Microsoft は 18 日、Azure Cognitive Search を用いた RAG システムの定量的評価結果を公表し、Azure Cognitive Search 独自の検索機能である、セマンティックハイブリッド検索(ハイブリッド+セマンティックランカー)が最も高い品質を示すことが分かりました。また、チャンク分割戦略についての参考になるインサイトも提供しています。
Azure Cognitive Search のセマンティックハイブリッド検索の解説はこちらを参照ください。今回用いる用語の簡単な解説は以下です。
- ハイブリッド検索:BM25 ベースのキーワード検索とベクトル類似度検索結果のそれぞれ上位 50 件を、RRF を使用して結果を統合します。
- ハイブリッド+セマンティックランカー:ハイブリッド検索の結果上位 50 件を、リランク(並び替え)て新たにスコアを生成しています。本記事ではセマンティックハイブリッド検索の事を指します。
評価結果
精度の評価には、顧客データセット(許可済)、BEIR、Miracl を使用して比較しています。
検索モードの比較
-
セマンティックハイブリッド検索が最もランキング品質(NDCG@3)が高かった
- 品質はセマンティックハイブリッド>ハイブリッド>ベクトル>キーワードの順で高い
- 9 種類の検索クエリーに対して、セマンティックハイブリッド検索が最も NDCG@3 が高かった
チャンク分割の比較
- チャンク化あり・なしの比較ではチャンク化ありのほうが Recall@50 が高かった
- チャンクサイズが小さいほど Recall@50 が高かった
- チャンク間の重複を 25%, 512 トークンが最も Recall@50 が高かった
- セマンティックハイブリッド検索が最も欲しいチャンクを返す
詳細:検索モードの比較
1. セマンティックハイブリッド検索が最もランキング品質(NDCG@3)が高かった
各評価データで検索モードごとにランキング結果の品質を評価し、高品質なドキュメントをどれだけ適切に提示できるかを NDCG@3と NDCG@10 で比較しています。以下の表から、品質はセマンティックハイブリッド>ハイブリッド>ベクトル>キーワードの順で高いことが分かります。(出典)
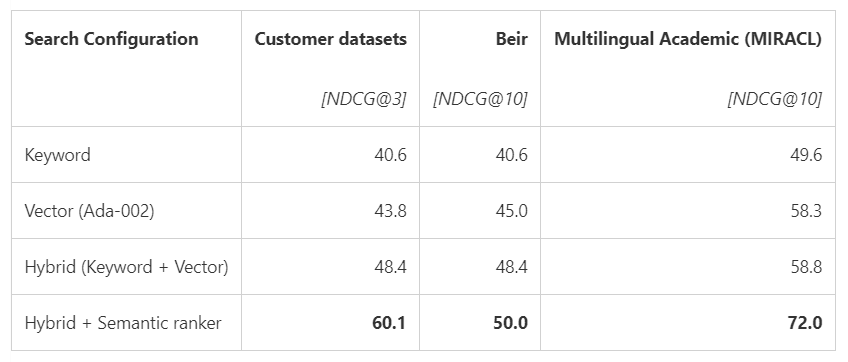
Multilingual Academic(MIRACL) データセットにおけるセマンティックハイブリッド検索のスコアが非常に高いのは、先日最新モデルにアップデートしたのが影響しているのでしょうか。この点の記載は見当たりませんでした。あとキーワード+セマンティックランカーの組み合わせデータが無いですが、こちらも気になるところです。
