OS のアップデートやスケールダウンなどで複数の Node を安全に停止したい場合のメモです。この記事は Kubernetes 1.7.3 で確認した情報を元に記載しています。
TL;DR
- Node を停止するためにはkubectl drain コマンドを利用して停止準備を行います
- drain は Node を Pod のスケジュール対象から外し (unschedulable に設定) Node 上の Pod を退去させることで停止可能な状態にします
- しかし複数の Node を停止させる場合、アプリケーションの Pod が一つも動作していない状態 (ready な Pod が 0)がありえるので注意が必要です

-
PodDisruptionBudgetを定義することで安全な Pod 数を保ったまま複数 Node の drain を行うことができるようになります
- 安全な Pod 数が確保できるまで
kubectl drainが Pod の退去を待ってくれるようになります
- 安全な Pod 数が確保できるまで
Node から Pod を退去させる (kubectl drain)
OS のアップデートやスケールダウンなどで Node を停止したい場合、その Node にスケジュールされている Pod に退去してもらう必要があります。この操作は kubctl drain <NODE> というコマンドで簡単に行うことができます。
下記のように Node 名を指定して kubectl drain を実行します。
$ kubectl drain --ignore-daemonsets --force gke-cluster-2-default-pool-0fb8a591-71rf
# Node が unschedulable に設定される (kubectl cordon と同等)
node "gke-cluster-2-default-pool-0fb8a591-71rf" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, DaemonSet or StatefulSet: kube-proxy-gke-cluster-2-default-pool-0fb8a591-71rf; Ignoring DaemonSet-managed pods: fluentd-gcp-v2.0-tt6mf
