@xkumiyu です。
NTTコミュニケーションズ Advent Calendar 2017の21日目の記事です。
はじめに
データ生成系のDeepLearning手法の1つであるGAN(Generative Adversarial Network)をCelebAという顔画像のデータセットで使ってみました。ランダムな画像生成と属性ベクトルを用いた画像生成を行ったので、その内容をまとめてみたいと思います。が、結果は微妙です^^;
使ったコードは、Githubにあげています。
GAN
GANの概要
GANは、Generative Adversarial Networks(敵性的生成ネットワーク)の略で、データを学習し似たような新しいデータを生成する手法です。

右端の列が生成されたデータで、隣の列が最も近い学習データです。
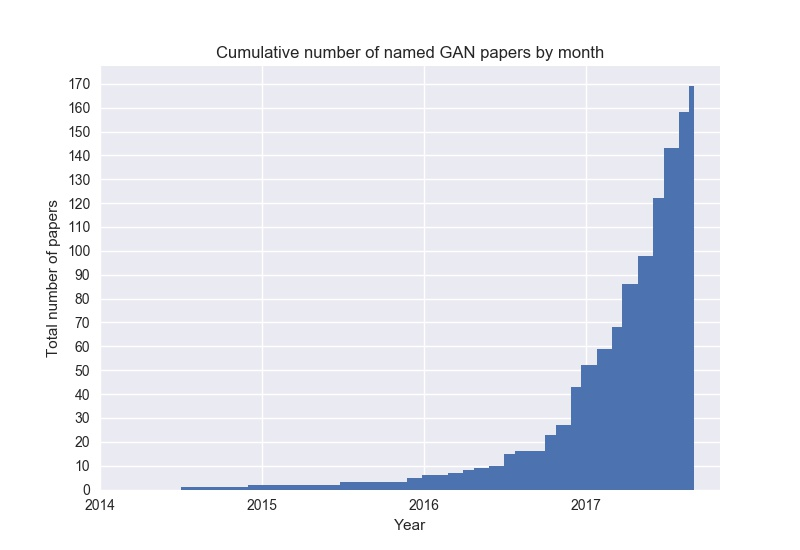
2014年にIan Goodfellow氏らによって発表され、現在では140を超える関連論文が次々に発表されています。GAN Zooというページには様々なGANの論文が記載されています。
最近では、線画から着色を行うPaintsChainerやGTC Japan 2017では、GANで作曲された音楽が披露されました。演奏された音楽はSoundCloudで聴くことができます。
このような見た目にインパクトがある応用例以外にも、Data Augmentation1にGANを用いることもでき、様々なところで注目を浴びています。
また、Facebook AI ResearchのYann LeCun氏は、
機械学習において、この10年で最も面白いアイディア
と評しています。
GANのネットワーク
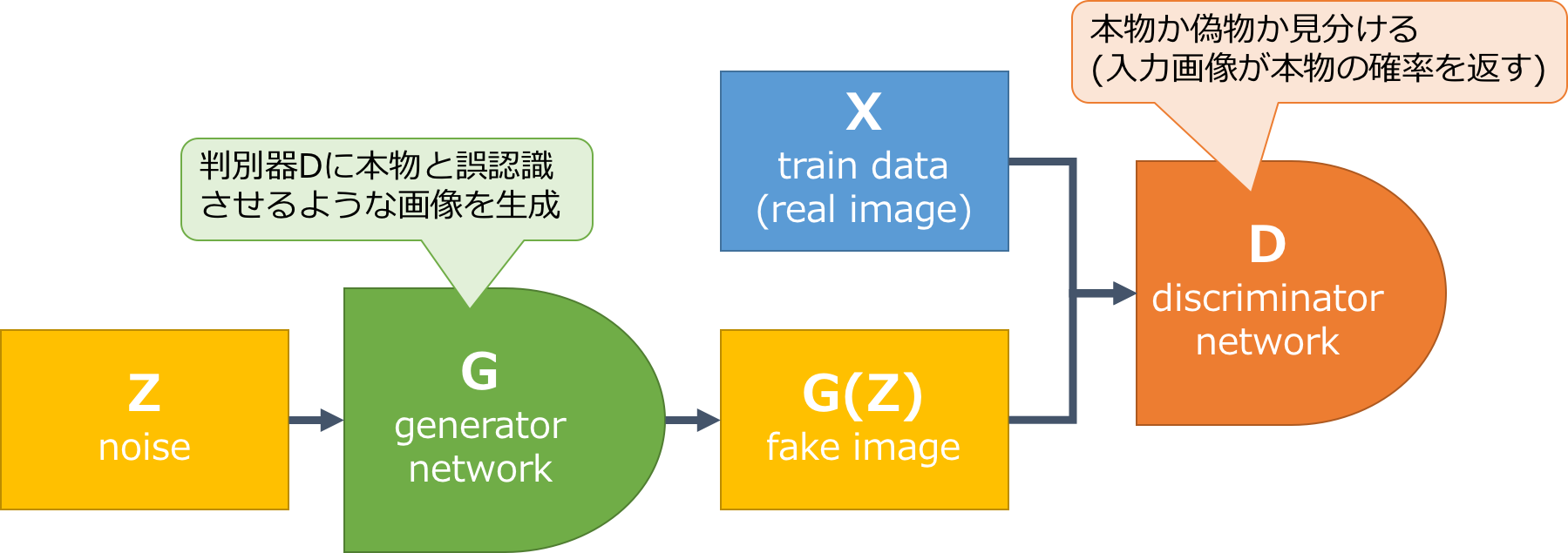
GANには、**Generator(生成器)とDiscriminator(判別器)**の2つネットワークがあります。Generatorは、Discriminatorに本物と誤認識させるような画像を生成し、Discriminatorは、本物か偽物かを見分ける役割があります。2つのネットワークが敵対させて学習さます。よく偽札の作成とそれを見分ける警察の関係に例えられます。
