原論文
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
https://arxiv.org/pdf/2010.11929.pdf
はじめに
深層学習(AI)の自然言語分野で爆発的大革命を起こしたTransformerがある.この手法を画像分野に応用したモデルが,Vison Transformer(ViT)である.ViTは今日に至るまで超人気最強モデルとして採用されている.
ViT発表後,ViTの派生モデルや,ViTに特化した学習方法,ViTに特化したデータ拡張,ViTに特化した軽量化方法,ViTと差別化をするモデルなど,様々な論文が発表されている.
これらの論文を理解するためには,ViTの構造や特性を理解する必要がある.そこで,この記事はViTを誰でも簡単に理解できるように分かりやすく解説する.
ViTの理解が難しいポイント
ViTの説明をしている記事や論文はたくさんありますが,人によって計算方法の名前の呼び方が異なります.例えば,りんごの場合「りんご」「リンゴ」「林檎」「アップル」「赤い果実」「赤りんご」など,様々な呼び方があります.これらが一緒の意味なのか,別の意味なのかがわからなくなってしまうポイントです.
紹介する計算方法の色んな呼ばれ方も一緒に覚えてもらえば,色んなViT論文を読むにあたって素早く理解できるようになります.
※説明の中で,一般的な機械学習やCNNの知識が少し必要なところもあります.
画像認識分野の歴史
深層学習の画像認識分野において,畳み込み層とプーリング層と全結合層を持ったCNNが画像認識のスタンダードモデルとして使用されていた.しかし,Transformerの登場で,世は大Transformer時代に突入した.Transformeから派生し,画像認識に特化したVison Transformerを提案した.このViTの性能はCNNの性能を追い越す可能性があると次世代のスタンダードモデルとして注目されている.
モデル構造
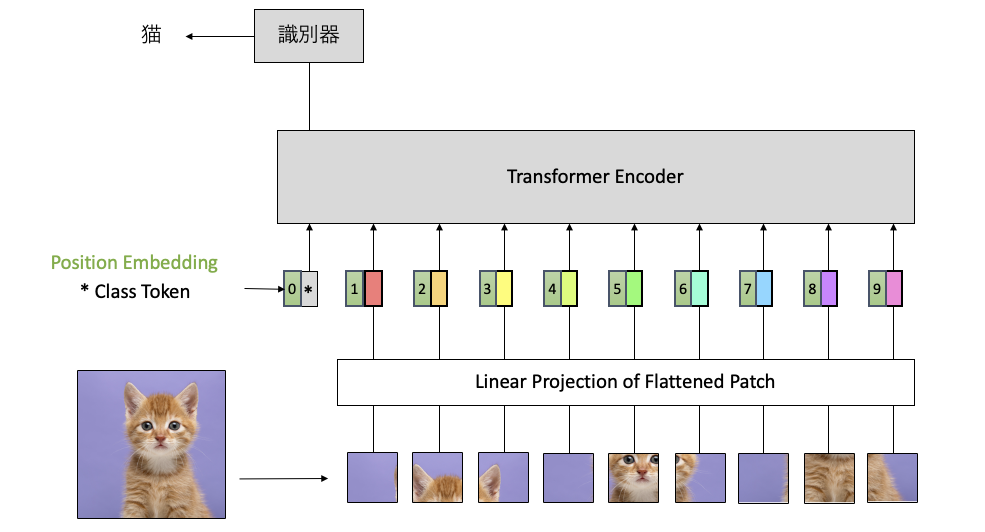
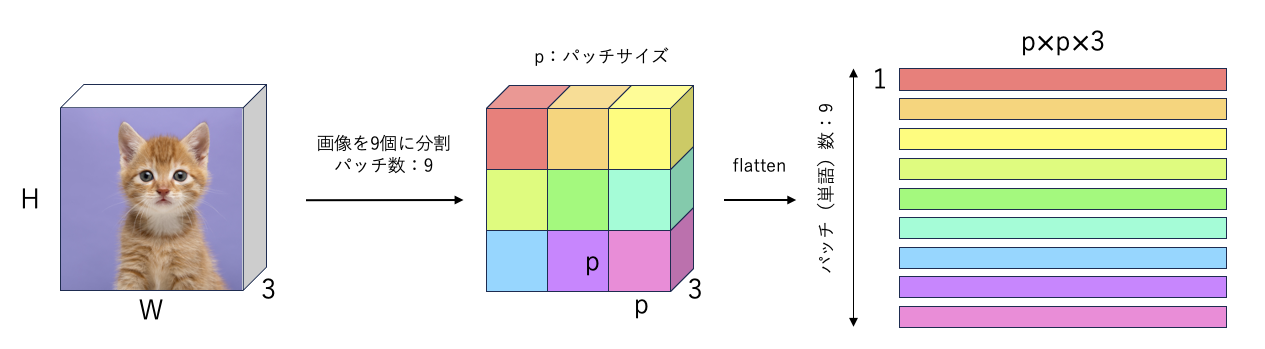
パッチ分割
- 小領域に分割
自然言語分野のTransformerの派生モデルであるため,画像を複数の単語(トークン)として扱うことで計算が可能になる.画像をどのように複数の単語にするかは,画像を分割して,それぞれを単語として扱う.