# この Node にある Pod が退去させられていく
pod "myapp-1243928920-bz02h" evicted
pod "heapster-v1.4.0-1718439912-xmg0k" evicted
# drain が完了
node "gke-cluster-2-default-pool-0fb8a591-71rf" drained
ノードが正しく SchedulingDisabled (unschedulable) になっていることを確認します。動作中の Pod がなくなり、新たに Pod がスケジュールされることもないため、このノードは停止することができます。
$ kubectl get nodes
NAME STATUS AGE VERSION
gke-cluster-2-default-pool-0fb8a591-71rf Ready,SchedulingDisabled 20m v1.7.3 # SchedulingDisabled になった
gke-cluster-2-default-pool-0fb8a591-cmcl Ready 20m v1.7.3
gke-cluster-2-default-pool-0fb8a591-d6pn Ready 20m v1.7.3
gke-cluster-2-default-pool-0fb8a591-n1sr Ready 20m v1.7.3
kubectl drain の動作
kubectl drain では主に以下の処理が行われています。
- Node に新規 Pod がスケジュールされないように
unschedulableの設定を行う - Node に紐付けられている Pod 一覧を取得して、Pod 群に退去 (evict) の処理が行われる
- 詳しくは後述の Eviction API をご覧ください
- evict がサポートされない場合(旧バージョンの API Server など)は単に削除処理になる
動作例
例えば Node が 4台あり、以下のように myapp というアプリケーションが 2 つのノードにある状態だとします。myapp は ReplicaSet (レプリカ数 2) で管理されているとします。
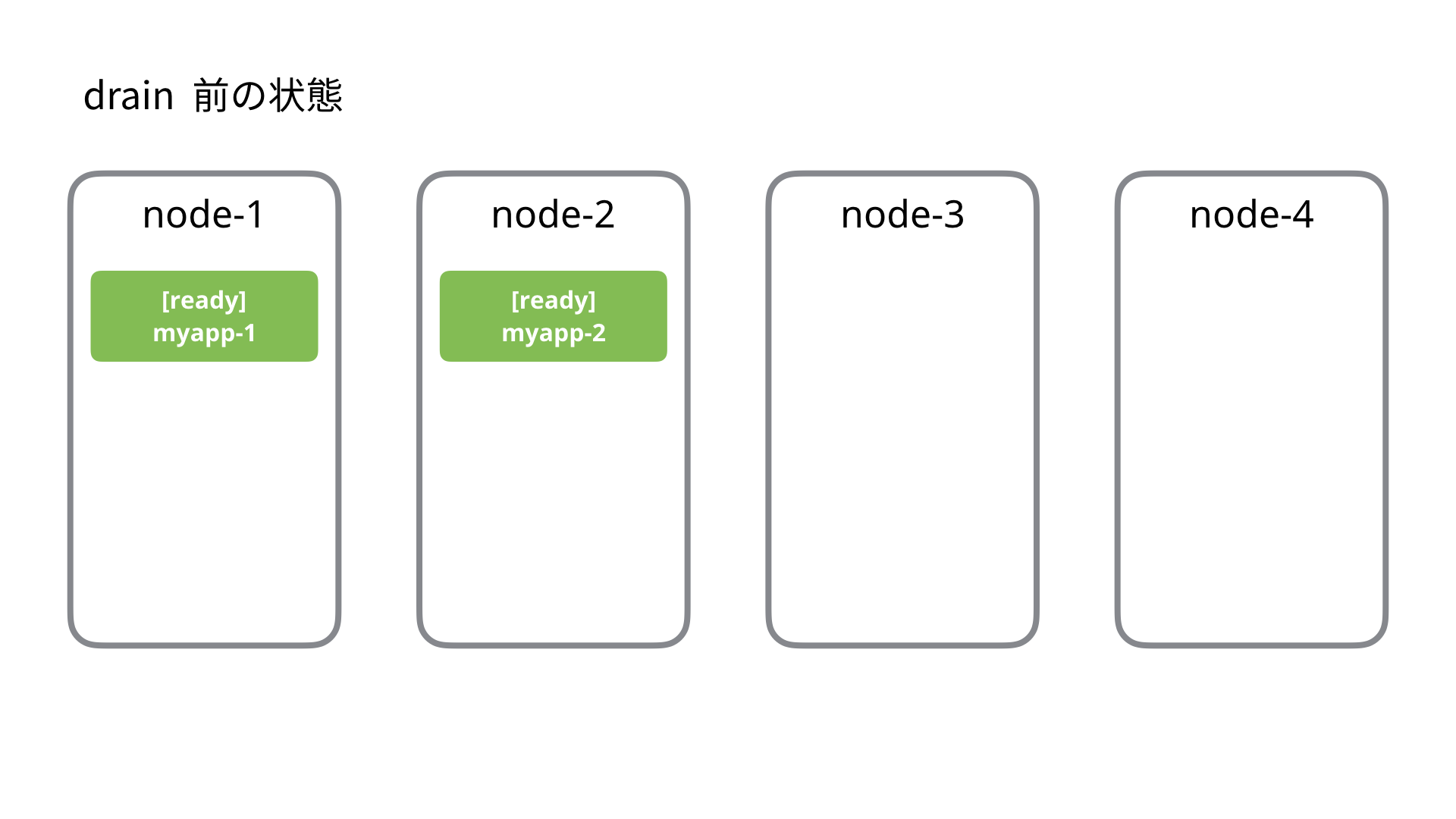