学習の目的関数を数式で書くと、以下のような式になります。
\min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)} \bigl[ \log D(x) \bigr] + \mathbb{E}_{z \sim p_{z}(z)} \bigl[ \log (1 - D(G(x))) \bigr]
右辺の第1項は、Discriminatorが本物データを本物と判別する期待値で、第2項は偽物データを偽物と判別する期待値です。なので、Discriminatorのネットワークは正しく判別したいので、上記の式を最大化しようとしますが、逆にGeneratorのネットワークは誤認識させたいので、上記の式を最小化しようとします。
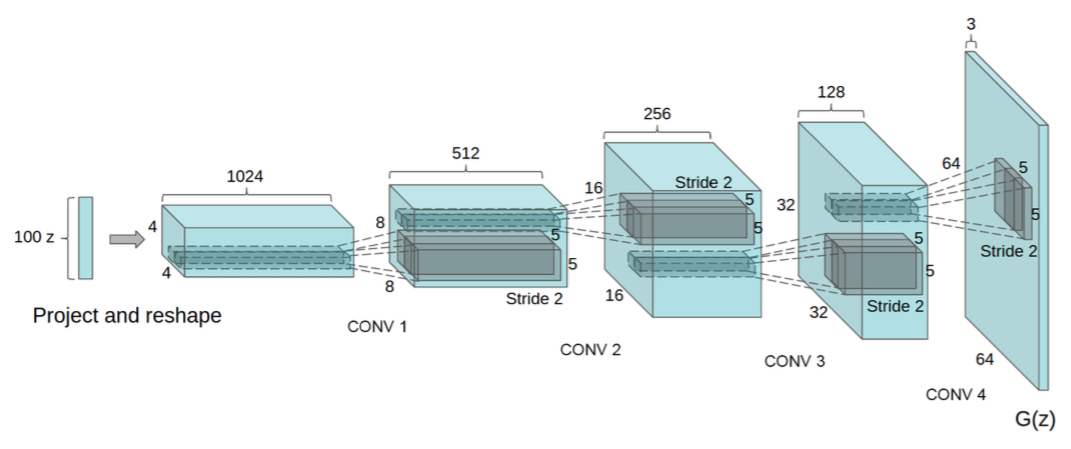
DiscriminatorとGeneratorのネットワークにConvolutional Networkを用いたのが、DCGANで、Generatorのネットワークは以下のような構造になります。
GANについてもっと詳しく知りたい方へ
以下の論文や記事を参照ください。
原著論文
- Generative Adversarial Networks (GAN)
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (DCGAN)
解説記事 / 参考記事
- はじめてのGAN
- Generative Adversarial Network とは――トップ研究者が解説
- GAN(Generative Adversarial Networks)を学習させる際の14のテクニック
- Unrolled Generative Adversarial Networks [arXiv:1611.02163] – ご注文は機械学習ですか?
- Chainerで顔イラストの自動生成
サンプルコード
CelebA
CelebAは、CUHK2が公開している大規模な顔画像集合です。非商用の研究目的で使えます。1枚の画像に複数の属性(メガネをかけている、笑っているなど)ラベルが付与されているのが特徴です。
- 10,177人
- 202,599枚
- 40属性
- 178x218画素