例えば,画像(3次元)を9個の単語として分割したい場合は,下図のように分割する.その際に,分割した小さな領域はパッチと呼ばれる.画像を縦3つ,横3つの9個のパッチに分割したので,1つのパッチのサイズは($H/3 \times W/3 \times C$).図では簡単のために$H/3 = W/3 = p$で表記する.
各パッチは,flatten(1次元化,平坦化)する($p \times p \times 3$).この1次元にされた状態をベクトルと呼ばれる.ベクトルが,パッチ数=9だけあるので,3次元の画像($H \times W \times 3$)が2次元の特徴量($ 9 \times (p \times p \times 3)$)を獲得する.
Linear Projection of Flattened Patches
- 線形射影
- Linear
- ベクトル変換
- 全結合層
各ベクトルでLinerしてるだけ.赤のベクトルを使って,新しい赤のベクトルを作成する.
Multilayer perceptron(MLP)の図で示すLinearと同じ.
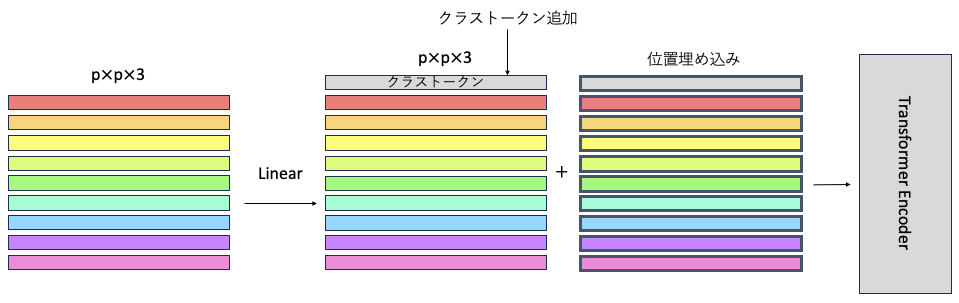
Class Token
クラストークンを特徴量に追加する.つまり,パッチ(単語=トークン)数が1つ増える.クラストークンでは,他のトークンが認識したことをいい感じに取り入れて,最後,クラストークンを用いて,最後の識別を行う.
Position Embedding
- positional encoding
- 位置埋め込み
ViTの構造に含まれるSelf-Attentionは,画像の情報を並列に計算する.その際に,ここと,ここが近い位置にあることや遠い位置にあることは計算に考慮してしない.近くの位置でも遠くの位置でも関係なく計算する.そのため,画像の位置情報を完全に無視して計算することになる.
これは,性能低下になる可能性があるため,位置情報を付与する.位置情報の数値を,各トークンに加算される.位置情報はクラストークンにも加算される.
Transformer Encoder
Transformer Encoderは,Multi-Head AttentionとMLPを交互に繰り返す構造である.
入力される特徴量は2次元サイズであり,Multi-Head Attentionは,縦の空間方向(各パッチの関係)を計算する.MLPでは,横の次元方向(パッチ内の情報)を計算する.
