まえおき
RAG周りの情報を調べていて、気になったものをまとめます。追加予定です。
気になることがあった記事・論文・動画・書籍の単位で、メモを取ります。
時間があれば整理していきたい。。。
2023/11/11追加分:
・1. Retrieve & Re-Rank(SentenceTransformersライブラリのWebページ)
・2. Cross-Encoders(SentenceTransformersライブラリのWebページ)
・3. How to Chunk Text Data — A Comparative Analysis(Mediumの記事 Solano Todeschiniさん)
・4. 論文翻訳: The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries(TAKAMI TORAOさんのブログ)
2023/11/12追加分:
・5. Precise Zero-Shot Dense Retrieval without Relevance Labels(Luyu Gaoさんら arXiv)
2023/11/13追加分:
・6. RAGにおけるドキュメント検索精度向上について(概要編) (損害保険ジャパン株式会社 DX推進部の眞方さん Zenn)
・7. Microsoft が Azure Cognitive Search による RAG システムの定量評価結果を公表(Nobusuke Hanagasakiさん Qiita)
2023/11/14追加分:
・8. Generate rather than Retrieve: Large Language Models are Strong Context Generators(Wenhao Yuさんら arXiv)
2023/11/16追加分:
・ 9. Lost in the middle: The problem with long contexts(Langchain 公式ドキュメント)
2023/11/21追加分:
・ 10. Applying OpenAI's RAG Strategies(Langchain 公式ブログ)
2023/12/16追加分:
・ 11. A Guide on 12 Tuning Strategies for Production-Ready RAG Applications(Mediumの記事 Leonie Monigattiさん)
2023/12/31追加分:
・ 12. LlamaIndex Talk (Snowflake BUILD 2023)の発表スライド
2024/2/7追加分:
・ 13. オープンな日本語埋め込みモデルの選択肢(NTTコミュニケーションズ株式会社イノベーションセンター杉本さん)
1. Retrieve & Re-Rank
Retrieve & Re-Rankの仕組みの概要は、図1に示す通り(SentenceTransformersライブラリのWebページから引用させていただいた)。クエリに関連した文章をRetrieverで取得した後に、Re-Rankerによりクエリと強く関連する順で並び替える。これにより、なるべくクエリと密接に結びついた情報のみを抽出することができる。Re-Rankerは、クエリとその関連文章の類似度をRetrieverより精度よく計算できる必要がある(はず)。
Retriever, Re-Rankerは、semanticなものを使わずとも良いのではと思った。膨大な文章の集合からラフにRetrievalして、精度よくRe-Rankできれば、仕組みは何でもよい気がする。RetrieverにBM25のようなSpaseなRetrieverを使ったり、Re-Rankerに生成モデルを使ったりと、そんなこともできそう。
サンプル実装は、SentenceTransformersライブラリのexampleとして公開されている(retrieve_rerank_simple_wikipedia.ipynb)。
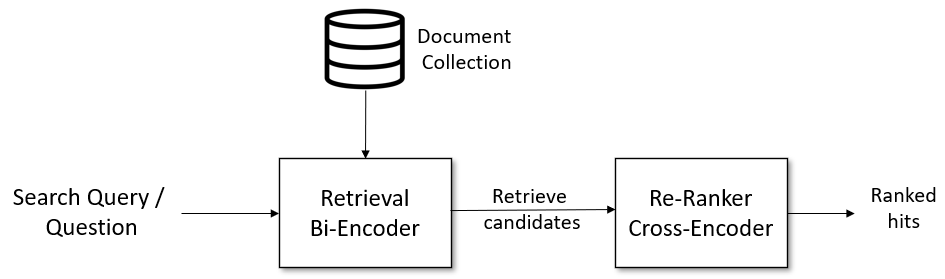
図1. Retrieve & Re-Rankの概要(SentenceTransformersライブラリのUsageから引用)
2. Cross-Encoders
SentenceTransformersライブラリのドキュメントでCross-Encodersの説明があった。
