はじめに
メリークリスマス!今回は「データ活用進めたいけど、何からやればいいの?」という方に向けて、troccoを使えば簡単に始められるお話しをしたいと思います。
大量のcsvやExcelをAWSのS3やGoogleドライブで保管している方も多くいると思います。
それでは見たいデータをすぐ確認できず、データ活用できてないですよね。そんな方達に向けて、troccoでGoogle BigQueryに転送すれば、爆速かつ手軽にデータ活用を始められることをお伝えできればと思います。
こんな方におすすめ
- データ活用進めたいけど何から始めればいいかわからない企業の方々
- 見たい情報をExcelのフィルター機能を使っているそこのアナタ
- 大量の情報を扱うのはpythonでcsv読み込むでしょ!と思っている人

ストレージに大量のcsvがあるのがデータ活用?!
かくいう私の前職もそうでした笑
S3や社内ストレージからcsvを切り出して、手元のローカルでpythonコード叩いて解析して..というのが当たり前に行われていました。もちろん、元のデータを可変させてはならない場合や高度な解析から始める場合に便利なこともあります。
むしろデメリットの方が多く、むしろデータを使ってビジネスに生かすのが億劫になる可能性の方が高いと感じてました。
以下、主なデメリットについて説明します。
1. 同時に複数のデータを参照するのが困難
例えば、小売業でのデータ活用の場合を考えてみましょう。
店舗ごとの商品購入データ、人流データ、ガラポンくじなどのイベントの集客データ、クーポン発行時の顧客の利用データ....などここに書ききれないほどの膨大なデータ量があります。
本日分のある店舗の購買データを見たくなった場合に、いちいちcsvを切り出してフィルター機能使って、日付と店舗を指定して...となると毎回フィルターを変えたりしないといけないですし、フィルターを変えてしまったら前調べた情報消えちゃいますよね。
2. 他のデータとの連結も一苦労
見たいデータを参照するだけ一苦労だったのですが、データ同士を結合させるとなるとより煩雑になってきます。
小売業の例を考えてみましょう。クーポンを発行した際に、お客さんが他にどのような商品を店長が知りたいと言った場合を想定します。
となると、商品購入データとクーポンの利用データを結合させる必要があるのですが、csvの場合手で結合させる部分をコピペして..となるとミスも発生しやすいですし、処理工数も高いです。
また、pythonを使う場合でもできますが、最終的な出力がcsvになってしまうのと複数同時処理が大変で、1.の課題が解消されません。以下結合例を示しますが、これで覚えないといけない一番簡単な処理と思ってください。
import pandas as pd
df1 = pd.read_csv('"商品購入データ".csv')
df2 = pd.read_csv('"クーポンの利用データ".csv')
# 連結させるにはpandasのmergeを使います
df = pd.merge(df1, df2, on='"共通の結合させたい列名"', how='inner')
df.to_csv('"つけたい名前".csv')
データ活用に向けてBigQuery(BQ)を選定するワケ
というわけで、csvのままデータ活用をするのが難しいことが理解できました。
csv等のデータは構造化データと呼ばれ、SQLという構造化データのデータの切り出しに最適な言語が存在します。
SQLに対応する中に、OracleやPostglesといったデータベースもありますが、Google社が出すBigQuery(以下BQ)を私はオススメしたいと思います。
BigQueryを使う主なメリットは以下3つが考えられます。
1.Googleのアカウントがあれば誰でも始められる!
導入コストについてですが、Oracleなどの市販データベースであれば、莫大なお金をかけてアカウント発行して..とかなり大変です。
しかし、BQであればGoogleのアカウントさえあればアカウント発行の手間も要りません!また導入を検討する段階で無料のサンドボックス機能もあり、実際に使い心地を確認してから導入が可能です。
2. プレビュー機能が超便利!
BQ内でSQLを叩いてデータの中身を確認することも可能です。
これに加えて、テーブルを複数複数同時に見たい場合やデータの中身をサクッと参照する際に、BQではプレビュー機能があり、GUI上で中身を簡単に確認することができます。
便利ですよね。