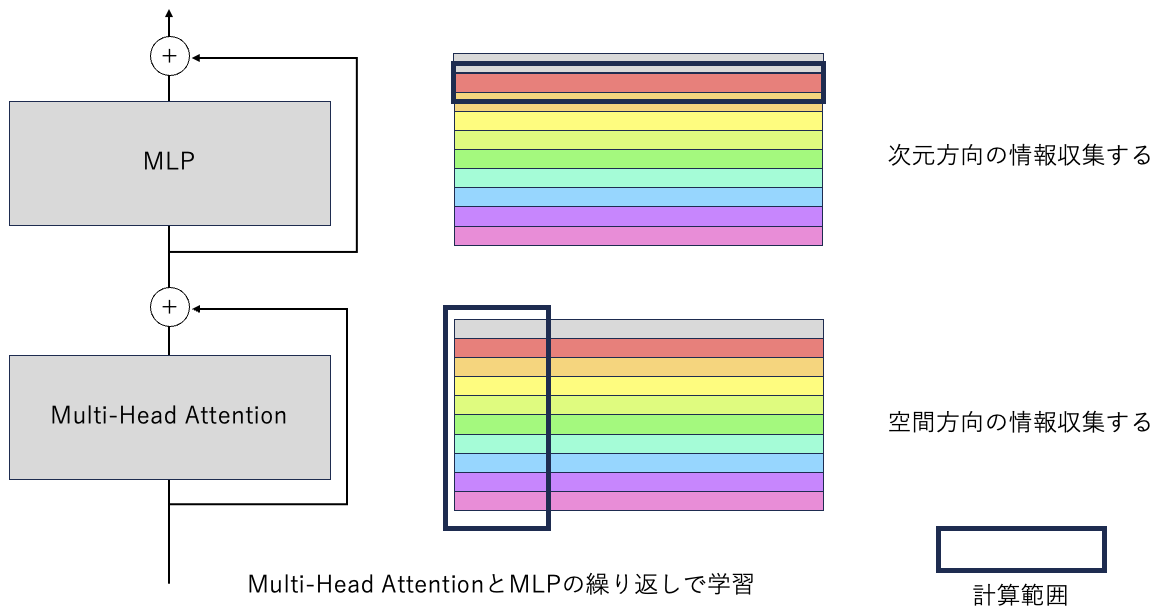
スキップ接続
- 残差接続
- Skip connection
Multi-Head AttentionとMLPの前後に横から接続するルートがある.これは,Multi-Head Attention計算前の特徴量と計算後の特徴量の要素和をしている.
例えば,Multi-Head Attentionがとても悪い認識(羊の色は赤色だ!)を出力した際に,その新しく間違った考え方を持って次の層に移動するより,計算後の(羊の色は赤色だ!)を計算前の(羊の色は白色)情報を足して,緩和する.新しい情報を取り入れながらも,新しい情報に振り回されすぎないような効果を期待する.
- 他にもスキップ接続の効果あります
- スキップ接続によるアンサンブル効果
https://qiita.com/wakayama_90b/items/cbce70016c7df62c65be - ResNet(深い層を実現するにはスキップ接続が必要)
https://qiita.com/wakayama_90b/items/7bc4ebc2b3790fea90b9
- スキップ接続によるアンサンブル効果
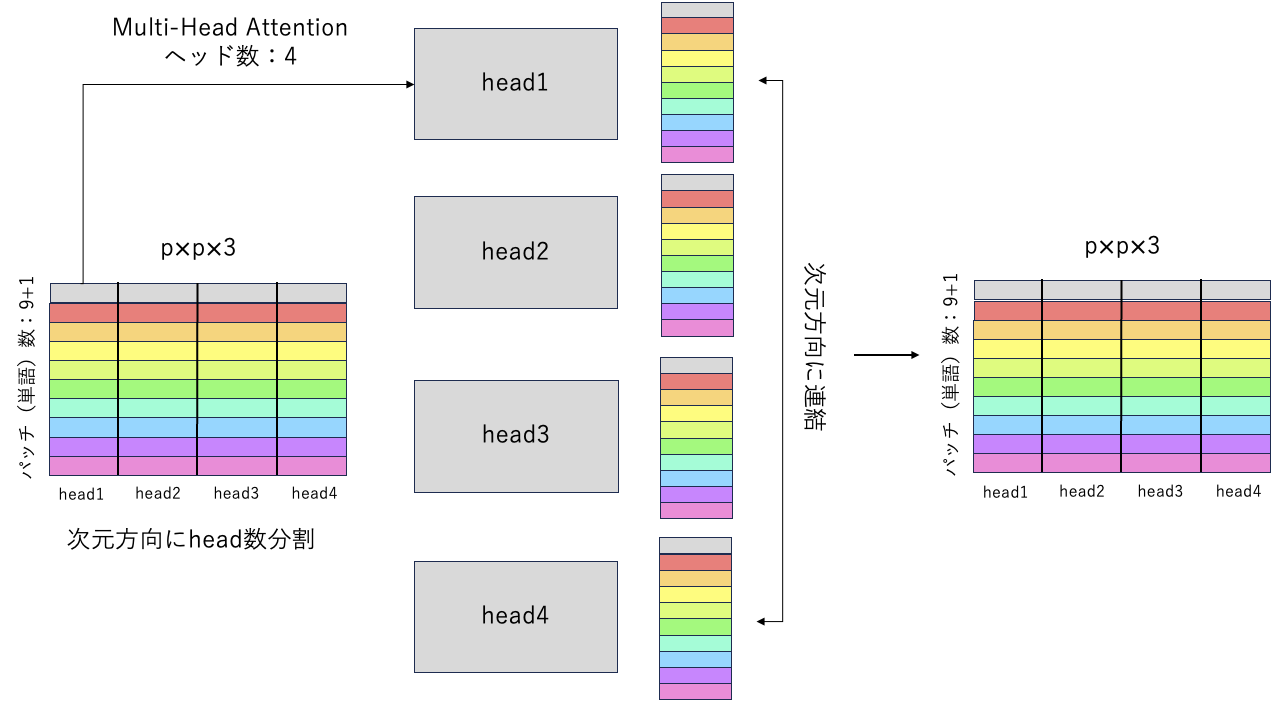