2. 9 種類の検索クエリーに対して、セマンティックハイブリッド検索が最も NDCG@3 が高かった
まず投入したクエリの分類方法が非常に参考になります。以下の表では、キーワードクエリのみがベクトル検索で著しく低く、重要単語のみで検索をかけるシナリオでのベクトル検索のみの利用はこの評価データでは適さないということが分かります。この場合、ベクトル検索が低くてもハイブリッド検索およびセマンティックハイブリッド検索では RRF の採用によってランキングを浮上させることが可能です。キーワードクエリ以外のクエリーはすべてセマンティックハイブリッド検索の結果が最も高くなっています。(出典)
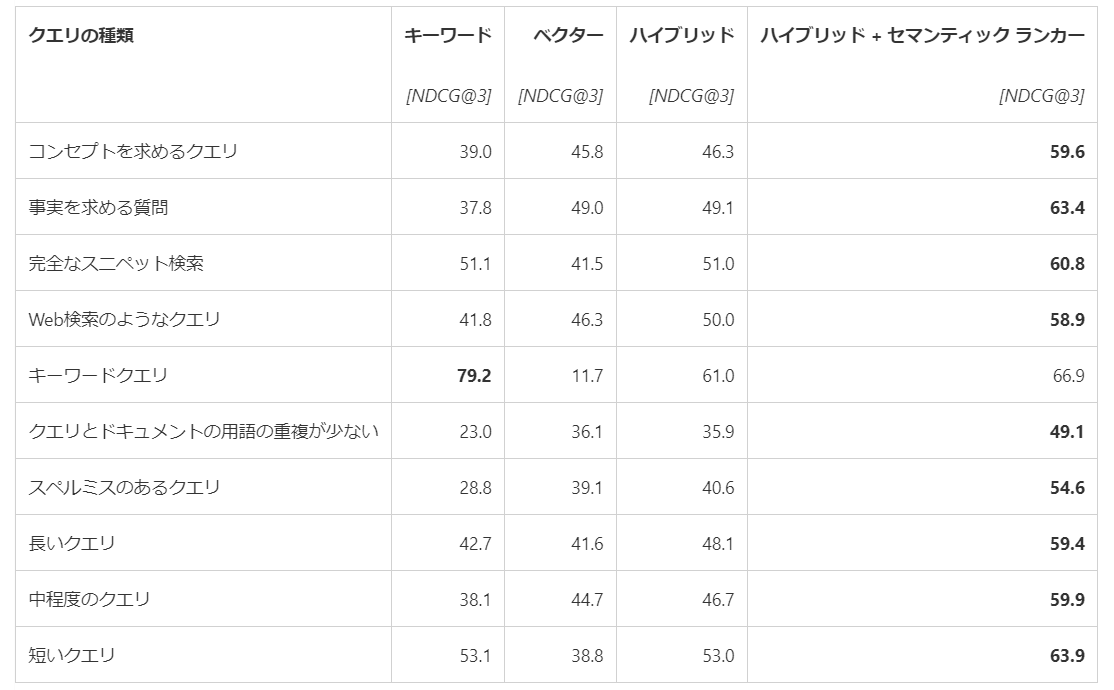
クエリとドキュメントの用語の重複が少ない(言い換え)、スペルミスのあるクエリがキーワード検索では低く、ハイブリッドやセマンティックハイブリッド検索で品質が向上することが定量的に示されました。また、コンセプトを求めるクエリのような検索者の意図を汲んで回答する必要があるケースでも有効であることが分かります。以前私が Azure OpenAI Developers セミナー第2回 で行ったデモのとおりの結果になったと言えます。
詳細:チャンク分割の比較
ドキュメントを text-embedding-ada-002 モデルでベクトル化する前に適切なチャンク化を行うことにより Recall@50 が高くなることが示されました。
1. チャンク化あり・なしの比較ではチャンク化ありのほうが Recall@50 が高かった
チャンク化あり・なしでの比較結果。クエリに対してドキュメントがどれくらい適合するかを表す Recall@50 を使って比較しています。Recall ですので上位 50 件にどれくらい検索漏れがあるかを見ています。上位 50 件の中に欲しい結果が入ってさえすれば、あとはセマンティックランカーが高品質な並び替えを実行します。

ドキュメントごとに単一ベクトル:各ドキュメントの最初の 4,096 個のトークンがベクトル化され、残りを切り捨て
チャンク化されたドキュメント:各ドキュメントを25% 重複する 512 個のトークン チャンクに分割した顧客のクエリ/ドキュメントを text-embedding-ada-002 でベクトル化
トークン上限を超えるものを切り捨てているので、そりゃそうか という感じです。
2. チャンクサイズが小さいほど Recall@50 が高かった
