はじめに
元ネタ
Unlimited Blade Worksについて説明しようかと思いましたが特定作品のネタバレになりかねないので あえてここでは説明しません。気になる方は各自で調べてみてください。GANで剣の画像無限に生成してUnlimited Blade Worksするやつ思い付いたので誰か
— ばんくし (@vaaaaanquish) 2018年5月16日
剣の画像を集めてGANで新しい剣の画像を生成してみるというのが今回の主旨になります。
全体的な作業の流れ
- 剣の画像を収集する
- 学習に利用する画像を選定する
- DCGANモデルを構築、学習させる
- 学習したモデルを利用して新しい剣の画像を生成する
Aidemyで学習した内容
「CNNを用いた画像認識」コースで学んだ内容をGANのモデル作成に活かしました。
特に畳み込み層のパラメータであるfilter、strides、paddingの設定する値の選定部分で
学習した内容が活かせたと思います。
データの収集
収集方法について
こちらの記事で紹介されています、Github - icrawlerを利用しました。
Qiita - 機械学習用の画像を集めるのにicrawlerが便利だった
こんな感じのスクリプトを作りGANに使う画像を用意しました。
検索キーワードには**「sword」, 「shortsword」, 「samuraisword」,「longsword」**などを設定しました。
import argparse
from icrawler.builtin import GoogleImageCrawler
def get_arguments():
parser = argparse.ArgumentParser()
parser.add_argument("-s", "--save_dir",
default="save_dir", type=str)
parser.add_argument("-a", "--arg",
type=str, required=True)
return parser.parse_args()
args = get_arguments()
crawler = GoogleImageCrawler(storage={"root_dir": args.save_dir})
crawler.crawl(keyword=args.arg, max_num=1000)
収集した画像
全部で1000枚ほど収集することができました。
ただ背景や向きが揃っていない、そもそも剣と関係ないような画像も
使用した画像
選んだポイント
最終的に集めた画像から以下の画像を手作業で選びました。
- 向きが左斜め下を向いている
- 剣のみが画像に写っている
- 剣の体裁(刃がある、柄がある)をなしている
選んだ理由はGANの成功例で使われているデータセット(CelebAなど)の条件は統一されているため、剣の画像の選ぶ条件もほぼ同じ条件になるようにしました。
訓練に使用した画像
選んだ画像たちはこちらになります。全部で144枚になりました。

