
PFNのmattyaです。chainerを使ったイラスト自動生成をやってみました(上の画像もその一例です)。
20日目の@rezoolabさんの記事(Chainerを使ってコンピュータにイラストを描かせる)とネタが被っちゃったので、本記事ではさらに発展的なところを書いていきたいと思います。一緒に読んでいただくとよいかと。
概要
- Chainerで画像を生成するニューラルネットであるDCGANを実装した→github
- safebooruから顔イラストを集めてきて学習させた
- 学習済みモデルをconvnetjsで読み込ませて、ブラウザ上で動くデモを作成した→こちら(ローディングに20秒程度かかります)
アルゴリズム
今回実装したDCGAN(元論文)はGenerative Adversarial Networkというアルゴリズムの発展形です。GANの目標は、学習データセットと見分けがつかないようなデータを生成するGenerator (G)を獲得することです。Gには一様分布などからサンプルされた乱数zが入力され、これを種としてxを生成します。zが異なれば違う出力が出てきますが、その分布が学習データの分布と見分けがつかないようになります。
Gの学習は、Discriminator (D)を使います。Dは入力が学習データセット由来か、Gの生成した自動生成データかを判別する分類器です。なぜこんなものが役に立つのかというと、Dの出力を0に近づけるような方向が、まさにGによる自動生成データを学習元データと見分けがつかないようにする方向になるからです。
GはDが何を判別基準にしてるのかを手がかりにその基準をクリアするように学習し、DはGの出力を見ながら学習データセットと区別するために有効な特徴を探してそれを判別基準に加えていく、というふうに、GとDがイタチごっこをしながら学習が進んでいきます。

1次元ガウス分布を学習させた時のイタチごっこの様子。青が目標、緑がG、赤がD。
Generative adversarial networks playing pic.twitter.com/fM9VP5U6N9
— Alec Radford (@AlecRad) 2015, 7月 10
DCGANはGとDにConvolution neural networkを用いたものです。D側は標準的なCNN、G側はzから画像を作る通常とは逆向きの(しばしばdeconvolutionと呼ばれる)CNNになります。このような構成自体はとても自然な拡張なのですが、GANはそもそも学習が不安定であり、この論文では綺麗に学習が行える条件を見つけたことが重要な貢献となっています。
データ
safebooruから収集した画像に対してlbpcascade-animefaceで顔検出を行い、約30万枚の顔イラストデータセットを構築しました。画像サイズは96x96に統一しました。safebooruは非常に詳しくタグ付けがなされているので、タグデータも後の実験のために一緒に集めました(DCGANの学習自体にはラベルデータは必要ありません)。
実装
githubでコードを公開しています。
論文の著者が公開していたtheanoのコードを参考に、Chainerに移植しました。
以下の点が本家の論文と異なります。
- 画像サイズが96x96 (本家は64x64)
- convolutionのフィルタ数が半分
- Gの出力にtanhを通していない
- Dのactivation functionがleaky_reluではなくelu
結果
学習にはTesla K40cを使用。
30分後

2時間後

1日後

すごい!
webデモ
Chainerで学習したGeneratorのパラメタをファイルに書き出してconvnetjsで読むことで、ブラウザ上で顔生成が実験できるデモを作成しました(convnetjs改造協力: okuta氏)→こちら。
モデルのロードに数十秒かかるので、辛抱強くお待ち下さい(画像の生成自体は一枚1秒程度で出来ます)。
下にスライダーがたくさんあって、ここを調整することで、画像の各特徴を強化したり弱めたり出来ます。ここは、下記で説明する"長髪化ベクトル"と同様の仕組みで、各特徴に対応するベクトルを求めて、それをzに足し引きしています。