Multi-Head Attention
Multi-Head Attentionは,名前の通り,ヘッドがたくさんあり,各ヘッドでAttentionをする.Attentionとは,Transformerで提案されたSelf-Attention(SA)と呼ばれる計算方法である.SAは次節で説明する.
入力された特徴量を横(次元)方向にヘッド数分割する.各ヘッドには,分割された特徴量が振り分けられ,SAの計算をする.計算後,各ヘッドの出力を連結させて元の特徴量サイズに戻す.
この各ヘッドで別々の計算をすることで,ヘッド1は画像の色を認識,ヘッド2は画像の形状を認識,など画像の様々な特徴を同時に獲得することができる.
Self-Attention(SA)
- Attention機構
- 空間認識
Self-Attention(SA)はヘッド内の計算方法の呼び方である.計算方法を下図に示す.
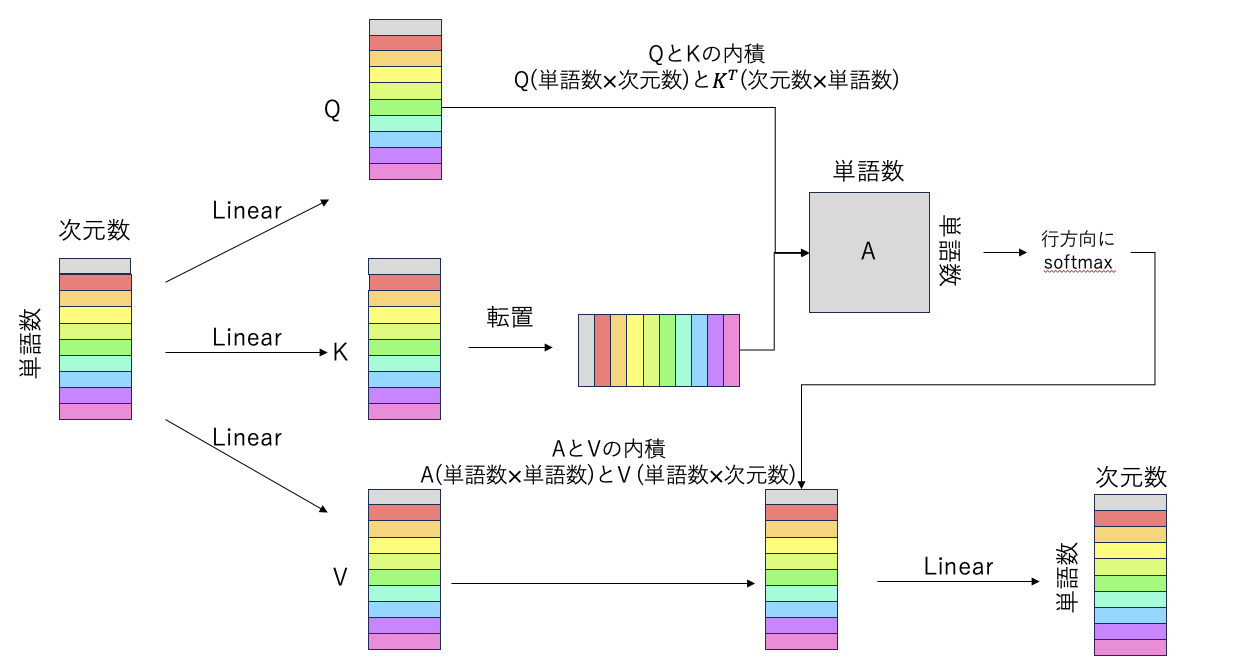
ここで,Q(クエリ),K(キー),V(バリュー)と呼ばれるものが登場するが,よくプログラミングで使用される辞書?みたいなのと考えられますが,特に関係ないものと考えて問題ないです.特徴量のあだ名感覚で覚えたらいいです.
