービスが停止するケース
Podの配置が偏っている
spec.replicas: 2のDeploymentをapplyすると、以下の図のように1つのインスタンスに偏るケースが発生します。
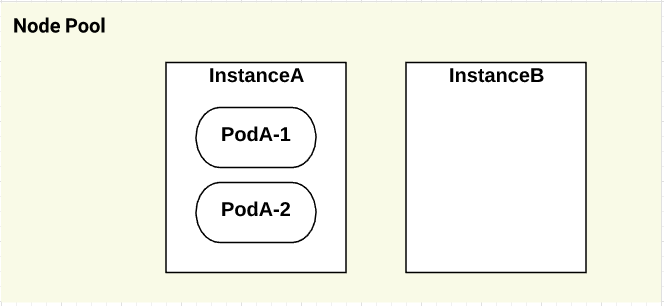
ノードのアップグレードは1台づつkubectl drainするため、PodAが同じタイミングでterminateされます。
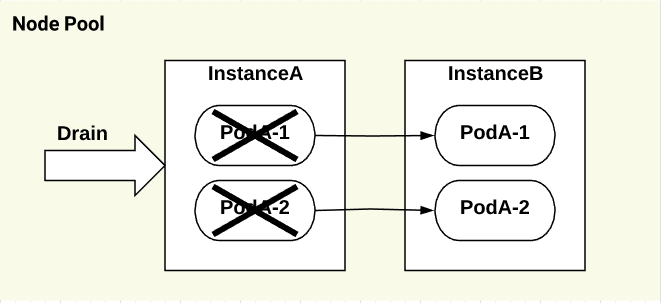
この状態になるとPodAと通信ができないので、アプリケーションサービスの停止につながります。
解決方法
-
PodDisruptionBudgetを設定する
-
kubectl drain実行時にmaxAvailableを設定することでPodの起動数を調整可能 -
minAvailableを利用する場合、spec.replicasの数値が小さいとALLOWED DISRUPTIONSの数値が0になるので注意
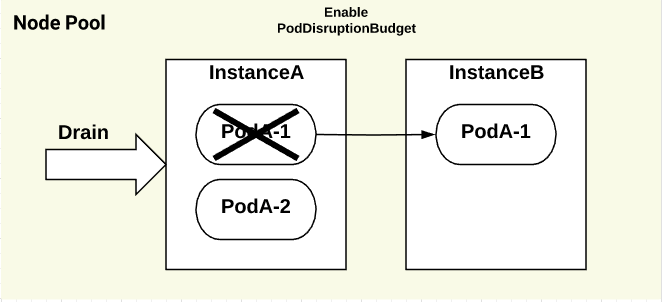
-
-
PodAffinityを設定する
- 必須ではないがアップグレード時間が短縮し、耐障害が向上
Podの配置が偏っている(kube-dns)
namespace=kube-system のkube-dnsについても同様の問題が発生します(GKE v1.6で確認)。
前の問題と同様にPodDisruptionBudgetを設定することは可能です。
しかしEvict処理で別インスタンスに移動したPodがなぜかterminateされ、kubectl drainの処理がタイムアウトするまで処理が停止します。
これはkube-dns-autoscalerが独自にkube-dnsのPodをコントロールしているためだと思います。
解決方法
解決できていません。
kube-dnsにPodDisruptionBudgetの設定するIssueもあるので将来的には解消されると思います。
kube-dnsの起動は数秒なので、10秒程度のダウンタイムを許容できるアプリケーションサービスであれば問題になりません。
kube-dnsをdelete podすることで、インスタンスを移動させる事も可能ですが、アップグレード中に再び偏る可能性があるので効果は薄いです。
Statefulなアプリケーションの再起動処理が考慮されていない
これは単純に永続化が必要なデータにPersistentVolumeの設定がされていないミスや、StatefulSetsなアプリケーション、ミドルウェアの初期化スクリプトが漏れているケースです。
例えばRedisClusterの場合、init-containersの処理でクラスターに復帰したり、リシャーディングするスクリプトが必要となります。
解決方法も個々の対応となるので本記事には記載しません。
ノード数が3未満になっている
クラスターを作るときにノード数が3未満だと以下の警告がでます。
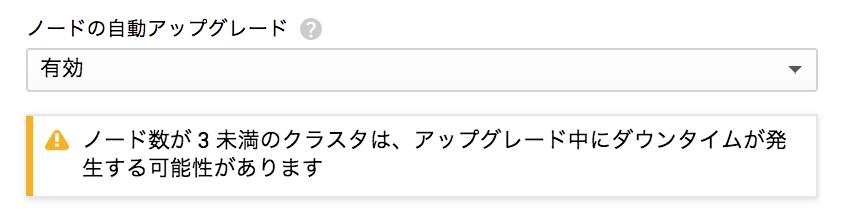
理由が記載されいませんが、n1-standard-16のなどの高いリソースを持つマシーンタイプ2台でも同じ警告がでるため、リソース以外の理由が考えられます。
解決方法
深く考えることをやめて、ノード数を3以上にする。
その他のアプリケーションサービスが停止するケース
- ネットワーク関連のエラーが発生してしまう
- Golangアプリで
getsockopt: no route to hostのエラーが発生- 名前解決まではできていたが詳しくは未調査
- Golangアプリで