3. 機械学習や地理情報も扱える!
より高度なデータ活用を目指すにあたっては機械学習での予測や、GPSのデータも対象になってきます。BQMLという機械学習が内包されている機能があり、比較的学習コストをかけることなく高度な分析が可能です。
また、地理空間情報はGeojsonやshapeといった非構造データの形式になっています。BQには地理空間データに対しても比較的学習コストをかけることなく移行することが可能です。(こちらの記事を参考に)
BQ転送にtroccoを使うメリット
BigQueryには直接csvをインポートできるほか、Googleスプレッドシート、S3のデータといった外部機能とも連携可能です。
しかし、長期的にデータ活用を推進する上では、troccoを活用した方がメリットが大きい場合があると思ってます。
先にあげた、小売業の例を考えてみましょう。データ活用が進み、クーポンだけでなく、Lineやfacebook等で宣伝広告をしたり、Googleplayなどのアプリのデータも商品購入データとの連結が必要になることも多いと思います。
troccoでは、あらゆるデータを活用できるように、約100種類以上ののコネクタにに対応しています。下記写真は一例になります。

また、csvの転送する際も、プレビュー機能を使って転送元の中身のデータをあらかじめ確認できます。(後程の章で詳しく説明します)
BQにはこの機能で、csvを読み込んでエラーになるかならないかをいちいち確認する手間が発生します。troccoでは、事前にエラーになるかならないかを確認できるのはプレビュー機能にはあります。
S3からBQへの転送手順
troccoを活用し、csvデータをBQに格納し、データ活用を推進するお話をしてきました。
最後に、csvの格納場所としてポピュラーなAWSのS3にあるデータを、troccoを活用して、BQに転送する手順を紹介したいと思います。
データ活用これから..という方には難しく感じるかもしれませんが、csvやスプレッドシートに関してはより簡単な手順になります。まずは険しい山を登って、勾配のゆるい坂をスイスイ登っていきましょう〜
step0 事前に準備するもの
転送前に、認証情報が必要になります。それは...
- 転送元であるS3のAWS IAMユーザー
- Googleのアカウント
のたった2つだけ!では実際の転送に入っていきましょう。
step1 S3の認証情報であるIAMユーザーの登録
まずはtroccoの新規転送設定を開き、転送元S3→ 転送先BQで設定を行います。

次にS3バケットの情報...といきたいところですが、AWS IAMユーザーの認証登録が必要になります。
AWSが初学者の方にお話しすると、AWSの認証が必要な理由としては、「そのユーザーがAWSに入る権限があるかどうか」を承認してくれるものがAWSのIAMユーザーの番号になります。
では実際の登録に参りましょう。troccoの転送設定の「②転送元Amazon S3の設定」から認証情報の追加をクリックします。

そうすると下記画面が出てくるので、IAMユーザーの認証を登録し、接続が確認できるかを検証します。

写真のように「認証の確認」チェックマークがつけば接続情報が登録されています。
step2 S3の情報を設定する
次に転送元のS3のファイル名とバケット名を指定していきます。
今回は、"qiita-s3-bq"というバケットにあるcategory.csvというファイルを転送します。

csvの中身はこんな感じ。惣菜コーナー等のおいしそうな食材の種類が記載されてますね。
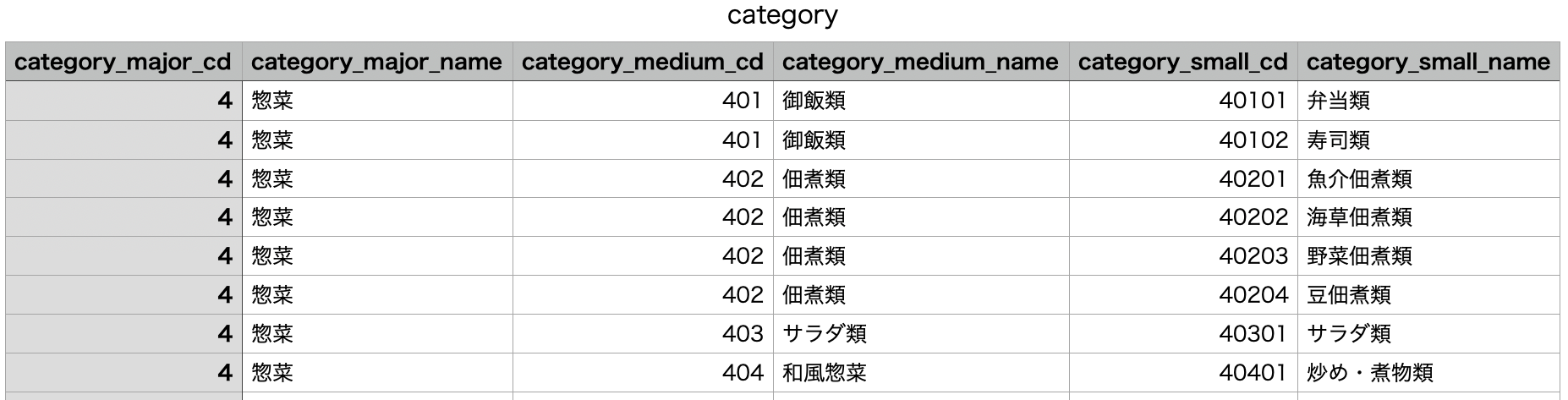
このcategory.csvのS3の情報を記載していきます。
S3の情報を参考にして、下記写真のように記載してください。転送方法ですが、今回は不変のデータ(日時で更新のないもの)なので、全件転送設定します。差分転送や全件転送の違いや、その他の詳細の設定は公式のドキュメントをご確認ください。