Cross-Encodersは、二つの文をまとめて一つのTransformerに与えて類似度を計算する。Bi-Encodersは、二つの文を独立にTransformerに与えて、それぞれのベクトル表現を求め、そのベクトル表現間の類似度を計算する。
どちらも文同士の類似度の計算に用いることができるが、Cross-EncodersはBi-Encodersより優れたパフォーマンスを示す。つまり、似た文を精度よく探せる。しかし、文の集合に対して、全ての組み合わせの類似度を求める状況において、Cross-EncodersはBi-Encodersより計算スピードの面で劣る。Bi-EncodersはTransfomerの処理後に文の組み合わせを考慮すればよいのに対して、Cross-Encodersは文の組み合わせパータン全てに、重いTransfomerの処理を実施しなければならいためである。
3. How to Chunk Text Data — A Comparative Analysis
この記事では、Langchain Character Text Splitter、NLTK Sentence TokenizerとSpacy Sentence Splitter、Adjacent Sequence Clusteringについて比較されていた。中でもAdjacent Sequence Clusteringが興味深い。
Langchain Character Text Splitterは、テキストの言語の構造には敏感ではないが、均一なサイズにテキストを分割できる。NLTK Sentence TokenizerとSpacy Sentence Splitterは、テキストの言語の構造をもとにテキストの分割を行うが、チャンクのサイズにばらつきがある。Adjacent Sequence Clusteringは、チャンクサイズの上限下限を設定したうえで、文章の頭から順に文をチャンクに詰め込んでいき、隣接する2文の類似度が閾値以下になる(隣接する2文の関連度が下がる)ところでチャンクを切り替えて、文脈を考慮した分割が可能である。
4. 論文翻訳: The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries
翻訳記事でざっと本露文のあらましを掴む。
Maximal Marginal Relevance(MMR、周辺関連性最大化)は、検索された文書の再ランキングや、テキスト要約のための適切なインプット選択に有効な手法として、提案された。
MMRは、検索された文書の再ランキングの文脈において、検索結果とクエリの関連性と、検索結果の非重複性の双方を高めることを意味する。また、MMRは、テキスト要約のための適切なインプット選択において、(おそらく)インプットと要約のトピックの関連性と、インプット同士の非重複性の双方の向上を意味する(かなと)。個人的には、検索結果の再ランキングの方がMMRの意味がイメージしやすい。
MMRによる文章の選び方は、次のような数式で書ける。
この数式は、文章を選択する際に、クエリ対する関連性と、既に選択された文書との新規性(非類似性)を、パラメータ$\lambda$の重みの下で、同時に最大化している。より平たく言うと、第一項は、クエリと似た文章を取り込むための正の項で、第二項は似ている文章をはじきたいがための負の項である。
\begin{equation}
\arg max_{D_i \in R \backslash S} \left[ \lambda {\it Sim}_1(D_i, Q) - (1 - \lambda) \max_{D_j \in S} {\it Sim}_2(D_i, D_j) \right]
\end{equation}
$D_i$:選択される候補文書。
$R$:情報検索システムによって検索された文書のランク付けされたリスト。
$S$:既に選択された文書のサブセット。
$\lambda$:クエリとの関連性と新規性のバランスを調整するパラメータ(0から1の間の値)。
$Sim_1 (D_i, Q)$:文書$D_i$とクエリ$Q$の間の類似度。
$Sim_2 (D_i, D_j)$:文章$D_i$:と既に選択された文章$D_j$:間の類似度
数式の感想としては、第二項は、$max$以外の形もあるのではないかと思った。
