原論文
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
https://arxiv.org/abs/1704.04861
MobileNetV2: Inverted Residuals and Linear Bottlenecks
https://arxiv.org/abs/1801.04381
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
https://arxiv.org/abs/1707.01083
Searching for MobileNetV3
https://arxiv.org/abs/1905.02244
日本語解説
MobileNet(v1,v2,v3)を簡単に解説してみた
https://qiita.com/omiita/items/77dadd5a7b16a104df83
MobileNet(v1/2)、ShuffleNet等の高速なモデルの構成要素と何故高速なのかの解説
https://qiita.com/yu4u/items/dc26d220e85279e76157
関連研究
Mobile ViT系
概要
深層学習モデルは,より複雑な表現を獲得するために,モデルサイズを大きくする従来研究がある.しかし,それらのモデルは計算機の大きさが制限されている組み込みデバイスには適していない.そこで,モデルサイズを小さいままでより高い精度を目指す.これにより,スマホで計算可能な軽量モデルを実現する.
Mobile Net-v1
通常の畳み込み処理の計算量を削減するために,畳み込みを空間方向とチャンネル方向に分けて2段階で計算する.
以下の図は,処理の出力値に対して,情報処理に使用する入力値の関係性を示す.簡単のために,空間方向は1次元のみを可視化する.

通常の畳み込みの場合,空間とチャンネル方向に情報収集する.この線が学習可能な重みである.


depthwise convは,空間方向のみ,conv1x1はチャンネル方向のみの処理をする.この様に,空間方向とチャンネル方向を分割して認識することにより,計算量を削減する.
式による計算量削減効果
通常の畳み込みの計算式
$$
D_{K} * D_K * M * N * D_F * D_F
$$
$D_{K}:カーネルの縦と横$
$M:入力チャンネル数$
$N:出力チャンネル数$
$D_{F}:入力特徴量の縦と横$
DWConvは,チャンネル方向の認識をしないので,チャンネル方向の計算(N)の計算量が削減され,
$$
D_{K} * D_K * M * D_F * D_F
$$
PWConvは,カーネルの空間サイズが1x1のため,カーネルの空間サイズ(D_{K} * D_K)の計算量が削減される.
$$
M * N * D_F * D_F
$$
Mobile Net-v1の計算量はDWConvとPWConvを合わせた量なので,通常の畳み込みと比較して,$\frac{1}{N} + \frac{1}{D_K^2}$の計算量の削減が期待できる.これは,精度を維持さながらも,通常の畳み込みと比較して8~9倍の計算量を削減している.
$$
\frac{D_K* D_K * M * D_F * D_F + M * N * D_F * D_F}{D_{K} * D_K * M * N * D_F * D_F} = \frac{1}{N} + \frac{1}{D_K^2}
$$
また,モデル構造は,階層型モデル構造を採用.階層のステージ間のダウンサンプリングは,ストライド2の畳み込みでダウンサンプリングする.最初の処理は,通常の畳み込みを採用して,線や角などの基本的な特徴を獲得する.
Mobile Net-v2
ResNetで採用されているResidual Blockは,計算量削減のため,真ん中の3x3Convに少ないチャンネル数を設定するボトルネック構造である.Mobile Net-v2で採用するInverted Residual Blockは,真ん中の処理のチャンネル数を拡大する逆ボトルネック構造である.
Mobile Net-v1は通常,大きいチャンネルを持ち,3x3畳み込みの際にチャンネル数を圧縮するが,
Mobile Net-v2は通常,小さいチャンネルを持ち,3x3DW畳み込みの際にチャンネル数を増加させる.
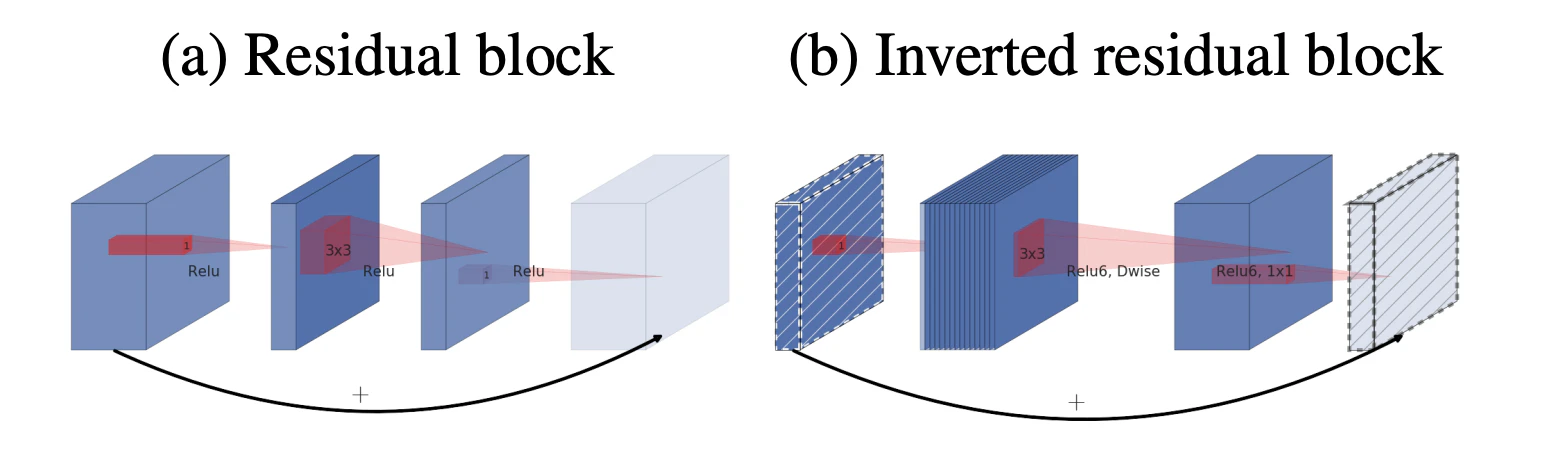
また,Mobile Net-v2は,Mobile Net-v1からも分かるように1x1convの計算量が多いことから,1x1convをさらに2つ分割して計算しているとも捉えられる.
depthwise convを使用することにより,チャンネルを拡大したとしても計算量を制限する.