GANについて
GANの構造や解説、説明については下記記事にゆずります。
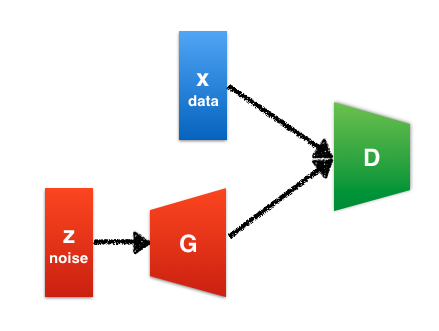
GANの構造はこんな感じ。
Elix Tech Blog - はじめてのGANより引用
次の項で上記画像のGの部分、Generator、Dの部分、Discriminatorをコーディングしていきます。
DCGANモデルの構築
学習時、モデル構築時のコードは以下リポジトリ及びQiita記事を参考にしました。
Generatorの構築
from keras.layers import Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
def build_generator(self):
model = Sequential()
model.add(Dense(128 * 32 * 32, activation="relu",
input_shape=(self.latent_dim,)))
model.add(Reshape((32, 32, 128)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(3, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
Discriminatorの構築
from keras.layers import Input, Dense, Flatten, Dropout
from keras.layers import BatchNormalization, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D
from keras.models import Sequential, Model
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2,
input_shape=self.img_shape,
padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
訓練画像の読み込み
訓練画像は全て128*128にリサイズしました。
Kerasには画像ファイルをnp.ndarrayへ変換してくれるutil関数があるのでそちらを使いました。
from pathlib import Path
from keras.preprocessing.image import load_img, img_to_array
import numpy as np
def load_data_set(self):
return np.array([img_to_array(load_img(img_path,
target_size=(self.img_rows,
self.img_cols)))
for img_path in Path(self.img_path).glob("*")])
訓練及び初期設定
モデル及びデータセットの読み込みを組み合わせて、下記コードを使って学習を始めたいと思います。
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
class DCGAN():
def __init__(self):
# Input shape
self.img_path = "images"
self.img_rows = 128
self.img_cols = 128
self.channels = 3
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise as input and generates imgs
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def train(self, epochs, batch_size=128, save_interval=50):
# Load the dataset
X_train = self.load_data_set()
# Rescale -1 to 1
X_train = X_train / 127.5 - 1.
# X_train = np.expand_dims(X_train, axis=3)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random half of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# Sample noise and generate a batch of new images
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# Train the discriminator (real classified as ones and generated as zeros)
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
# Train the generator (wants discriminator to mistake images as real)
g_loss = self.combined.train_on_batch(noise, valid)
# Plot the progress
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (
epoch, d_loss[0], 100 * d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, :])
axs[i, j].axis('off')
cnt += 1
fig.savefig("images/gan_swrod_%d.png" % epoch)
plt.close()
dcgan = DCGAN()
dcgan.train(epochs=200000, batch_size=32, save_interval=500)
訓練時のロスの情報をこちらの掲載したかったのですが、保存し忘れてしまいました申し訳ないです。
結果
生成された画像
だいたい12時間ほど回して、生成された画像がこちらになります。
epoch: 0 epoch: 1000
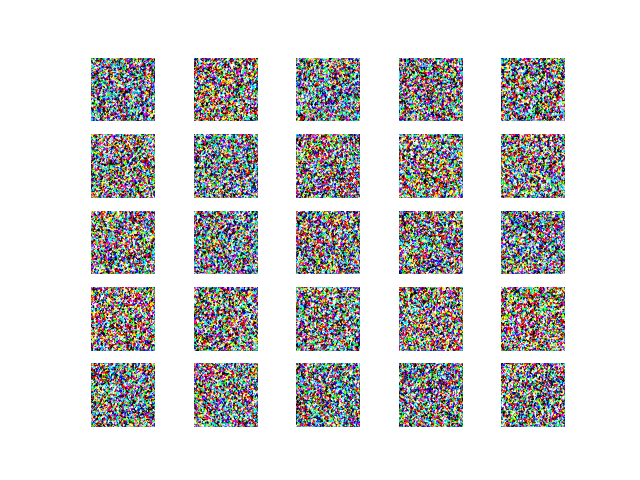

epoch: 10000 epoch: 25000


epoch: 40000 epoch: 60000


剣の特徴である刀身、柄の部分を捉えている剣の画像が生成出来ているように見えます。
当初の目標であった剣の画像生成に成功しているのではないでしょうか。
(黒い背景になってしまっているのはリサイズした際に発生したようで原因はよくわかっておりません。)
GIFにしてみました

おわりに
画像の収集方法に難ありでした、色々な種類剣の画像を生成しようと考えた場合自分で集めるのではなく
剣の画像を販売している業者等から購入したほうが
よりたくさんの画像が集められ様々な剣の画像が生成できるのかなと思いました。
最後まで読んでいただき、ありがとうございました。
記事に誤字・ミス等あればコメントで教えていただけると嬉しいです。
参考
- Elix Tech Blog - はじめてのGAN
- Qiita- GANについて概念から実装まで ~DCGANによるキルミーベイベー生成~
- Qiita - 今さら聞けないGAN(1) 基本構造の理解
- CS231n - Convolutional Neural Networks (CNNs / ConvNets)
- Keras - UpSampling2D
- Qiita - 機械学習用の画像を集めるのにicrawlerが便利だった
- Keras tips: 様々な画像の前処理をカンタンにやってくれるkeras.preprocessingのまとめ
- Github - jacobgil/keras-dcgan