Simの添え字が異なるということは、類似度関数に別々のものを取ることも考慮していそう。
翻訳元の論文はこちら。
The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries
参考までに、langchainでVectorstoreからretrieverを作る際にsearch_typeオプションとしてMMRが選べる。詳しくは、このページVectorstore Retriever Optionsを参照。
5. Precise Zero-Shot Dense Retrieval without Relevance Labels
HyDE(Hypothetical Document Embeddings)と呼ばれる文章検索の手法を紹介している。
クエリに関連する文章を検索する際に、次の2ステップを行う。
①クエリからクエリに対する仮想回答を生成
②仮想回答と関連する文章を検索
通常のRetrieval(クエリの埋め込みと検索対象の文章の埋め込みの間で直接類似度を測り検索する)と比較して、「Web search on DL19/20」や「Low resource tasks from BEIR」における多くのタスクで優れた成績を収めた。
6. RAGにおけるドキュメント検索精度向上について(概要編)
気になった箇所をピックアップする。
図2(a)で示すように、
LongLLMLingua: ACCELERATING AND ENHANCING LLMS IN LONG CONTEXT SCENARIOS VIA PROMPT COMPRESSIONで、prompt中のドキュメント数が増えると出力精度が落ちることが確認された。無駄なドキュメントを渡さないように、ドキュメントの検索精度向上が必要になる。また、図2の(b)で示すように、重要なドキュメントがPromptの中盤に位置すると出力精度が落ちることが確認された。複数の文章を検索する際、Re-Rankにより最も重要な記事をトップに持ってくることが大事になる。
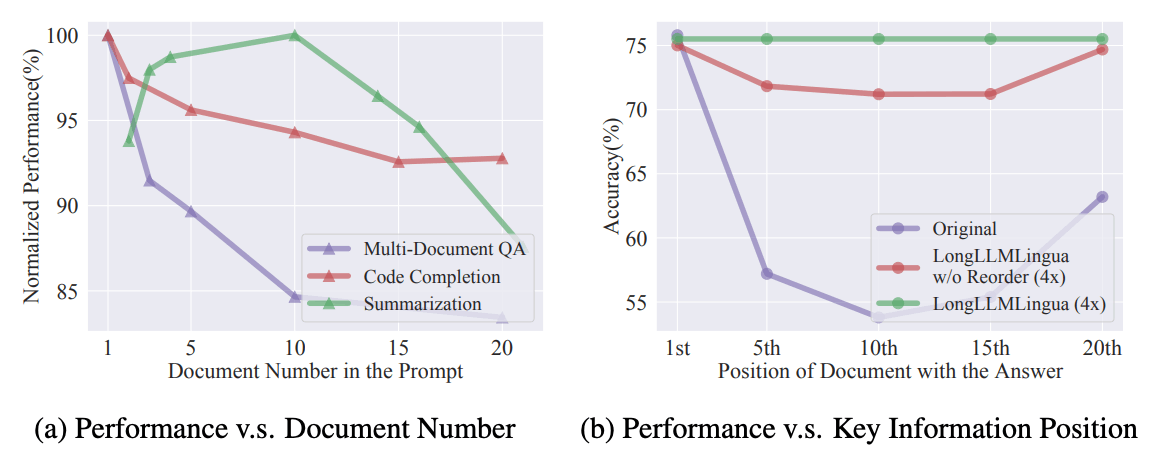
図2 (a)Prompt中のドキュメント数と精度の関連性 (b)Prompt中の重要ドキュメントの順位と精度の関連性(上述の論文から引用)
その他、情報検索は、クエリと検索先の情報量の差に注目して、symmetric search / asymmetric searchに分けて考えるという視点が、非常に重要だと感じた。
asymmetric searchの対処法として、クエリを検索先に近づけるか、検索先をクエリに近づけるか、2パターンの対処法を提案されていた。前者、クエリを検索先に近づけるパターンは、HyDEで実現できる。後者、検索先をクエリに近づけるパターン(要約生成)では、検索元とクエリのembeddingを直接比較するのではなく、検索元の要約に対して検索させることで精度向上しようとする取り組みがある。
この要約生成の取り組みは、langchainにおいて、MultiVector RetrieverのSummaryという方法で実装されていそうだ(langchainのMultiVectorはネーミングセンス悪くない?と思う)。
この記事の後編(実装編)も気になる。
7. Microsoft が Azure Cognitive Search による RAG システムの定量評価結果を公表
Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilitiesの日本語解説記事。大変勉強になった。元のMicrosoftの記事とこの記事は、ぜひとも読むべき記事。
様々な種類のクエリで、セマンティックハイブリッド検索(ハイブリッド検索+セマンティックランカー)がイケてる。事実を求める質問もよい精度が出ていたので、論文の内容を検索するのにもセマンティックハイブリッド検索良いのではと感じた。
チャンクの戦略についても、インサイトがあるのはありがたい。チャンクサイズは512トークンで、オーバーラップは25%(128トークン)が良いそう。そのチャンク戦略で、検索結果上位1~5件(横軸)、それぞれの場合において、その上位の検索結果に高品質とラベル付けしたチャンクが含まれる割合を検索モードごとに比較したグラフが以下図3とのこと。
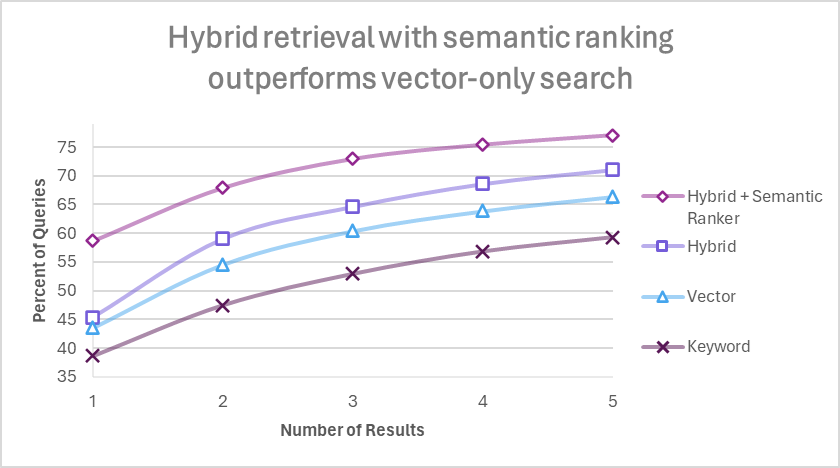