これは,考え方を変更すると,1x1convの計算量が膨大なため,1x1convを低次元に圧縮して2段階で処理して計算量を削減しているとも捉えることができる.
計算量の削減効果として,入力と出力のチャンネル数Nとすると
通常の計算量(入力:N,出力:N) : $N^2$
MobileNetV2のように分割すると,
分割計算量((入力:N,出力:$\frac{N}{t}$)と(入力:$\frac{N}{t}$出力:N)) : $\frac{2}{t}N^2$
となり,拡張率t=6の場合に計算量が$\frac{1}{3}$になる.
ReLUのチャンネル数
ReLUの入力値が0以下の場合にその値を全て0にする処理で,正の値のみの情報で計算する仕組みである.これは,必要な情報を失われる可能性がある.
このReLUの弱点をチャンネル数が十分にあることで,情報が保存されている.チャンネル数を圧縮(ResNetのボトルネックなど)された際に,情報を保つことが困難になり,精度低下の可能性がある.
以下の画像は,入力にReLUを通した際の結果を示す.deimは次元数を示す.
次元数が小さい場合に,入力の特徴を失う傾向にあり,次元数が大きい場合に情報が維持される.

このことから,Residual blockのReLUを採用する中間層にチャンネル数を拡大して情報を損失しない様にする.
shuffle Net
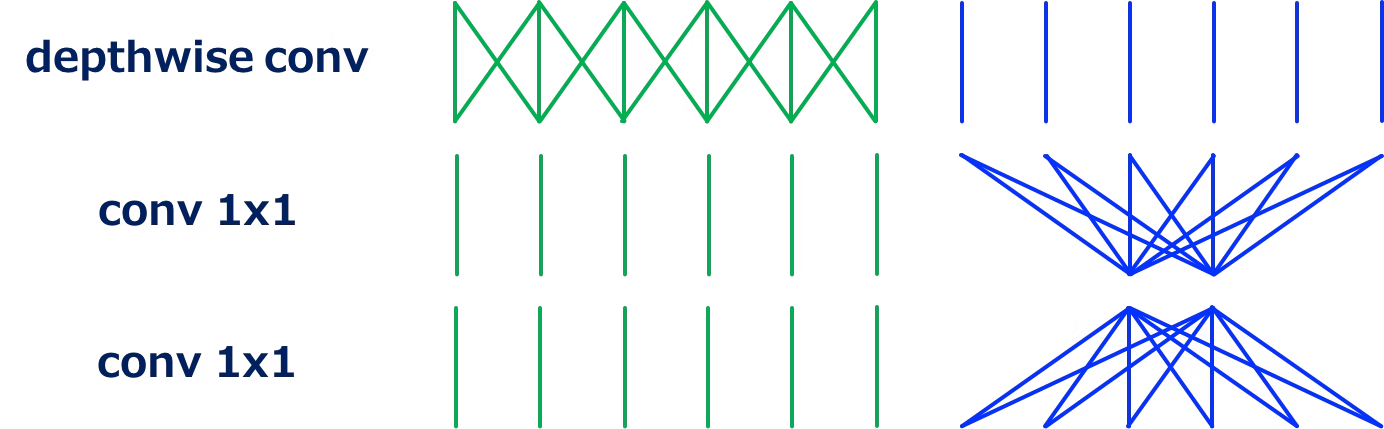
チャンネル方向の畳み込み(1x1Conv)の計算量を削減する.
そのために,グループ畳み込みを採用する.グループ畳み込みは,入力特徴量をチャンネル方向に分割し,その分割した特徴量別にカーネルを用意して畳み込みをする.その後,それぞれの出力特徴量をチャンネル方向に連結する.
以下に通常の1x1convと1x1のグループ畳み込みを示す.

1x1グループ畳み込みはチャンネル方向に(2つ)分割に分割して計算することで線が少なくなり,計算量が削減される.