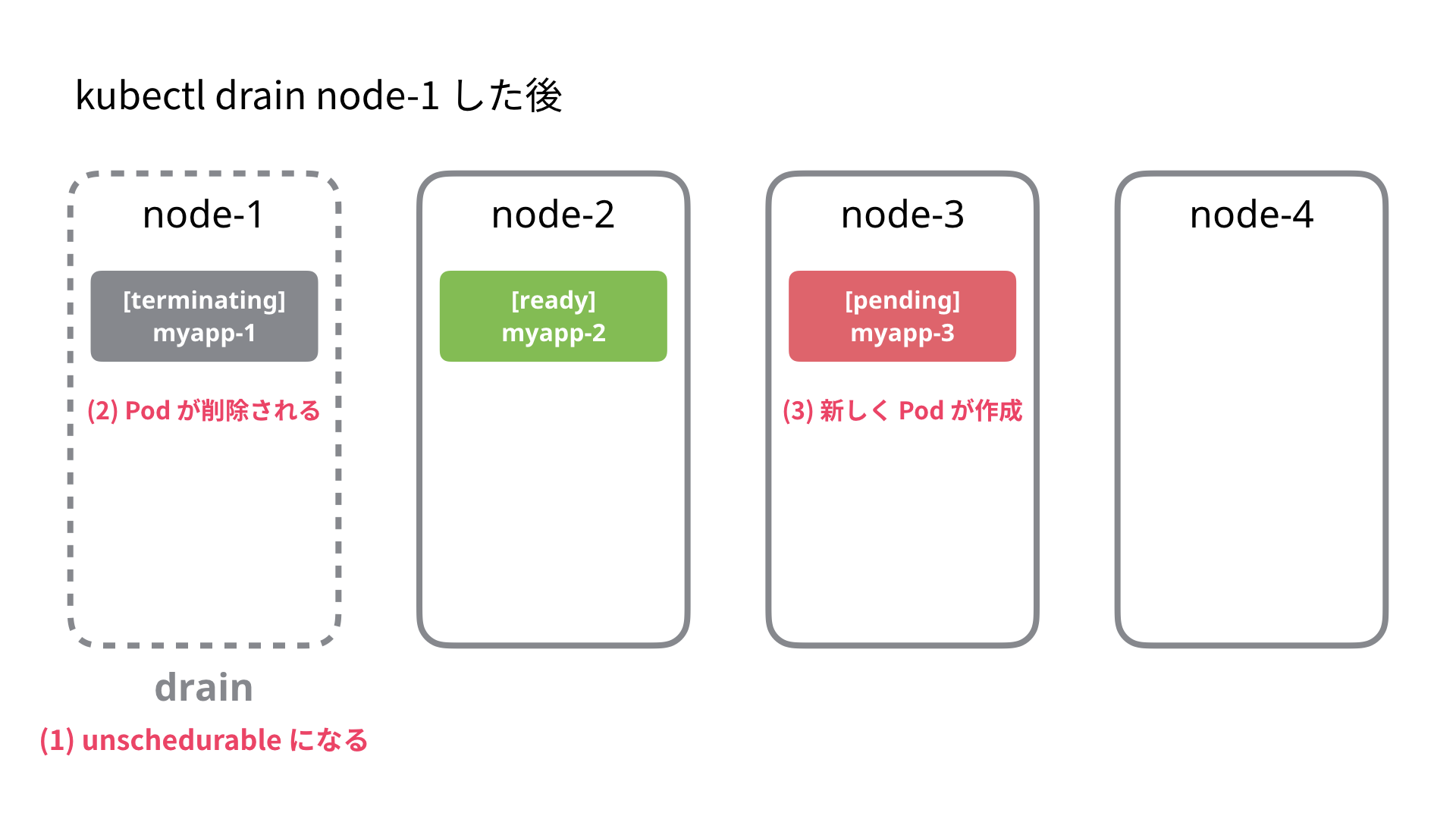
node-1 に対して kubectl drain を行うと、下記のような順序で処理が行われます。
- node-1 を
unschedulableに設定 - node-1 に割り当てられた Pod (ここでは myapp-1) が退去(evict)させられます
- PodDisruptionBudget が設定されていない場合、退去(evict) は単純に Pod が削除されます
- kubectl の drain はここで終了します
- ReplicaSet の働きによって node-3 に新たに Pod が作成され、レプリカ数 2 が保たれます。
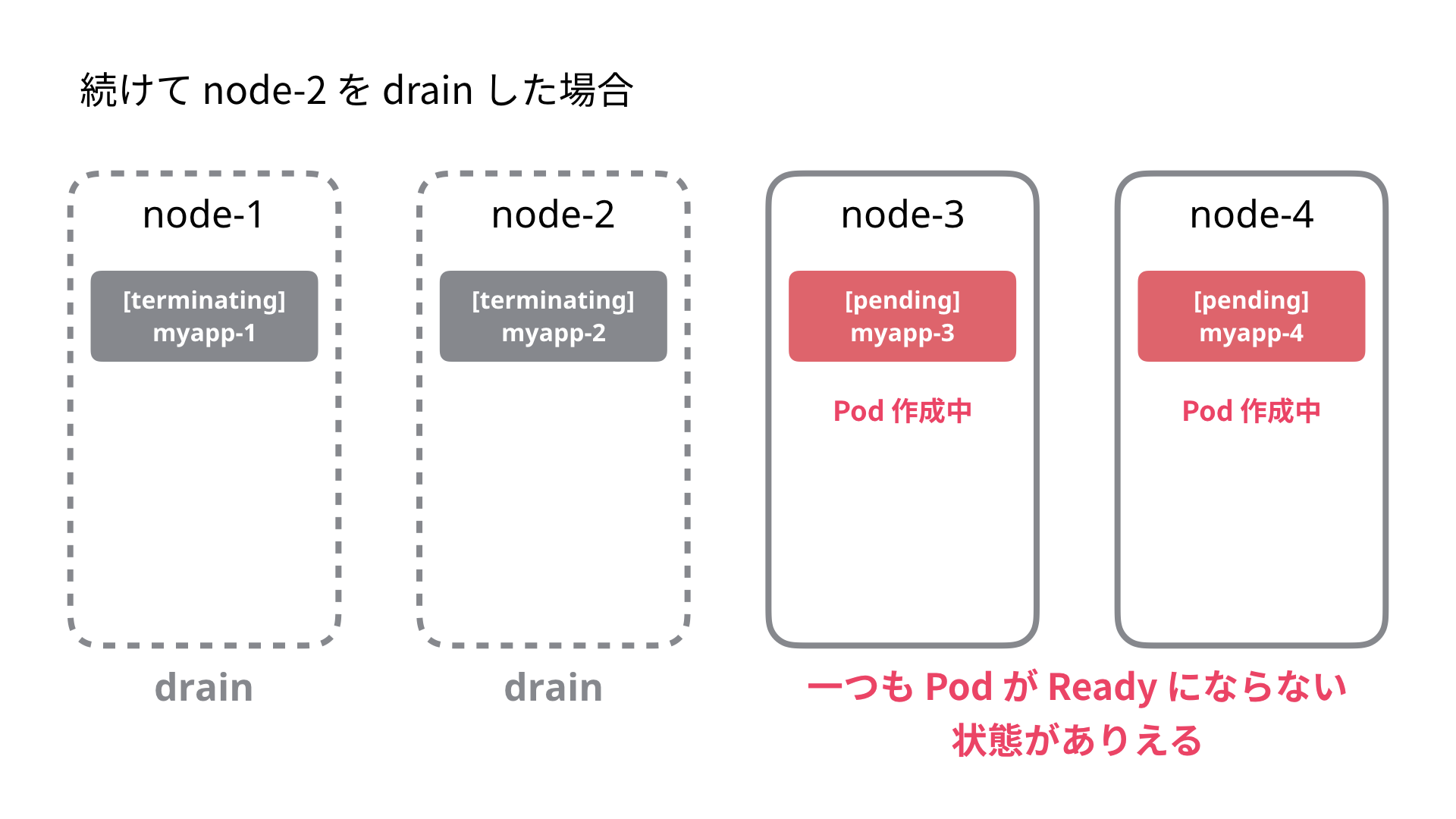
 注意が必要な場合
注意が必要な場合
続けて node-2 を drain したい場合注意が必要です。新しく作成された myapp-3 の Pod 作成に時間がかかった場合は、node-2 を drain することによって一つも Pod が ready になっていない状況が起こり得ます。
PodDisruptionBudget による安全な drain
PodDisruptionBudget とは Node を計画的に停止したい場合に、Pod の状況を見ながら退去 (evict) させる機能です。基本的にアプリケーションは ReplicaSet によって複数の Pod が保持されているため冗長性があると考えられます。PodDisruptionBudget は停止状態 (Disruption) として許容できる Pod 数を予算 (Budget) として定義して、その予算内で退去させていきます。(Error Budget 的な名前で洒落ていますね)。
PodDiruptionBudget では以下のどちらかの設定が可能です。
-
.spec.minAvailable: 少なくとも有効であるべき Pod 数。パーセンテージによる指定も可能 -
.spec.maxUnavailable: 最大無効であってもよい Pod 数。パーセンテージによる指定も可能 (v1.7 以上で利用可能)
以下のように PodDisruptionBudget リソースを定義して利用します。kubectl create poddisruptionbudget というサブコマンドによる作成も可能です。