図3 検索構成間で比較した、上位1~5位で高品質のチャンクが見つかったクエリの割合。すべての検索モードにおいて、同じ顧客クエリ/文書ベンチマークセットを使用した。文書チャンクは512トークンで、25%重複している。ベクトル検索とハイブリッド検索はAda-002 embeddingsを使用。
テストに使った75%以上のクエリで、セマンティックハイブリッド検索を使えば、検索結果の上位5件に、高品質なチャンクが見つかったとな。素晴らしい。
セマンティックハイブリッド検索試してみるか。
8. Generate rather than Retrieve: Large Language Models are Strong Context Generators
LLMでQAタスクのインプットをGenerateさせる手法、GENRED、が提案され、RetrieveしたドキュメントをQAタスクのインプットに用いる従来手法よりも、いくつかベンチで良い結果が出ることが確認されたという論文。
インプットドキュメントの生成用のプロンプトは、例えば「Generate a background document to answer the given question. {question placeholder}”」のような文でクエリの背景となるドキュメントを用意する。このような文で得たインプットともともとのクエリをもとに、クエリへの回答を生成する。そのためのプロンプトは、「Refer to the passage below and answer the following question. Passage: {background placeholder} Question: {question placeholder}」というプロンプト。
また、この論文では、GENRED様々な種類のドキュメントをインプットに用意できれば、回答の質を向上できると考え、学習用データセットを用いてプロンプトを量産する方法を提案している。
GENREDは、generate hypothetical document then read であり、HyDEは、generate hypothetical document, retrieve real document related to hyothetical one and then read real documentである。どちらの手法においても、最初に答えに関する仮説ドキュメントを生成するが、それをあえてそのまま回答生成に利用するか、関連ドキュメントの検索のために利用するか、その後の処理に違いがある。
9. Lost in the middle: The problem with long contexts
LLMのインプットとして多数の文章(1文章~Wikipedia1段落程度の文量)を渡す際に、重要な記事をトップ or ボトムに持ってくるツールがlangchainで提供されている。そのツールはLongContextReorderという名で、langchain.document_transformersで管理されている。使用方法はいたって簡単で、以下の二行で文章の並び替えができる。
# Reorder the documents:
# Less relevant document will be at the middle of the list and more
# relevant elements at beginning / end.
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
# Confirm that the 4 relevant documents are at beginning and end.
reordered_docs
reorderの詳細を知るために、ツールの実装を見てみると、
def _litm_reordering(documents: List[Document]) -> List[Document]:
"""Lost in the middle reorder: the less relevant documents will be at the
middle of the list and more relevant elements at beginning / end.
