概要
MAGELLAN BLOCKSのMachine Learningボードα版がリリースされたので、機械学習はほぼ素人のエンジニアがやってみました。
今回試したのは数値回帰です。
下記howtoページの内容を実行し、最終的にはRで作成した「線形回帰モデル」との比較を行います。
https://www.magellanic-clouds.com/blocks/ml-regression-howto/
※「因子を見直す」まだ試してません。
※2017/02/03時点の情報で記載しています。
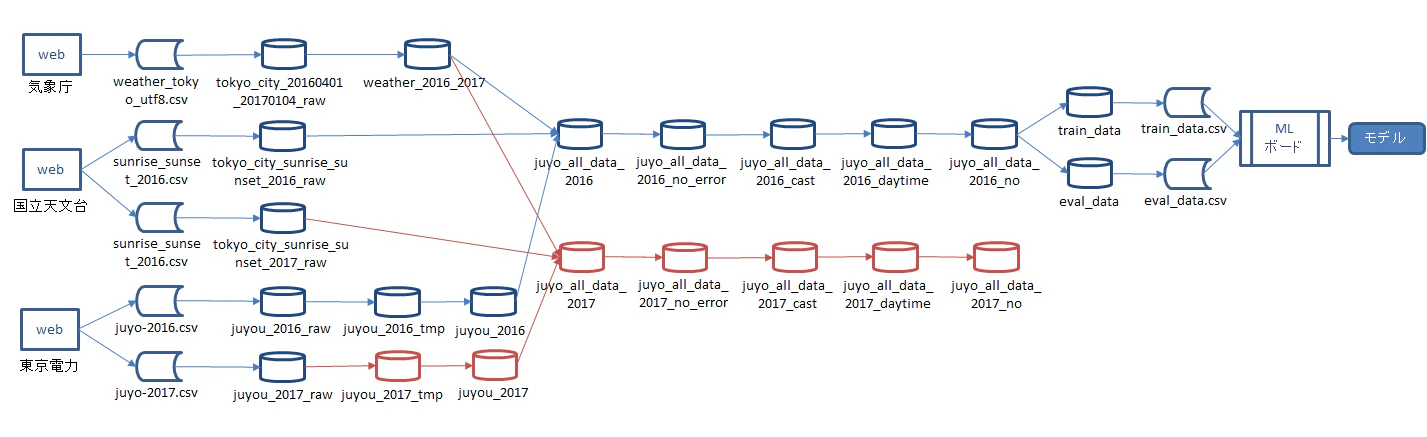
モデル作成までの全体図
詳細手順はhowtoページの通りなので記載しませんが、モデル作成までの全体像はこんな感じで、前処理のデータ編集はBigQuery(SQL)で行います。
※青色の部分がhowtoページで作成する部分、赤色部分は検証用に独自に作成
データ準備
スプレッドシートを活用してデータの準備を行いました。
参考:Googleスプレッドシートに東京の日の出・日の入り時間を表示する。
※2017/02/03時点で、電力使用量のデータは2016/4/1からしか取得できませんでした。
よって、最終的に使用する学習/予測で使用するレコード数は以下の通りとなります。
| 目的 | 期間 | 件数 | 備考 |
|---|---|---|---|
| 学習用 | 2016/04/01~2016/12/31 | 274 | 訓練,検証データの割合は8:2 |
| 予測用 | 2017/01/01~2017/01/31 | 31 |
トレーニング設定
トレーニング設定は以下の通り
| 設定内容 | 設定値 |
|---|---|
| トレーニングの経過制限時間(分) | 0 |
| トレーニングの最大試行回数 | 20 |
トレーニング結果
MAGELLAN BLOCKSの画面よりトレーニング結果を確認する事が出来ます。

トレーニング時間は8時間35分、誤差は7560.74となっています。
また、GCPコンソール画面の「機械学習」を見ると、ジョブとモデルがそれぞれ作成されている事が確認できます。

ベンチマーク用のモデル作成
今回は精度の比較対象に線形回帰(lm)を使用します。
事前に下記テーブルより、date以外の項目をcsvで出力しておきます。
| テーブル | 出力ファイル | |
|---|---|---|
| juyo_all_data_2016_daytime | ⇒ | data2016.csv |
| juyo_all_data_2017_daytime | ⇒ | data2017.csv |
CSVレイアウト
| カラム |
|---|
| max_temp |
| min_temp |
| hours_of_sunshine |
| humidity_avg |
| daytime_time |
| used_sum |
下記Rを実行し、予測結果を取得します。
setwd("ファイル保存のディレクトリ")
# ファイル読み込み
juyo2016 <- read.csv("data2016.csv")
juyo2017 <- read.csv("data2017.csv")
# 線形回帰でモデル作成+予測
juyo.lm <- lm(used_sum~., data=juyo2016)
summary(juyo.lm)
juyo.lm.predict <- predict(juyo.lm,juyo2017)
print(data.frame(juyo.lm.predict))
結果
ベンチマークにはhowtoページにある二乗平均平方根誤差(RMSE: Root Mean Square Error)を利用しました。
※数値が小さいほど誤差が少ない
| モデル | RMSE |
|---|---|
| (MAGELLAN BLOCKS)ニューラルネット | 9,027 |
| (R)線形回帰 | 17,553 |
グラフで書くとこんな感じです。
線形回帰に比べると大分いい感じになっている事がわかります。

まとめ
- TensorFlowどころかPythonも書いていないのにそこそこの精度のモデルが出来た
- ニューラルネットワークの層数やユニット数等も考える必要なし(ハイパーパラメータチューニング)
- Googleのインフラを利用でき、BigQueryやGCSとの連携が容易
- 入力データを増やす、因子を変える、トレーニングの最大試行回数を増やす事で更なる精度向上が期待出来る
本職のデータサイエンティストであればより良いモデルが作成できるかもしれませんが、素人がプログラムを書くことなく、ここまで出来るようになったのはかなり凄い事なのではないでしょうか。
精度を上げる挑戦については、別途記事をあげたいと思います。