CelebAの画像を使ってGANの学習
それでは、CelebAの画像を使って学習させてみます。今回は、ChainerのExampleにあるDCGANをベースに作成しました。
ランダムノイズから顔画像の生成
画像が正方形ではないので、真ん中を中心にCropし、64x64にリサイズしました。また、ChainerのExampleは32x32を対象としているので、ネットワークを少し変更しました。
先程、数式で表した損失関数の部分は以下のようにシンプルに書くことができます。
import chainer.functions as F
def loss_dis(self, dis, y_fake, y_real):
batchsize = len(y_fake)
L1 = F.sum(F.softplus(-y_real)) / batchsize
L2 = F.sum(F.softplus(y_fake)) / batchsize
loss = L1 + L2
return loss
def loss_gen(self, gen, y_fake):
batchsize = len(y_fake)
loss = F.sum(F.softplus(-y_fake)) / batchsize
return loss
以下のデータとパラメータで、1GPUを使って1日くらい回してみました。
- dataset
- train data(real image): 202,599 images (64x64)
- random noise: 100 dim
- batchsize: 64
- epoch: 200
- optimizer: Adam(alpha=0.0002, beta1=0.5)
ちなみに、今回用いたGPUだと1epochにかかる計算時間は8分くらいでしたが、CPUだと14時間くらいかかる計算になりました。100倍くらい早いです。もっと早くしたい場合はたくさんGPUを買う必要があるかもしれませんね。3
Mode Collapseと対処法
はじめ、このまま学習させたところ、Mode Collapseと呼ばれる現象を陥り、GANの学習が失敗しました。Mode Collapseは、Generatorが一部のデータ分布のみを学習し、そこから抜け出すことができなくなる現象で、Generatorにどのような入力を与えても、ほとんど同じ出力が返ってきます。
対処法としては、Unrolled GANという手法が提案されています。日本語の解説はこちらの記事が詳しいです。記事からの引用ですが、学習を以下のように変更します。
パラメータの学習ですが、まずK回Discriminatorを更新します。
この時1回目の更新で得られた重みをコピーして保存しておきます。
その後Generatorを更新してから保存したDiscriminatorの重みで現在のDiscriminatorの重みを上書きします。
通常のGANのUpdaterは、
dis_optimizer.update(self.loss_dis, dis, y_fake, y_real)
gen_optimizer.update(self.loss_gen, gen, y_fake)
と、DiscriminatorとGeneratorを1回ずつ更新している箇所を、
dis_optimizer.update(self.loss_dis, dis, y_fake, y_real)
if self.k == 0:
dis.cache_discriminator_weights()
if self.k == dis.unrolling_steps:
gen_optimizer.update(self.loss_gen, gen, y_fake)
dis.restore_discriminator_weights()
self.k = -1
self.k += 1
に変更しました。cache_discriminator_weightsとrestore_discriminator_weightsは、参考記事の記載と同じ関数を使いました。
K=5で学習させたところ、入力を変えると出力も変わりましたが、学習が足りないのか精度が落ちた気がします。。
生成結果
それでは、生成結果です。
10分後