See: https://arxiv.org/abs//2307.03172"""
documents.reverse()
reordered_result = []
for i, value in enumerate(documents):
if i % 2 == 1:
reordered_result.append(value)
else:
reordered_result.insert(0, value)
return reordered_result
重要度や関連度で降順にソートされた文章の束に対して、逆順(つまり昇順)に直してリストのボトムとトップに交互に文章を詰めることで、リストの端に大事な文章が固まるようにしていた。
Lanchainのページで紹介されているように、このツールの背景には、最近の研究(Lost in the Middle: How Language Models Use Long Contexts や LongLLMLingua: ACCELERATING AND ENHANCING LLMS IN LONG CONTEXT SCENARIOS VIA PROMPT COMPRESSION)がある。重要なドキュメントがPromptの中盤に位置すると出力精度が落ちることが確認されており、複数の文章をLLMのインプットとして渡す際に、重要な記事をトップ or ボトムに持ってくることが大事だと考えられている。
10. Applying OpenAI's RAG Strategies
OpenAI DevDayで紹介されたRAG戦略について、langchainでどのように実装するか紹介している。
個人的に気になったRAG戦略についてピックアップ。
Query expansion:LangChainのMultiQueryRetrieverは、ユーザのクエリを種に、異なる視点から複数のクエリをLLMで生成することで、クエリを拡張して文章検索ができる。ソースを見た感じ、各クエリの検索結果は、重複を省いてマージされる。
RAG Fusion:Query expansionの一種。拡張した複数個のクエリで検索する際、各クエリの検索結果をreciprocal rank fusionでマージする。実装は、このリンクに乗っている。極めてシンプル。RAG FusionはMultiQueryRetrieverの強化版という印象。
その他、所感として、わかりみが深いコメントも多い記事であった。
retrieval may produce different results due to subtle changes in query wording or if the embeddings do not capture the semantics of the data well.
このコメントに共感して、上二つをピックアップ。
There is no "one-size-fits-all" solution because different problems require different retrieval techniques
RAGは、問題ごとに試行錯誤が必要。試行錯誤するために、RAGを評価する枠組みが必要。Ragasというライブラリが良いらしく、OpenAI DevDayの動画でも言及があった。
11. A Guide on 12 Tuning Strategies for Production-Ready RAG Applications
Ingestion ステージ(ドキュメントのベクトル化)とInferencing ステージ (Retrieval & Generation)に分けて、RAGのアウトプットを改善する方法を紹介している。紹介されている内容に目新しいものはあまりないが、それぞれのステージの模式図が非常に洗練されているので、そこだけでも一見の価値あり。
内容で気になったのは、ベクトル検索用のインデキシングアルゴリズム。これが、チューニング可能であると紹介されていた。実際のところ、VectorDBの開発者がすでに調整している部分なので、チューニングすることはあまりないと考えられる。チューニングをしたいならば、以下の記事を読むのが良いとのこと。
この記事も気になるのでどこかで読みたい。
12. LlamaIndex Talk (Snowflake BUILD 2023)
LlamaIndex Talk (Snowflake BUILD 2023) の発表スライド。
RAGによるQAの精度を上げるための方法が記載されていた。
RAGにおける表の取り扱いどうするのが良いかなと悩んでいたので、Recursive Retrievalが気になった。
動きとしては、次の手順1、2をやっているみたい。
手順1:テーブルを要約するテキストを作成し、テーブルを直接検索するのではなく要約テキストを代わりに検索の対象とする。
手順2:要約テキストが検索に引っかかった場合、テーブルの中身も併せて返却する。
13. オープンな日本語埋め込みモデルの選択肢
日本語埋め込みモデルとして以下のモデルが紹介されていた。
・⽇本語SimCSE
・GLuCoSE
・JaColBERT(bclavie/JaColBERT)
また、多言語埋め込みモデルとして以下のモデルが紹介されていた。
・Multilingual-E5
最後のスライドに、今回拾えなかったトピックに関するスライドがあり、以下の言及があった。
• 本来、2つの⽂の類似度計算と、クエリ・ドキュメント間の類似度計算は別物なので、それぞれに適した埋め込みを作るべき