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: myapp
spec:
# 最大で無効状態な Pod は 1 に設定。これを超えては退去させられない
maxUnavailable: 1
# 対象 Pod のセレクタ
selector:
matchLabels:
run: myapp
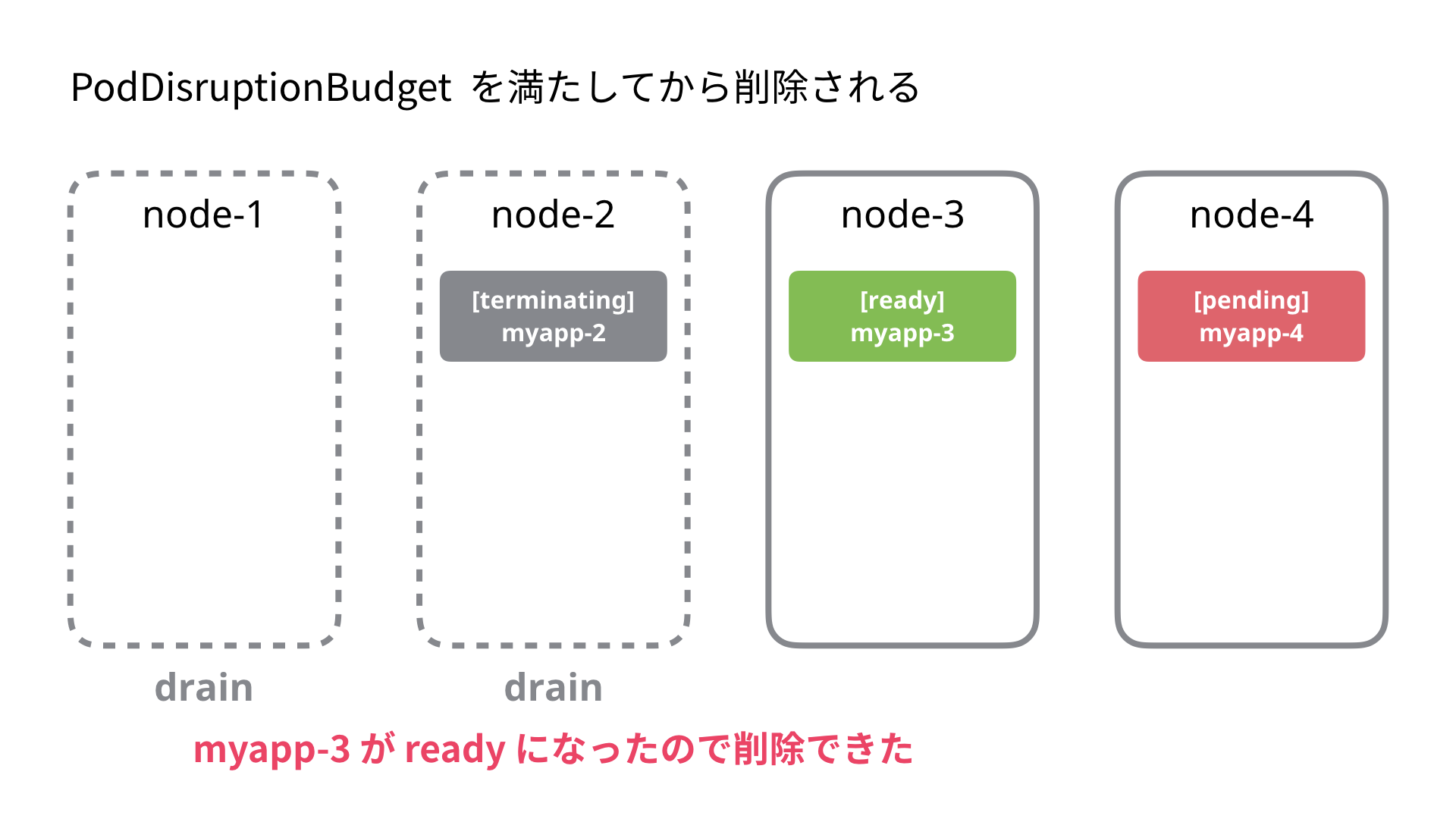
これを設定すると前述の例の Node-2 の退去は以下の動作になります。
- node-2 を unschedulable に設定
- node-2 に割り当てられた Pod (ここでは myapp-1) を退去(evict)しようとする
- すでに unavailable の Pod があり PodDisruptionBudget を超えてしまうため退去を待ちます (5 秒間隔でリトライ)
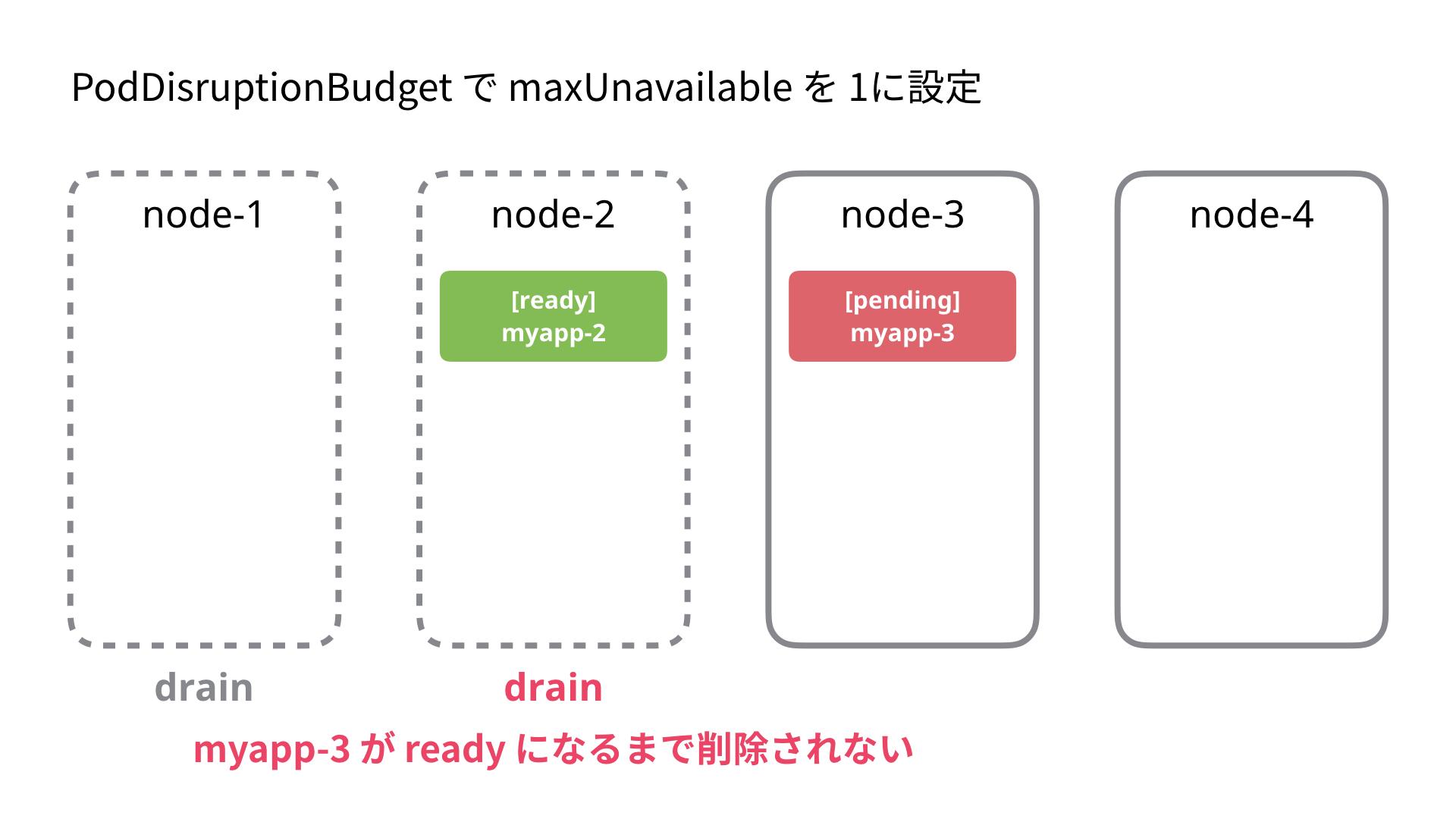
node-3 の Pod が ready になり PodDisruptionBudget を満たすようになると node-2 の Pod は削除されます。
PodDisruptionBudget の状況を見る
PodDisruptionBudget リソースには管理されている Pod の状態が記述されています。kubectl get pdb で設定状況と現在停止が許容される Pod 数 (ALLOWED-DISRUPTIONS ) を見ることができます。
$ kubectl get pdb
NAME MIN-AVAILABLE MAX-UNAVAILABLE ALLOWED-DISRUPTIONS AGE
myapp N/A 1 1 2m
詳細な状況は下記のように見ることができます。
$ kubectl get pdb -o yaml myapp
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"policy/v1beta1","kind":"PodDisruptionBudget","metadata":{"annotations":{},"name":"myapp","namespace":"default"},"spec":{"maxUnavailable":1,"selector":{"matchLabels":{"run":"myapp"}}}}