1時間後

6時間後

24時間後

属性を追加/削除した顔画像の生成
先程は、100次元のランダムノイズ$z$から画像を生成しましたが、これは100次元の特徴空間から画像空間へのマッピングといえます。なので、2つの$z$の中間にある$z$からは、それぞれの画像の中間的な画像が生成されるはずです。また、例えばメガネを書けてるというベクトルがわかれば、ある$z$にそのベクトルを足せば、画像にメガネをかけさせることができます。
CelebAには40種類の属性ラベルがあるので、この属性を表すベクトルを抽出してみたいと思います。抽出は以下のステップで行うことができます。
- 学習済みのGeneratorを使って、画像を100次元の$z$に変換するEncoderを作成(学習)
- Encoderをつかって属性ありの画像の$z_{with}$と属性なしの画像の$z_{without}$を求め、属性ベクトル$z_{with} - z_{without}$を計算
Encoderの学習
まず、Encoderをつくります。Encoderは、画像を$z$に変換するもので、以下のような構成となります。Encoderを通して得た$z=E(x)$を使ってGeneratorで生成された画像$G(z)$と、元々の画像$x$が同じになるようにEncoderを学習します。
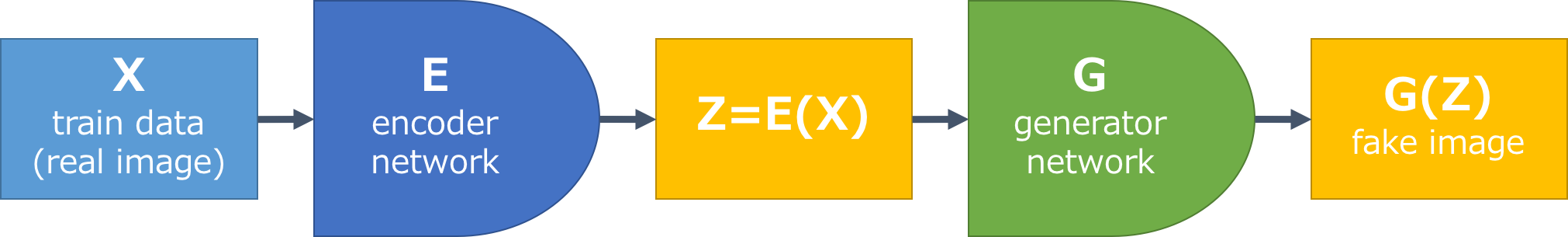
Encoderのネットワークは、Discriminatorのネットワークとほとんど同じで、出力は1次元ではなく100次元とします。Generatorはランダム生成のときに学習したものと同じです。重みも同じものを使い、ここでは学習しません。
Encoderの重みの更新を担当するUpdaterは以下のように書きました。
class EncUpdater(chainer.training.StandardUpdater):
def __init__(self, *args, **kwargs):
self.gen, self.enc = kwargs.pop('models')
super(EncUpdater, self).__init__(*args, **kwargs)
def loss_enc(self, enc, x_real, x_fake):
loss = F.mean_squared_error(x_real, x_fake)
chainer.report({'loss': loss}, enc)
return loss
def update_core(self):
enc_optimizer = self.get_optimizer('enc')
batch = self.get_iterator('main').next()