また,分割するグループを増やすとさらに計算量が削減される.
しかし,1x1convの本来の目的として,チャンネル方向の情報を集約する目的があり,グループに分けたことによりチャンネル方向の情報を十分に取得することができなくて性能低下につながってしまう.
そこで,shuffle Netでは,チャンネルの順番を入れ替える(c shuffle)ことで効率よくチャンネル方向の情報を集約して計算する.

c shuffleを使用することで,その後の1x1グループ畳み込みで同一のチャンネルでグルーピングされるのではなく,前回とは別でグルーピングされたチャンネルの情報を集約できる.
Mobile Net-v3
Mobile Net-v2にSENetで提案されたSqueeze-and-Excitationモジュールを追加する.
以下にMobile Net-v3のブロックを示す.
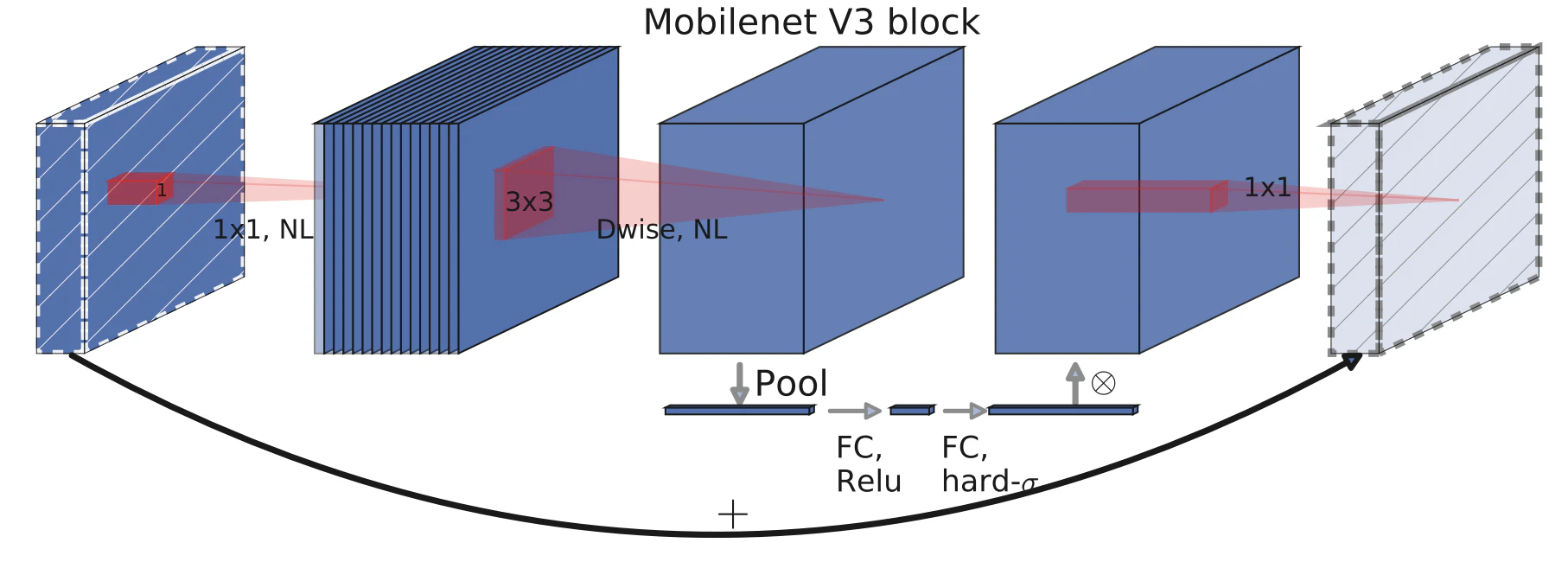
Squeeze-and-Excitationモジュール
Mobile Net-v3にSqueeze-and-Excitationモジュールを示す.
主な目的として,チャンネル毎に重要度を決定する.

特徴量のHxWxCを1x1xCに変換するために,Global Average Pooling(GAP)を使用する.GAPとは,以下に図を示し,各チャンネルの全画素の平均値を算出する.これにより,空間方向の値が1つの値になり,1x1xCの特徴量を獲得する.この特徴量を全結合層(FC層)を通してチャンネル毎の重要度を決定し,元の特徴量の重みをかける.
GAPの図
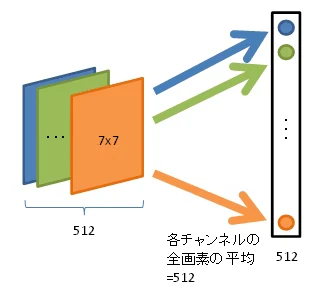
https://qiita.com/mine820/items/1e49bca6d215ce88594a
結論
MobileNet系のモデルは,通常の畳み込みから,接続する重みの線を効率よく削減し計算量を削減している.
採用される空間とチャンネルを分割して処理,グループ畳み込みなどは他の様々なモデルに採用されており,重要な仕組みである.