最初に,入力された特徴量から3つLinearをして,それぞれ異なる値を持つ特徴量Q,K,Vを獲得する.次に,Kを転置して,$Q$(単語数 $\times$ 次元数$)と$K^T$(次元数 $\times$ 単語数$)の内積をする.次元数が相殺されて,(単語数 $\times$ 単語数$)を獲得する.
QKの内積後,softmax関数を通して,値を(0~1)に制限する.その際に,1つの値が飛び抜けて高く「9万」とかの値が入っていたらsoftmaxで9万が1,他の値は9万と値が離れすぎてるから全て0.みたいな状況の可能性がある.そこで,$\sqrt{次元数=d}$で割ることで,softmaxの外れ値の影響を緩和する.
softmaxした情報をAと呼び,A(単語数 $\times$ 単語数)とV(単語数 $\times$ 次元数)の内積をする.単語数が相殺されて,(単語数 $\times$ 次元数)を獲得する.
その後,Linearをしてヘッドの出力とする.
Attention(Q,K,V)=\mathrm{softmax} \left( \frac{Q K^\mathrm{T}}{\sqrt{d}} \right) V
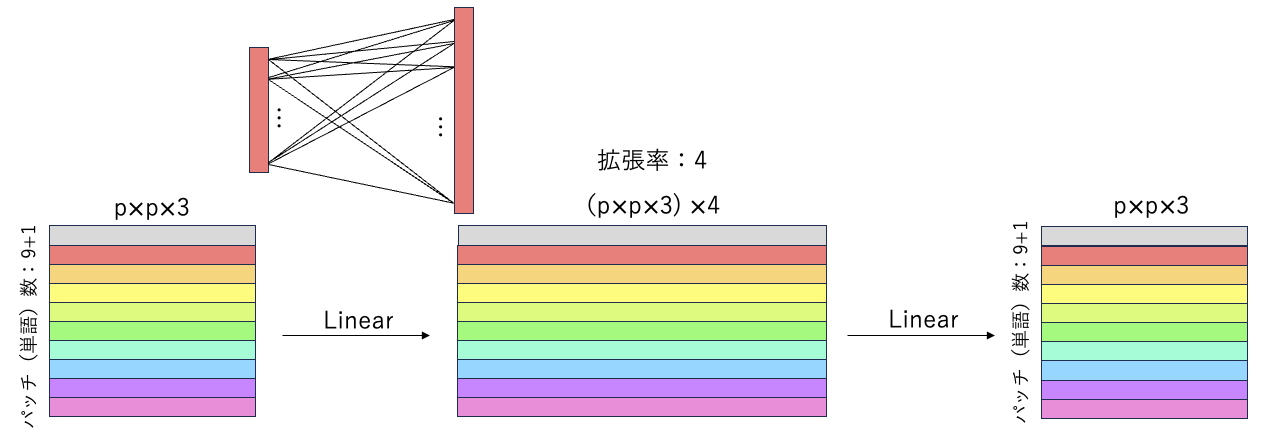
Multilayer perceptron(MLP)
- 多層パーセプトロン
- Feed Forward Network(FFN)
- チャンネル認識
MLPは,特徴量の次元方向の情報を使用して計算する方法で,2層をLinearを使用する.ViTでは,MLPで拡張率が設定され,次元数の情報を拡張させて,圧縮する.拡張率が大きいほど様々な情報が共有できる.
また,1層目のLinear後にGELU関数を通す.表現力向上!