おすすめの使い方
- スライダーを好みの値に動かして、shuffle!を連打する
- 変な画像が多かったらタグが強すぎるか、noise_strengthが強すぎるので弱める
- 好みの画像が生成されたら、スライダーを微調整してdraw!を押す
しくみ
z0 + Σ s_i * tz_i を種に画像を生成します。
z0は[-noise_strength, noise_strength]の一様分布からサンプルします。
s_iは各スライダーの値、tz_iは各タグに対応する特徴ベクトルです。
shuffle!を押すと、z0が再サンプルされます。
zの空間を調べる
DCGANではzをn次元一様分布からサンプルするので、学習が成功すれば、一様分布の値域内のzならば全て、学習データと見分けがつかないような"まともな"画像を生成することが出来ます(denoising auto-encoderなどでは、デタラメに選んだzではまともな画像になることは保証されないし、実際ろくな画像が出てこないので、この点がGANやVAEの強みです)。
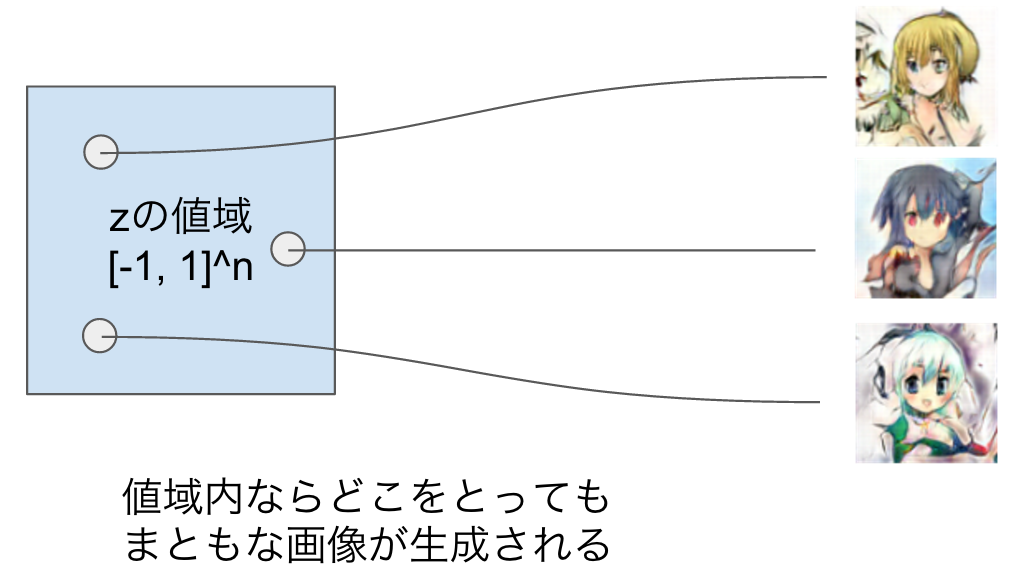
すると、ある2つのzをとってきたときそれらを結ぶ直線上にあるようなzも、まともな画像を生成する種となります。実際にやってみると、2つの画像の中間的な特徴を持った画像を描いてくれます。これができるということは、「DCGANは学習データに含まれる画像を丸暗記してそのまま描いているだけなのでは?」という疑問を間接的に否定することになります。もしそうなら、直線上の画像は連続的に変換されるのではなく、記憶1から記憶2に非連続的に切り替わるようになるはずだからです。
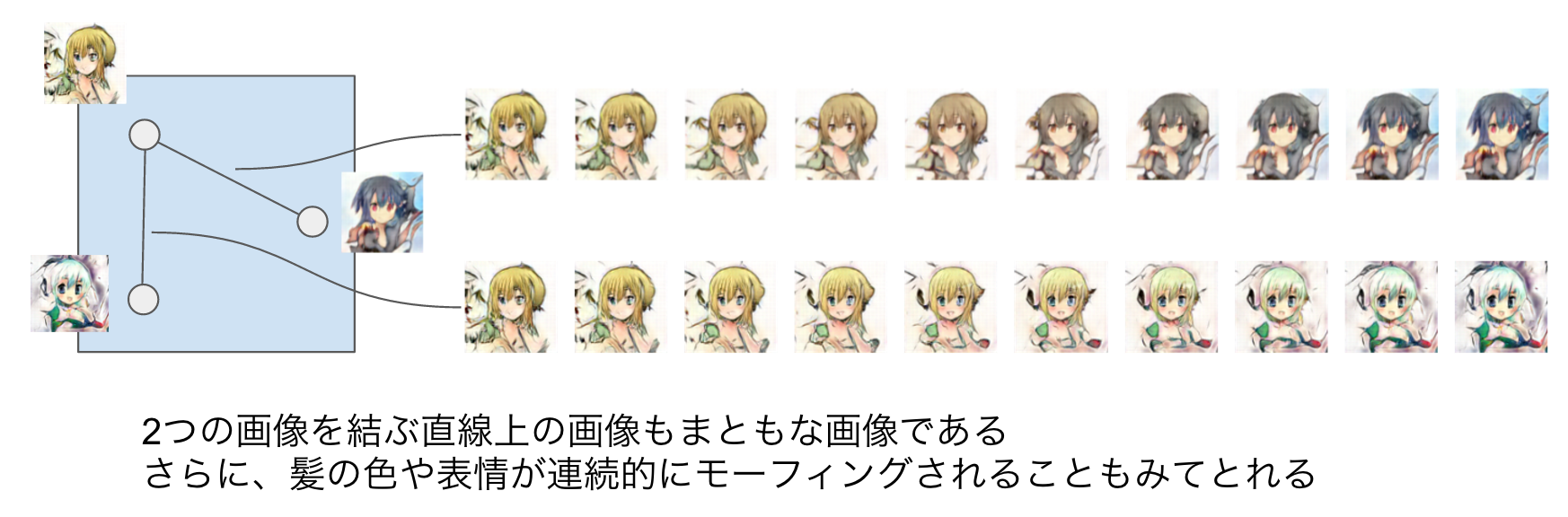
また、zを動かすと画像が連続的に変わっていくということは、「似たような特徴を持つ画像は、zも近い」という可能性を示唆しています。もしそうだとすると、「長髪っぽくなるzの方向」や「笑顔っぽくなるzの方向」などがあると考えられます(word2vecで男性を女性にするベクトルや、国を首都にとばすベクトルがあったように)。
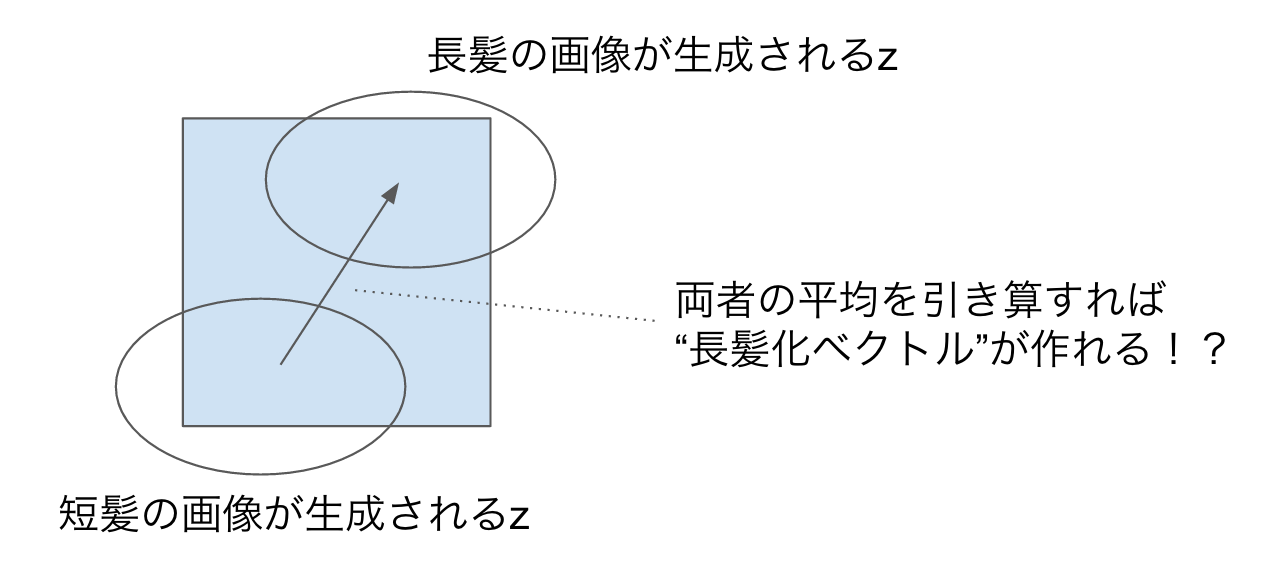
実際、長髪の画像が生成されるようなzたちの平均から、短髪の画像が生成されるようなzたちの平均を引いて"長髪化ベクトル"を作ってやると、それを足すことで任意のキャラクターの髪を長くできることが分かりました。