S3の接続情報と同様に、接続確認の箇所でチェックがつけば設定完了となります。
仮につかなかった場合は、指定のバケットにIAMの権限がない場合が考えられます。
troccoはバケットまでの疎通情報しか確認できないので、バケット以下のフォルダーに権限がある場合は実際に転送してうまくいくかどうか確認しないとわからない仕様となってます。(詳細は公式ドキュメントをご確認ください。)
step3 BQの認証情報であるGoogleアカウント登録
次に、S3と同様にBQについてもGoogleアカウントの認証を行います。右の接続認証追加ボタンから、Googleの認証を行います。
今回は、Googleアカウントを持っている状態なので、メールアドレス・BQのプロジェクト名を設定します。


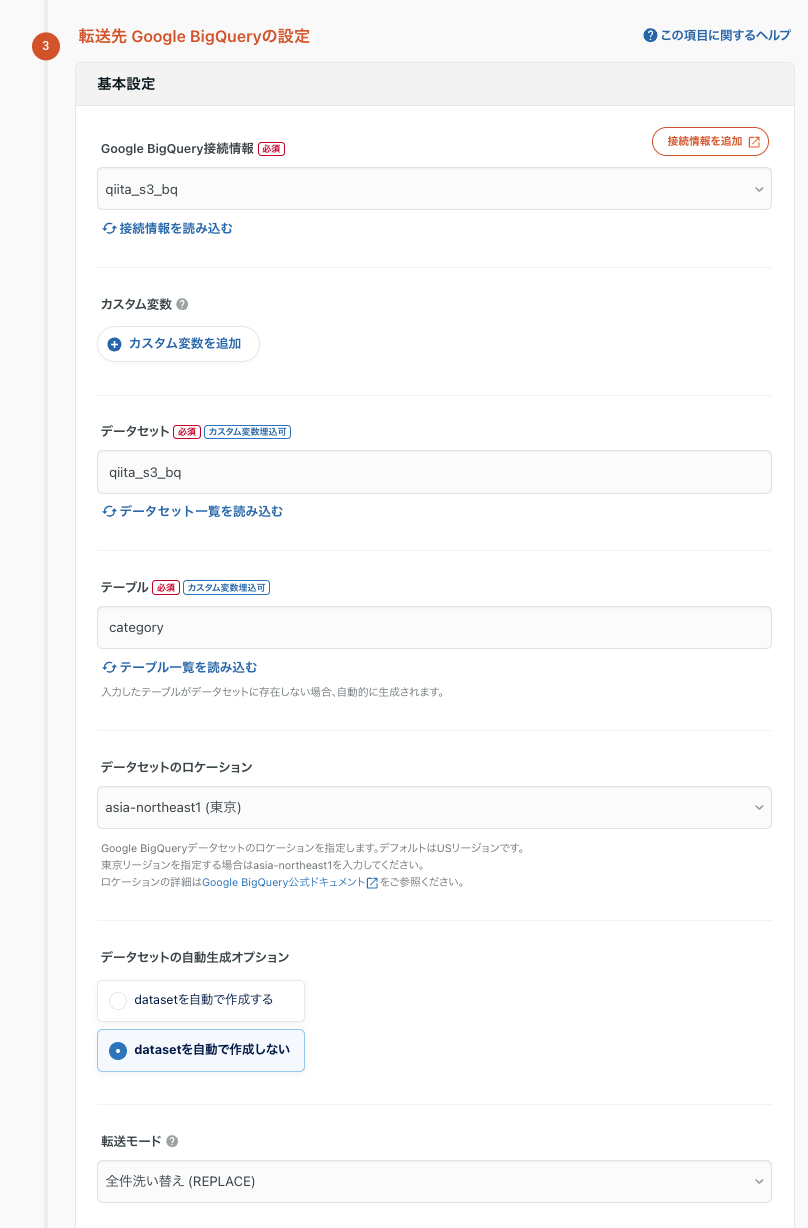
step4 転送先のBQ情報
次に、転送先のBQの情報を記載していきます。転送先のデータセットとテーブル名を書いていきます。(今回はS3と同名のもので設定)