creationTimestamp: 2017-08-28T07:53:13Z
generation: 1
name: myapp
namespace: default
resourceVersion: "8859"
selfLink: /apis/policy/v1beta1/namespaces/default/poddisruptionbudgets/myapp
uid: f14ed83b-8bc5-11e7-862c-42010af00125
spec:
maxUnavailable: 1
selector:
matchLabels:
run: myapp
status:
# ready 状態の Pod 数
currentHealthy: 10
# この数を下回っては Evicton できない
desiredHealthy: 9
disruptedPods: null
# 現在停止が許される Pod 数。currentHealthy - desiredHealthy で計算される
disruptionsAllowed: 1
expectedPods: 10
observedGeneration: 1
補足: Eviction (退避) API
kubectl drain では内部的には Pod の削除(DELETE)ではなく、Eviction API という Pod のサブリソースを呼び出して Node に紐づく Pod の退避を行っています。Pod の削除との違いは PodDiruptionBudget を参照し予算を満たさない場合は削除せずに 429 Too Many Requests を返す点です。
Eviction サブリソースは Pod のサブリソースとして以下のように定義されています。
/api/v1/namespaces/<NAMESPACE>/pods/<POD>/eviction
この API に対して以下のような Eviction サブリソース を POST します。
{
"kind": "Eviction",
"apiVersion": "policy/v1beta1",
"metadata": {
