はじめに
ChatGPTのような生成AIの発展により、「テキストから画像」「画像から音声」といった生成が気軽に行えるようになりました。ところで、全く別のメディアの情報をどのように結びつけているのでしょうか?これは近年流行りの対照学習(Contrastive Learning)で実現しています。
今回はstable diffusionにも使われるCLIPのなんとなくな理解を最終ゴールに設定し、簡単ですが対照学習の目的と仕組みを説明していきます!生成AIを使い始めたけれども、中身がよくわらかずモヤモヤされている方のお役に立てば幸いです。
※概念理解に重きを置くため、今回は数式を載せていません。
目次
- 対照学習の目的
- 対照学習のイメージ図
- 自然言語処理における対照学習
- マルチモーダル学習における対照学習(CLIPはココ!)
- 画像生成時にテキスト情報を組み込む
対照学習の目的
一般的に機械学習ではテキストや画像はベクトル(埋め込み/embedding/representation)として扱います。もしベクトル空間において、似た意味の文章(画像)が似たベクトルになっていたら直観的にも便利そうですよね。例えば、とある顔画像が誰であるか分類する場合、同一人物でも撮影環境によって写真内の顔が変わってしまいますが、同じ人の写真が同じようなベクトルにすることができれば誤分類を防ぐことが期待できます。これ以外にも推薦システムであったり、文書検索などに活用されています。このように対照学習は似たものは似たベクトルにすることを目指します。
対照学習のイメージ図
ではどのように対照学習は行われるのでしょうか?よく使用されるlossであるTriplet Loss(3つ組損失)の仕組みを通して説明します。覚えておくべきものは「アンカー(基準となるもの)」「正例(アンカーに似たもの)」「負例(アンカーに似てないもの)」の3つです。以下の図で示す通り、ベクトル空間においてアンカー(水色)と正例(緑色)は近づくように、アンカーと負例(赤色)は遠ざけるように学習します。
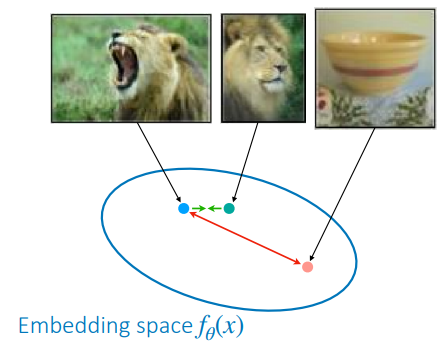
CS 330: Deep Multi-Task and Meta Learning, Fall 2023, Week 5の講義資料より引用
自然言語処理における対照学習
では実際に対照学習を使用するモデルをいくつか見てみましょう。筆者が自然言語処理の研究室に所属しているため、自然言語処理で代表的な手法である「Sentence-BERT」「SimCSE」「Sentence-T5」の3つを説明します。RAGに取り組まれている方は見たことがあるモデルかもしれませんね。
Sentence-BERT