この性質を使うと、狙った画像を作ることも可能です。ぜひ上述のwebデモでお試しください。

おわりに
3ヶ月前くらいにchainer-goghを作ってたとき、「綺麗な画像の自動生成はあと1年はできないだろうな〜」などと思っていたので、本論文を見た時衝撃を受け、実際顔イラストが綺麗に出てきた時はリアルに叫びました。ここにあるような漢字や花の生成成功例が出ていたので、得体のしれない人にアニメイラスト生成を出される前に発表してしまおうとtwitterに呟いた結果rezoolabさんとバッティングしてしまいました…フレンドリーファイアしてしまった感……
今回顔を切り出したイラストを使ったのは、実は最初イラスト全体で試して、あまりうまくいかなかったからです(ほんとうは百合画像を生成したかったんだ。。。)。rezoolabさんの考察と同じように、本家のAlbum coversやImagenetの結果が「なんかそれっぽいけどよく分からない」感じを受けるように、ドメインが広範囲に渡ると、DCGANをもってしてもまだイマイチな結果になるようです。
広いドメイン対応の問題以外にも、次のような点に今後の改良の余地があるのではないでしょうか。
・ GANのパラメタチューニングが闇
DCGANはネットワーク構造やパラメタの最適化によって綺麗な画像生成を実現していますが、Adamのbeta1や重みの初期値やzの次元数などなど腑に落ちない点が数多く有ります。しかもネットワークを大きくしたりしようとすると、最適なパラメタから外れるせいか、ことごとくうまくいきませんでした。そもそもGANはVAEとくらべても理論的なところがよく分かっていなくて、それを解決して、パラメタの選び方に指針を与える必要があるでしょう。
・ 大きい画像を生成
chainer-goghの元となったstylenetは画像のサイズにはさほど依存しない手法だったのですが、現在のDCGANはサムネイルサイズの小さな画像しか作れません。1000x1000くらいの大きな画像を作りたいですね。
・ ラベルデータの活用
今回使ったsafebooruのデータはタグなどのメタデータが比較的詳しく振られていて、これらを活用する方法が生み出せれば、学習の助けになるはずです。