"name": "myapp-1243928920-bz02h", # POD 名
"namespace": "default",
"creationTimestamp": null
},
"deleteOptions": {}
}
Eviction API は PodDiruptionBudget を参照し、定義した予算を満たしている場合は Pod の削除して HTTP の 201 Created、満たしていない場合は削除せず HTTP の 429 Too Many Requests を返します。
# kubectl の verbose ログ
I0828 14:12:38.049411 29825 round_trippers.go:405] POST https://35.194.250.38/api/v1/namespaces/default/pods/myapp-1243928920-cpmcr/eviction 429 Too Many Requests in 39 milliseconds
kubectl drain では 429 Too Many Requests のときは 5 秒ごとにリトライする実装になっており、予算を満たすかタイムアウト(--timeout の値)になるまで待ち続けます。(参考: drain.go#L500)
PodDisruptionBudget の動作を試してみる
PodDisruptionBudget を実際に試してみます。ここでは ready になるまでに時間がかかる(2分)アプリケーションをデプロイし、maxUnavailable を 1 に設定しています。(使用した Deployment と PodDisruptionBudget のマニフェスト)。下記のように Pod が 2 つの Node にデプロイされている状態から始めます。Node は全体で 4 つあります。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-1871887261-k5v4s 1/1 Running 0 2m 10.8.0.7 gke-cluster-1-default-pool-94337df7-lnc5
myapp-1871887261-x23z5 1/1 Running 0 2m 10.8.2.6 gke-cluster-1-default-pool-94337df7-sfp4