図はTriplet Lossを用いる場合です。まずアンカー/正例/負例それぞれをEncoder(BERTなど)に通してベクトル(Embedding)を獲得します。そして、アンカー-正例間の距離とアンカー-負例間の距離を測り、さらにその距離同士の差を最大化するように学習します。ちょっとややこしいですが、アンカーと正例を近づけ、アンカーと負例を遠ざけています。
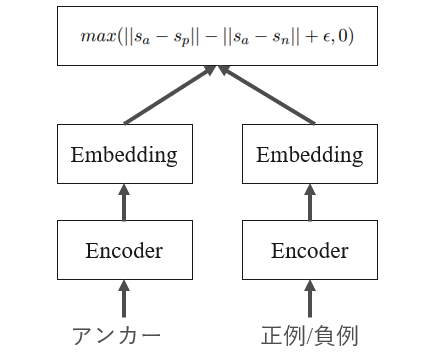
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networksをもとに筆者作成
SimCSE
SimCSEには教師なしSimCSEと教師ありSimCSEがあります。教師なし学習においてどうやって正例/負例を作るのか疑問が浮かぶかと思いますが、ある文章をアンカーとしたときアンカー自体を正例に、バッチ内に含まれるアンカー以外の文章をすべて負例にします(バッチ内負例)。一方教師ありSimCSEでは、ある文章をアンカーとしたときアンカーに近い意味の文章を正例、遠い意味の文章を負例とします。学習データとして自然言語推論(NLI, 含意関係認識)用データセットがよく使用されます。教師ありSimCSEも同様にバッチ内負例が使用でき、バッチ内の他のデータはすべてアンカーの負例として扱います。(この図を初めて見たときぱっと見よくわからなかったのですが、90度回転させてみるとSentence-BERTの図にちょっと近づきます。)
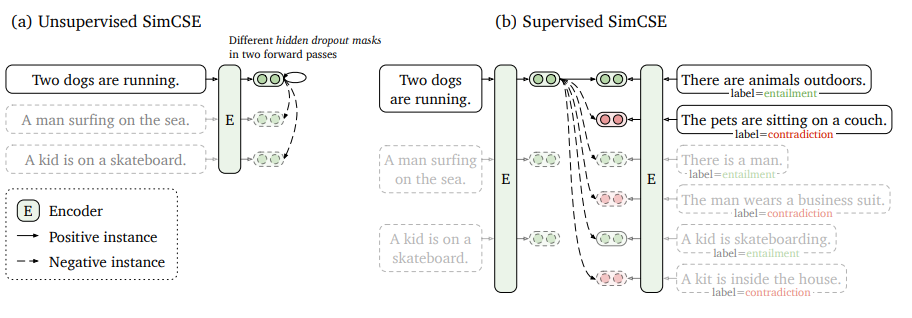
SimCSE: Simple Contrastive Learning of Sentence Embeddingsより引用
※教師ありSimCSEの図にあるlabel(entailment/contradiction)はそれぞれ含意/非含意を表します。前提文(アンカー)を真としたときに、ある文章(仮説文)が言えるかどうかで含意/非含意が割り当てられます。
Sentence-T5
上記2つに比べてあまりメジャーではありませんが、Encoder-Decoderモデル(T5)で対照学習した事例もあるためご紹介します。1つ目の図のとおり、これまで同様に文章のEmbeddingを取り出して距離学習を行います。アンカーと正例は近づけ、バッチ内の他のデータを負例としてアンカーとの距離を遠ざけます。
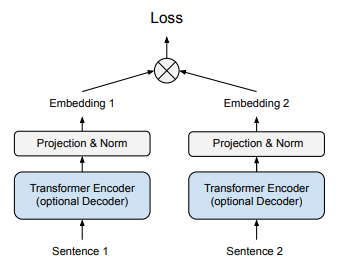
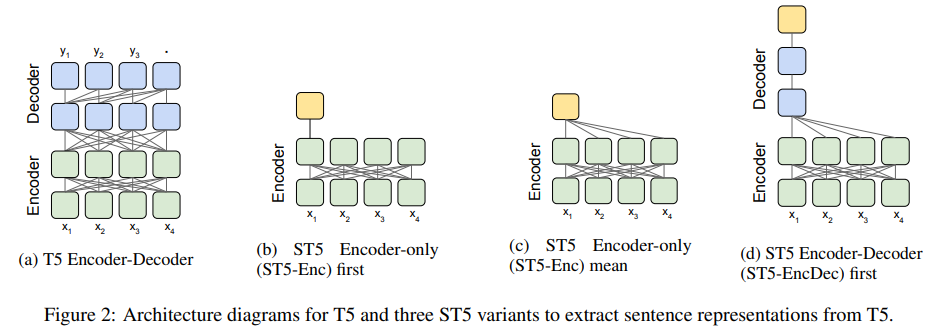
※2枚目の図はEncoder-DecoderアーキテクチャのどこからEmbeddingを取り出せばいいか色々調べられた図になります。対照学習含めた2段階のfine-tuningの結果、(c)が良かったようです。
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Modelsより引用