参考資料
https://zenn.dev/nekoallergy/articles/4e224b57a97af9
Norm
- 正則化
- Normalization
機械学習で学習中,学習データに対して過度い対応してしまい,新たな未知データに対する予測がうまくできなくなってしまう「過学習」と言われる問題が発生する.
過学習の原因の1つとして,値が大きいことがある.これを,Normの導入で防ぐ.
Normには種類がたくさんあるが,ViTでは,Layer Normが採用される.Normの入力値の値を平均0,分散1となるように値を変換する.定期的にNormをすることで,値が大きくなりすぎずに学習が可能になる.
参考資料
https://rightcode.co.jp/blog/information-technology/regularization-to-prevent-overtraining
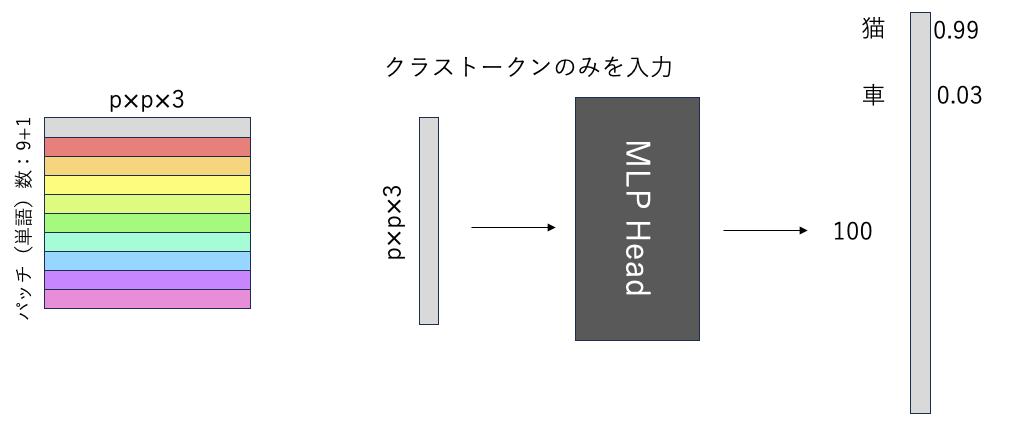
MLP Head
- 識別器
- 全結合層
CNNの場合は全結合層と呼ばれる.最後の処理です.ViTでは識別器と呼ばれます.特徴量からクラストークンのみを取り出し,MLP Headに入力します.MLP headは,LayerNormして1層のLinear層のみです.Linear層で,最後の次元数を識別したいクラス数に設定します.10クラス分類の際は次元数10.1,000クラス分類は1,000.
出力の値は,各クラスの確率が出力されます.今回は猫の画像を入力したので,猫の確率が99%になってます.車の確率は,3%です.
この確率が1番高いクラスをViTの認識結果としています.
ViTのよくある説明
ViTを引用している論文にViTはこんな弱点や利点があるよ.これら弱点を補って,利点を活かした手法を提案します.の流れがあるので,その一例を紹介する.
ViTの派生系の「はじめに」は,このどれかに該当すると思う.
計算量が膨大
ViTは,従来手法のCNNと比較して計算量が膨大である.特に高画質画像の場合に,SAの計算が画像サイズに比例して計算量が2次関数的に増える.これでは,物体検出やセグメンテーションタスクに応用することが困難.
そのため,計算量を抑えたようなViTを提案する.
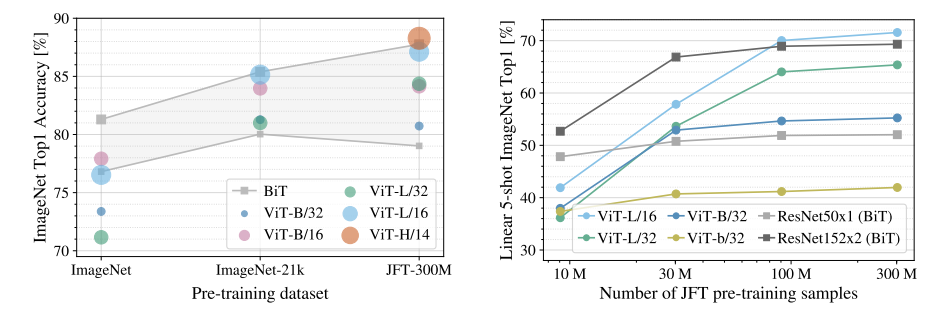
大規模データセット
ViTは,大規模データセットでその性能を発揮する傾向にある.ImageNetの場合,ViTはCNNモデルより性能が低下しており,データセットの大きいJFT-300Mの場合に性能が向上する.しかし,ImageNetでも十分に大規模なデータセットであり,データセットが小さくても機能するViTを提案する.