Pod がデプロイされている 2 Node に対して同時に drain を実行してみます。
$ kubectl drain --ignore-daemonsets --force gke-cluster-1-default-pool-94337df7-lnc5
$ kubectl drain --ignore-daemonsets --force gke-cluster-1-default-pool-94337df7-sfp4
ReplicaSet を watch して drain 中の Pod の状態を見てます。想定どおり PodDisruptionBudget のおかげで ready の Pod が常にある状態を保っています。Node の一つは drain がすぐに終わり、もう一つの Node は drain が PodDisruptionBudget で定義した Pod のready を待つために約 2 分間かかりました。
# DESIRED : ReplicaSet で定義したレプリカ数
# CURRENT : Pod 数 (ステータスは関係なし)
# READY : ready 状態の Pod 数
$ kubectl get rs -w
NAME DESIRED CURRENT READY AGE
myapp-1871887261 2 2 2 3m # drain 実行前
myapp-1871887261 2 1 1 3m # ひとつめの Node の drain によって Pod が減る
myapp-1871887261 2 2 1 3m # ReplicaSet によって Pod が増えるが ready にはならない
# ready を待つためにここで約 2分間かかる
myapp-1871887261 2 2 2 5m # 2 つready になったので ふたつめの Node も drain できる
myapp-1871887261 2 1 1 5m # ふたつめの Node の drain によって Pod が減る
myapp-1871887261 2 2 1 5m # ReplicaSet によって Pod が増えるが ready にはならない
myapp-1871887261 2 2 2 7m # 2 分たってすべてが ready になる