マルチモーダル学習における対照学習
それでは最後にマルチモーダルに対照学習を行った事例(CLIP)をご紹介します。考え方は上記とほとんど同じですが、CLIPに関しては誤解を恐れずに言えば「同じ意味の画像と言語のベクトルを近づける」対照学習を行います。まず画像とそれを説明したテキストのペアを用意します。次にテキストと画像ごとにEncoderを用意します。画像であればResNetやVision Transformerが実験で使われました。そしてバッチ内の画像とテキストをそれぞれのEnocoderに通してEmbeddingを得たのち画像とテキストのEmbeddingそれぞれの内積を計算します(テキスト:T1...Tn, 画像:I1...In)。図のように対角線上には同じものを表したベクトル通しの内積であるため正例にあたり、それ以外は別のものを表したEmbedding同士のペアになるので負例となります(バッチ内負例)。あとは正例の類似度(内積)を高く、負例の類似度を低くするように学習するだけです。以上の学習を終えると「犬」と犬の画像のベクトルが近づいたため、犬の画像と「A photo of a {object}.」というテキストをモデルに入力した際「A photo of a dog.」と出力するようになります。
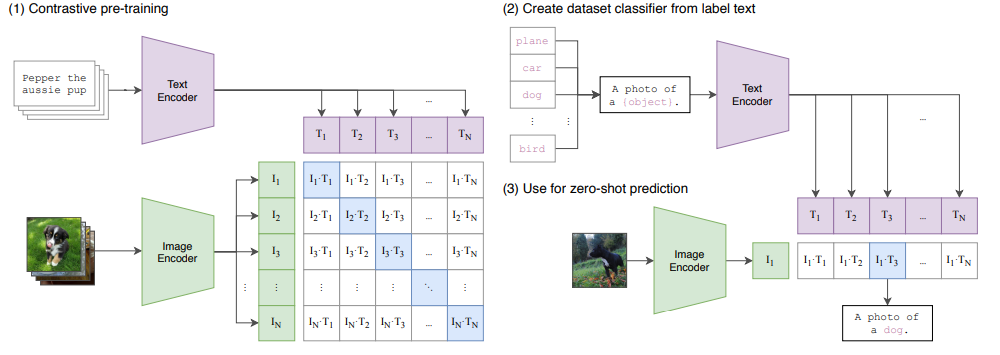
Learning Transferable Visual Models From Natural Language Supervisionより引用
Stable DiffusionでのCLIPの使われ方
さて、同じベクトル空間上で似た意味の画像と言語が似たベクトルを持つように訓練されました。最後に画像生成AIであるStable DiffusionでのCLIPの使われ方を見て、タイトルである「なぜテキストから画像が生成できるのか」に答えていきます。stable diffusionは画像にノイズを加える「拡散過程」とノイズを除去していく「逆拡散過程」に分けられます(詳細は割愛)。重要なのは図の「Conditioning(条件付け)」という箇所です。テキスト(画像も可)をCLIPをに通してEmbeddingを取得し、画像生成過程(逆拡散過程)とCross-Attention(条件付け)します。そうすることで言語情報を考慮しつつ画像生成が行われるため、テキストに沿った画像を生成できるようになります。
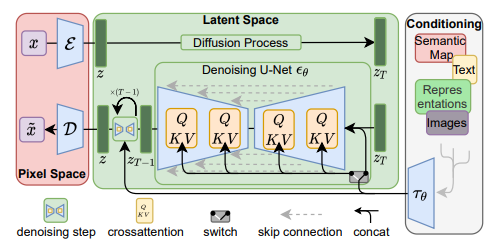
High-Resolution Image Synthesis with Latent Diffusion Modelsより引用
おわりに
以上、駆け足でしたが対照学習の目的からマルチモーダルAIの簡単な説明をさせていただきました。ここまで読んでくださりありがとうございました!