受容野の広い認識
- 長距離認識が可能
- グローバルな認識
- 大局的な認識
CNNは,カーネルの範囲を計算範囲として,画像の局所的な特徴を捉えるように学習する.反対にViTは,画像全体を並列で一気に計算するため,ViTはCNNと比較して遥かに受容野が広い.
CNNでも受容野が大きかったらViTに勝るのか?ViTの計算範囲を制限したら計算量は削減できるのか?
局所的な認識が苦手
CNNは,局所的な認識をするため,画像のエッジや輪郭を捉える特性がある.しかし,ViTは画像を全体的に掴む計算をするため,セグメンテーションで認識対象の境界線が大雑把になり,局所的な認識はCNNに劣る.そのため,局所認識にも強いViTを提案する.
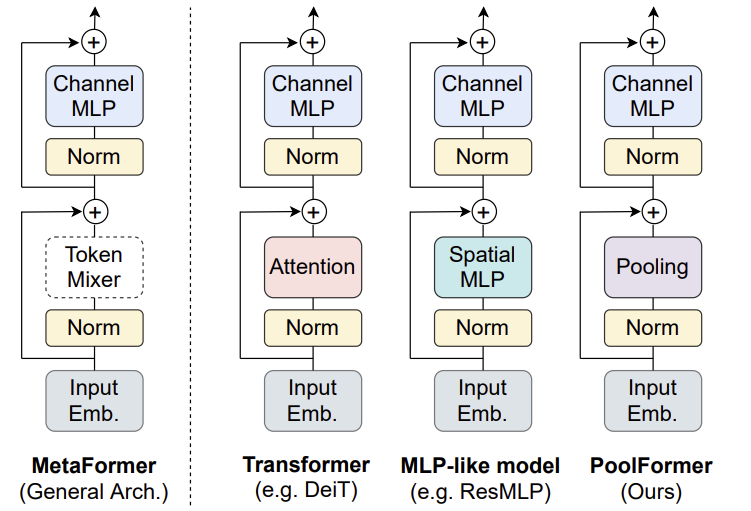
ViTの構造が最強
ViTの成功理由はどこにあるのか?それは,ViTの構造である.空間認識→チャンネル(次元)認識この繰り返しが重要.チャネル認識はMLPがやって,空間認識は,SAでも畳み込み,MLP,極論Poolingでも大きな性能差はなかった.そのためSAが最強ってわけでなく,他に置き換えることができる.
帰納的バイアス
CNNは画像の局所領域を計算範囲としているため,近い位置にある画素は関係が深いという帰納的バイアス(潜在知識)がある.しかし,ViTには,画素の位置による帰納的バイアスが小さい.これにより,より多くのデータセットで帰納的バイアスを自力で学習する必要があり,時間がかかる.しかし,帰納的バイアスがないことは,より自由な認識ができる(近い画素は関係が深い,そうでない場合もある).そこで,ViTにいい感じな帰納的バイアスを加えたら,自由な認識もできるし,帰納的バイアスで早期学習も可能になる.
認識特性
CNNとViTは,画像のどのような特徴をとらえて認識しているかを分析した.結果,CNNは画像のテクスチャ,ViTが形状を捉える傾向にある.人は,形状を捉える傾向にあり,ViTの認識は人の認識に近いことが分かる.
ViTやCNNでより人間の認識に近づけるような構造を提案する.

ViTはノイズに頑健か?
CNNとViTの論争で,画像に雨や雪の自然ノイズを加えた際の認識でViTの方がノイズに頑健.いや,設定を調整したらCNNの方がいいと反論.現状ドロー.他にも,敵対パッチや画素のシャッフルで画像に認識で不利な変換を加えてどのような傾向があるか.また,特定のノイズに対して強いモデルの提案をする.
ViTはハイパラの設定に影響
ViTは,学習の人手で決定するパラメータ(ハイパラ)である学習率,エポック数,最適化手法の設定に影響されやすく,不安定な傾向がある.そこで,ハイパラが多少変化しても性能低下しないViTを提案する.