x_real = Variable(self.converter(batch, self.device)) / 255.
x_real = F.resize_images(x_real, (64, 64))
gen, enc = self.gen, self.enc
z = enc(x_real)
x_fake = gen(z)
enc_optimizer.update(self.loss_enc, enc, x_real, x_fake)
Encoderの学習は、ネットワークが1つなので学習にかかる時間もおおよそ半分くらいになります。
属性ベクトルの抽出
Encoderができると、属性ベクトルを求めるのは簡単で、以下の図のようなフローで計算が可能です。
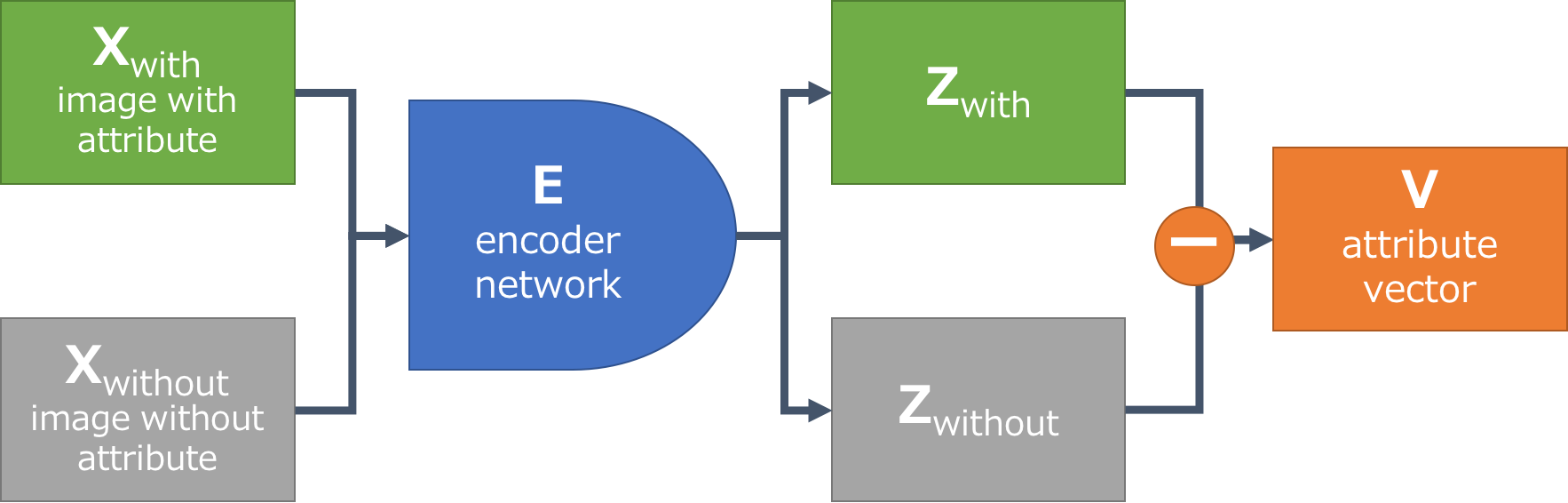
例えば、メガネの属性ベクトルを計算するためには、属性ラベルをつかって、すべての画像をメガネがある画像$x_{with}$とない画像$x_{without}$の2つに分けます。次に、Encoderをつかって画像を$z$ベクトルへ変換し、メガネがある画像の$z$ベクトル$z_{with}$とない画像の$z$ベクトル$z_{without}$を求めることができます。それぞれの平均ベクトルの差を計算すると、メガネの属性ベクトル$v = \overline{z_{with}} - \overline{z_{without}}$が抽出できます。
属性ベクトルを使って顔を加工する
元画像

加工前
元画像$x$にEncoderで得た$z$に対して、Generatorで生成した画像です。

若くする
Youngラベルのある画像から抽出したYoungベクトルを元画像の$z$に加えてみます。

うーん。。微妙ですね。Generatorの学習が上手くいっていないのか、それともEncoderが悪いのか。。Generatorの方だと思いますが、調査はしきれていません。
さいごに
CelebAデータセットを使ってGANの学習をChainerを用いて実施しました。ランダムな画像生成と、画像の属性ベクトルの抽出、属性ベクトルを使った画像の加工を行いました。
が、上手くいったとは言い難い結果となってしまいました。
いろいろ試しながら学習を行いましたが、1回の学習で数時間程度かかり、Generatorの学習が終わってからEncoderの学習となるので、さらに時間がかかります。もう少したくさんのGPUがあれば試行回数が増やせて、いい結果が得られたかもしれません。
研究レベルでは、これくらい小さい画像であれば上手くいっているので、写真加工アプリなどに実装される日は近いのかもしれません。