顧客のクエリ/ドキュメント ベンチマークに対する text-embedding-ada-002 モデルを使用したさまざまなチャンク サイズの Recall@50 比較。512 トークンで区切ったチャンクが最も Recall@50 が高いという結果になりました。(出典)

3. チャンク間の重複を 25%, 512 トークンが最も Recall@50 が高かった
顧客クエリ/ドキュメント ベンチマークに対する、text-embedding-ada-002 モデルを使用、512 トークン固定したさまざまなチャンク境界戦略の Recall@50 比較。チャンク間の重複を 25%, 512 トークンが最も Recall@50 が高いという結果になりました。(出典)

以前チャンク化を LangChain でやったところ overlap が日本語では機能しなかった記憶があります。自然な文と段落の境界でチャンクを区切ってベクトル化することも推奨されていますから、日本語向けにその辺の処理を書いてしまったほうがいいかもしません。
4. セマンティックハイブリッド検索が最も欲しいチャンクを返す
ここまでの評価によってドキュメントのチャンクは 512 トークンで、25% の重複が良い結果を示すことが分かりました。この条件を使って、検索結果上位1~5件(横軸)ごとに高品質とラベル付けしたチャンクが含まれる割合を検索モードごとに比較したグラフが以下です。(出典)
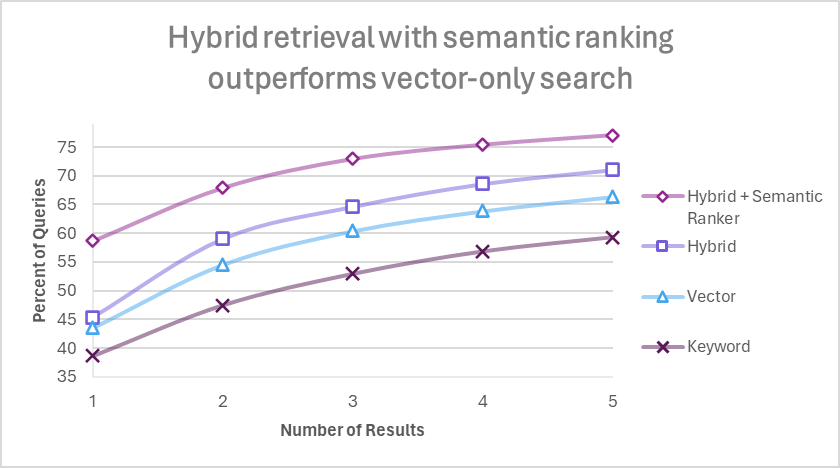
この評価結果によって、チャンクは 512 トークンで、25% 重複させること。検索結果は上位 5 件として、セマンティックハイブリッド検索を使って検索することが最も高品質な結果が得られるということが分かりました。512 x 5 = 2,560トークン分のテキストを回答を生成する LLM の入力にすればよいということですね。
注意
セマンティックハイブリッド検索のセマンティックランカーは Microsoft 製の LLM である Turing モデルを使って、ハイブリッド検索の上位 50 件を並び替えます。この処理があるため、通常のキーワード検索よりもクエリーの実行時間が長くかかり、処理が重くなりますので精度とパフォーマンスのバランスを考慮した実装が必要です。
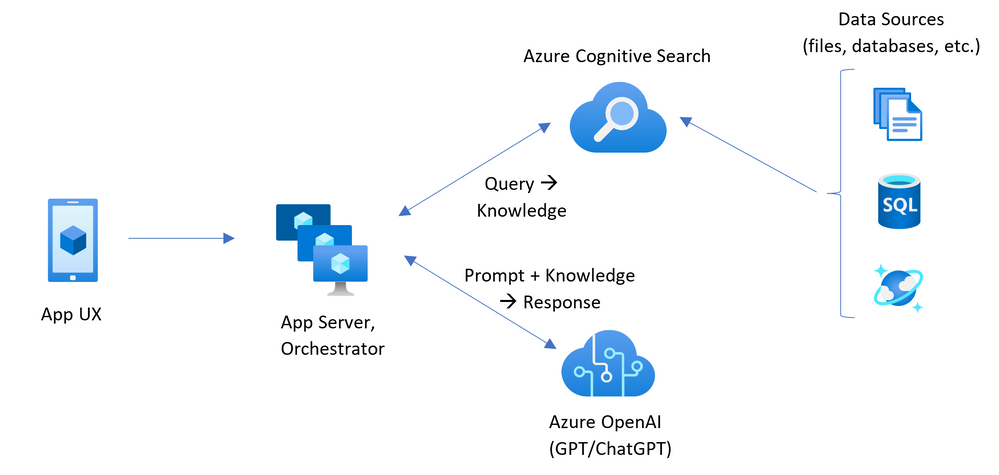
また、この評価ではユーザーからのクエリーをダイレクトに言語アナライザーに解析させるのではなく、いったん GPT モデルを利用した検索クエリーを生成してから検索しています。これは例のアーキテクチャと同様の実装となっていますが、実際に用いたプロンプトによって検索結果が変わるため、実際に使用するデータでの検証が重要です。
参考