アンサンブル効果
ViTのマルチヘッドは,アンサンブル効果がある.アンサンブルは,複数の解答を組み合わして最適な答えを導くことで,1つのヘッドが全然ダメな認識をしても他のヘッドがしっかり機能していたら全く問題がない.学習中にヘッドを切り離してもあまり問題なかった.なので,マルチヘッドの構造が大切.
動的なパラメータ
動的なパラメータ(重み)は,入力画像によって値の変化する重みのことである.CNNは静的なパラメータしか持っておらず,どんな画像が入力されてもカーネルの持つ値(重み)は変化しない.
ViTは,SAに動的なパラメータを持つ.AとVの内積で,AはQKの内積→softmaxで,Aには画像の値を使用している.画像の値を使用していることは,入力される画像が異なれば,Aの値も異なる.この入力の値を使用して特徴量変換の計算することを入力画像の変化に対して動的に変化する重み,動的なパラメータと呼ぶ.
これの利点は,画像によって,局所的な認識が重要だったり,大局的な認識が重要だったりと画像によって,重要になる部分が異なる.各画像に合わせた認識が可能になる.
CNNに動的なパラメータを導入したらViTに匹敵するのか?
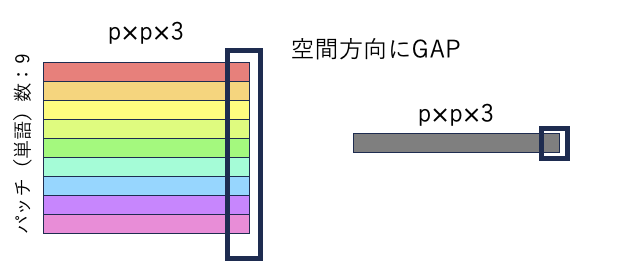
クラストークンの代わりにGAPを使用
ViTのクラストークンの有無に関しても議論されて,各次元のGAP(global average pooling)=平均値で求める.
縦方向の値の平均値を1つ出力して,灰色の特徴量に変換.これをクラストークがない代わりに識別器へ入力する.
クラストークンがない恩恵で,単純に単語数が減ったので,計算量が削減できる.
位置埋め込みの有無
位置埋め込みがなくても機能するよ.ViTにCNNを導入したらCNNが位置を保存して,位置埋め込みの必要がなくなた.
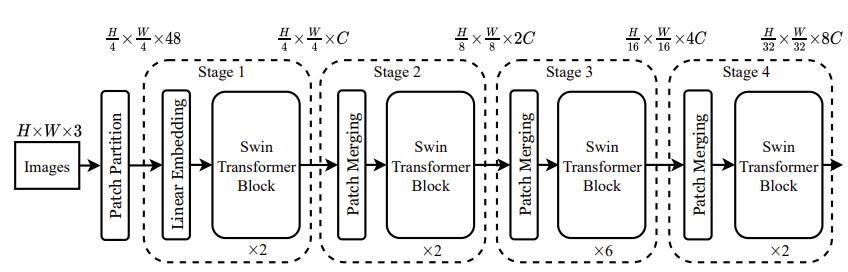
階層型のViT
ResNet,Swinのように,4ステージステージ構造で,ステージ間で空間サイズを半分にして,チャンネル数を2倍にする.階層型では,[2,2,6,2]のように,3ステージ目の繰り返し回数を大きく設定する.
また,1と2ステージではSAを使用せずに,後半の3,4ステージでSAを使用する.これは,後半ステージで空間サイズが小さくなるため,計算量を削減できる.また,ViTは浅い層で局所的な認識を好むため,後半にSAを導入することが効果的である.
ViTの学習方法
ViTの性能を発揮させるには大規模なデータセットが必要だが,データセットを作るには,画像と画像に何が写っているかの答え(ラベル)が必要である.このラベル付けは,人手で行うので非常に大変である.そこで,ラベルなしで学習できる学習方法があれば,画像を集めるだけでViTの本来の性能が発揮できる学習方法(自己教師あり学習手法)を提案する.
まとめ
今回は,Vison Transformerについて解説した.画像認識系の論文を読む際にViTのことを知っていたら読みやすいと思います.
プロフィールからViTの派生モデルの説明があるので,そちらもぜひお願いします.
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39