原論文
MLP-Mixer: An all-MLP Architecture for Vision
https://arxiv.org/pdf/2105.01601.pdf
日本語解説
【MLP-Mixer】MLPがCNN,Transformerを超える日
https://ai-scholar.tech/articles/image-recognition/mlp-mixer
結論
ViTのSAをMLPに変更しても精度はあまり変化なかった.
概要
画像認識分野ではスタンダードモデルとしてCNNとViTがある.しかし,成功の秘訣はCNNにあるのか?ViTにあるのか?それとも全く違う場所にあるのか??そこで,CNNでもViTでもないMLPを使用するとどうなるのかを検証する.
そこで,ViTのSAをMLPに置き換える.これにより,十分な量のデータセットと正規化手法を用いることでViTを超える精度を達成した.これにより,成功の秘訣はCNNやViT,MLPには依存しないことが分かった.
モデル構造
モデル構造を以下に示す.Mixer Layerの部分の具体図を上図に示す.
上図のMixer Layerでは,前半に特徴量の空間方向を認識する処理(Token-mixing MLP),後半にチャンネル方向を認識する処理(channel-mixing MLP)をする.上図のMLP1,2の具体的な構造は右下に示す.
また,空間認識の際,特徴量を転置してMLPを通している.これは,ViTのTransformer Encoderと似ており,SAは空間認識,FFNはチャンネル認識をする空間→チャンネル認識する構造であり,構造は変更せずに認識方法を変更している.

以下を式で示す.上段がToken-mixing MLPであり,下段がchannel-mixing MLP)の式である.
\begin{align}
U∗,i = X∗,i + W2 σ (W1 LayerNorm(X)∗,i), \\
Yj,∗ = Uj,∗ + W4 σ (W3 LayerNorm(U)j,∗),
\end{align}
入力がXであり,σはGELUを示す.各MLPはGELUを間に2層のMLPで構成され,各MLPにスキップ接続を使用する.
結果
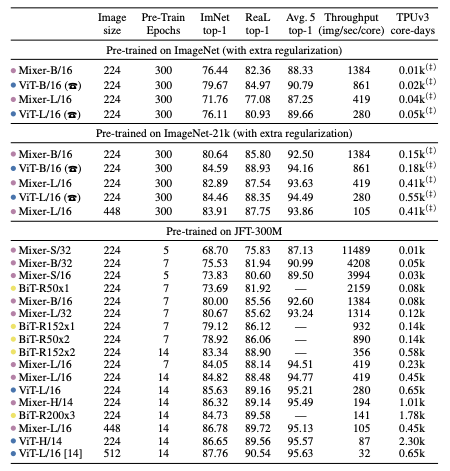
様々なサイズのデータセットで検証する.ピンクがMLP系,青がViT系,黄色がCNN系のモデルであり,超大規模データセットのJFT-300MのMLP系精度はViT系と比較して高い傾向にある.
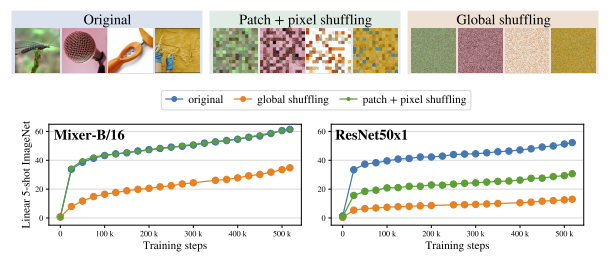
入力画像のパッチ位置とパッチ内のピクセルをシャフルした場合の精度を示す.通常の画像での精度を青,シャッフルを緑で示す.MLP系のMixerは精度低下しない.反対にResNetは,青と比較して緑の精度が大きく低下する.これは,ResNetは位置による強い帰納的バイアスがあるため,パッチが入れ替わると著しく精度低下すると考える.
また画像全体をピクセル単位でシャフルした場合でも,オレンジのResNetは20%以下になるが,MLPは30%以上を保持している.これらにより,MLPはシャフルに強いことが分かる.
まとめ
今回は,MLP-Mixerについて説明した.ViTのSAではなく,MLPで空間認識しても精度はあまり変わらずに大規模データセットで高精度になることが分かった.CNN,ViT,MLPは空間認識でそれぞれの得意不得意タスクがあるので,適材適所で使用することが大切だと思う.