• Multilingual-E5 でも実は⼊⼒⽂に “query:” “document:” というプロンプトを⼊れて、2つを識別できる
• この⽅針をさらに推し進めたのが instructor-embedding [8] で、⾊々なプロンプトを⼊れてタスクごとに埋め込みを最適化できるらしい
●ポチ一つ目は同意見。二つ目、三つ目は知らなかった。二つ目はすぐに使えるテクニックだと思う。このテクニックを使うかどうかでどの程度Retrieval性能に影響が出るか知りたい。
以下、紹介されていたモデルについてメモ。
■SimCSE
SimCSE(Simple Contrastive Learning of Sentence Embeddings)は、現在(2024/01)の埋め込みモデルのベースラインとのこと。
SimCSEの名前だけ見て、Contrastive LearningをしているSentenceBERTとそんな変わらないかと思っていたけど、そうではないよう。
Contrastive Learningで埋め込みモデルを作った事例をみて、文埋め込みの理解を深めていきたい。
●事例
・A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-wise Perspective in Angular Spaceの論文紹介
・【論文紹介】SimCSE: Simple Contrastive Learning of Sentence Embeddings
・[輪講資料] SimCSE: Simple Contrastive Learning of Sentence Embeddings
・Contrastive Learning超入門
・https://speakerdeck.com/hpprc/lun-jiang-zi-liao-simcse-simple-contrastive-learning-of-sentence-embeddings-823255cd-bd1f-40ec-a65c-0eced7a9191d
■GLuCoSE
Hugging Face上のモデルのReadme 引用。
GLuCoSE (General LUke-based COntrastive Sentence Embedding, "ぐるこーす")はLUKEをベースにした日本語のテキスト埋め込みモデルです。汎用的で気軽に使えるテキスト埋め込みモデルを目指して、Webデータと自然言語推論や検索などの複数のデータセットを組み合わせたデータで学習されています。文ベクトルの類似度タスクだけでなく意味検索タスクにもお使いいただけます。
■JaColBERT
全く知らなかったので、このモデルの論文の内容もチェックしつつ、詳しめにメモ。
・モデルの特徴
日本語に特化した文章検索モデル。
bert-base-japanese v3をベースに、ColBERT(Contextualized Late Interaction over BERT)のアーキテクチャを採用している。
ColBERTのアーキテクチャは、以下の図の右端((d) Late Interaction)。
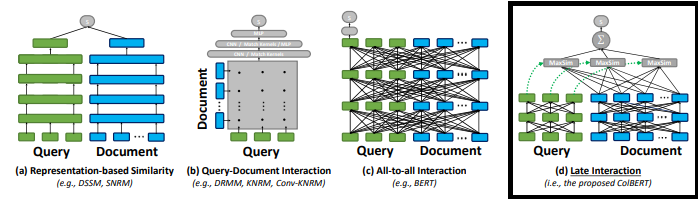
図 ColBERTとその他埋め込みモデルのアーキテクチャ(ColBERTの論文から引用)
Cross Encoder((c) All-to-al Interaction)とは異なり、Documentのトークンをストアしておけるので、Cross Encoderに比べると、計算コストは低い。
・学習データ
日本語版MARCOデータセットのハードネガティブ拡張版。
MS MARCO(Microsoft MAchine Reading COmprehension)は、Bingユーザーのクエリ(検索?)とクエリに関連する文章、そしてクエリに対する人が生成した回答をまとめられたデータセットである。
具体例は、以下のデータ。
{
"answers":["A corporation is a company or group of people authorized to act as a single entity and recognized as such in law."],
"passages":[
{
"is_selected":0,
"url":"http://www.wisegeek.com/what-is-a-corporation.htm",
"passage_text":"A company is incorporated in a specific nation, often within the bounds of a smaller subset of that nation, such as a state or province. The corporation is then governed by the laws of incorporation in that state. A corporation may issue stock, either private or public, or may be classified as a non-stock corporation. If stock is issued, the corporation will usually be governed by its shareholders, either directly or indirectly."},
...
}],
"query":". what is a corporation?",
"query_id":1102432,
"query_type":"DESCRIPTION",
"wellFormedAnswers":"[]"
}
ハードネガティブは、平たく言えばポジティブと見分けがつきにくい、ネガティブ(のはず)。
・学習方法
学習時には、この日本語版MARCOデータセットのハードネガティブ拡張版から、1000万個の(Query,PositivePassage,NegativePassage)のトリプレットをランダムにサンプリングしている。
1000万個と聞くと、莫大な数だと思うかもしれないが、多言語埋め込みモデル(おそらくMultilingual-E5のこと)よりも2桁以上小さい数。多言語埋め込みモデルの学習に使われたデータ量が多すぎる。
・性能
日本語埋め込みモデルの中では、JaColBERTが文章検索系のタスクで高い性能を示している。
多言語埋め込みモデル(m-e5)を含めると、MIRACLやMrTyDiでJaColBERTよりm-e5の方が良い結果を出しているが、m-e5-small/baseに対しては肉薄した結果を見せている。多言語埋め込みモデル(Multilingual-E5)は、MIRACLやMrTyDiの訓練データで学習済みという話があり、それでも勝負になっているのは、JaColBERTの性能の高さを物語っている。
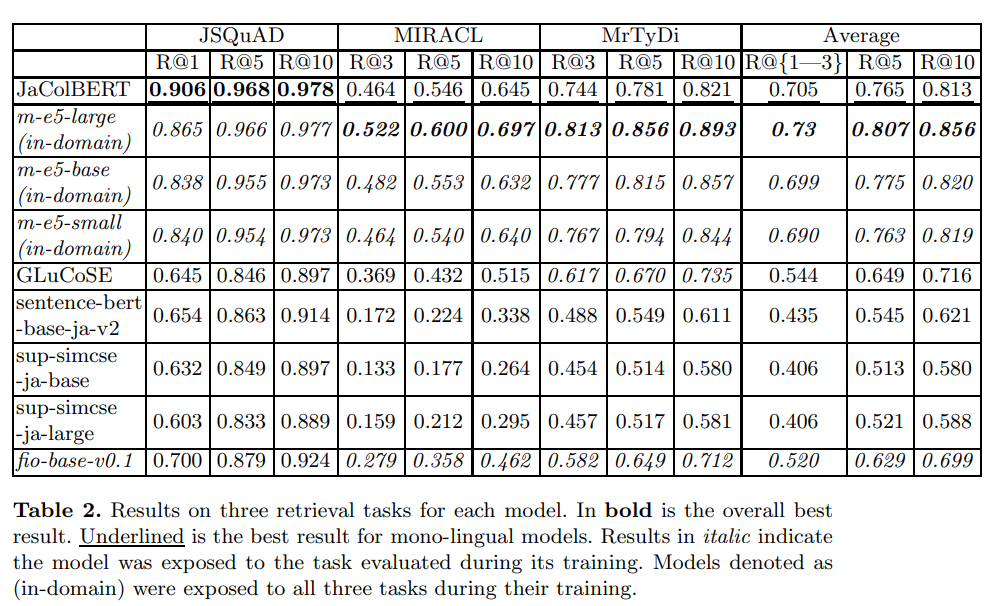
図 文章検索系のタスクにおける日本語埋め込みモデルや多言語埋め込みモデルの結果(参考論文の図2)
■Multilingual-E5
多言語の埋め込みモデルで、Microsoftが開発したとのこと。
論文は、こちら。Text Embeddings by Weakly-Supervised Contrastive Pre-training
XLM-RoBERTaをベースに、WEB上のデータから似ているドキュメントのペアかき集めて、2段階の学習を行って作成された。
1段階目は、ラベルがないデータで対照学習を行い、似たペアとそうでないペアを区別する能力をモデルへ身につけさせた。2段階目は、人がラベル付けしたデータ(NLI(Natural Language Inference), MS-MARCO passage ranking dataset, and NQ (Natural Questions) dataset)でファインチューニングすることで、モデルの性能をより向上させた。ファインチューニングでは、特にハードネガティブに着目し、ハードネガティブを見分けられるように学習させていた。また、同時に、教師モデル(Cross-Encoder)を用意し、教師モデルの出力の分布から大きくずれないように損失関数が設計されていた。
学習やRetrieve系のベンチを回すにあたり、ペアとなる文の片方にquery:、もう片方にpassage:というプレフィックスがつけられていた。これは、「オープンな日本語埋め込みモデルの選択肢」の最後のスライドにあった「Multilingual-E5 でも実は⼊⼒⽂に “query:” “document:” というプロンプトを⼊れて、2つを識別できる
」に対応していると思われる。
OpenAIのEmbedding モデルとE5で、学習方法・データ・モデルアーキテクチャにどの程度違いがあるのか、わかる範囲でいいので知りたくなった。