また転送モードは、データが不変なので、「全件洗い替え」(replace)でいきたいと思います。他の転送モードやその他設定の詳細が気になる方は公式ドキュメントをご確認ください。接続情報の確認もS3と同様の仕様になってます。
step5 転送前のプレビュー把握
転送前最後の設定になります。
step1でS3とBQの情報を設定した後、step2では設定のプレビューが見れます。
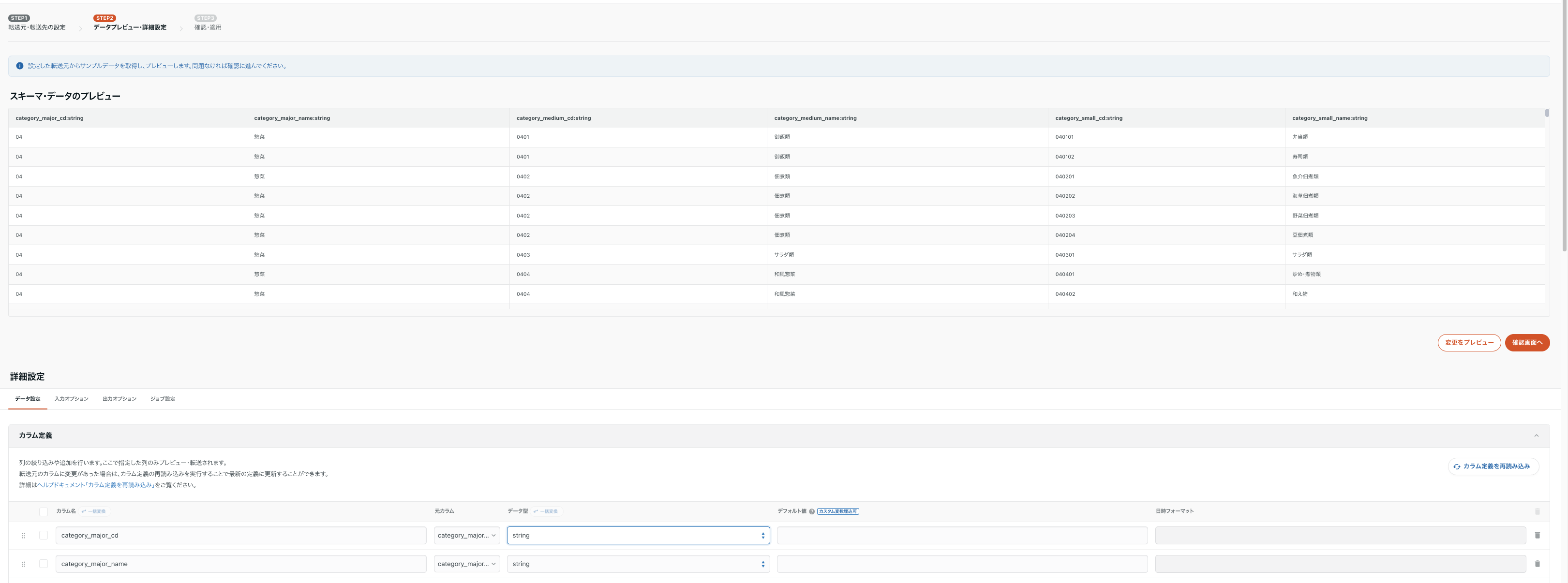
このプレビューでは転送後どのようなデータになるか確認できるほか、下段のようにカラム定義ができます。今回は全てstrig型で送ります。
また、trocco独自の機能としてマスキング処理が可能です。これは、メールアドレスやお客さんの氏名といった秘匿情報を扱い場合有効です。デフォルトが*になっており、今回はcategory_small_cdをマスキングしたいと思います。

step6 実際の転送
最後に、実際に転送していきましょう!
転送設定から今回設定したものを選択し、実行をクリックします。

実際転送されたかについては、BQを確認します。
見てみると..."qiita_s3_bq"の箇所にcategoryというテーブルが存在しました!
型設定も全てstringで意図通りです。
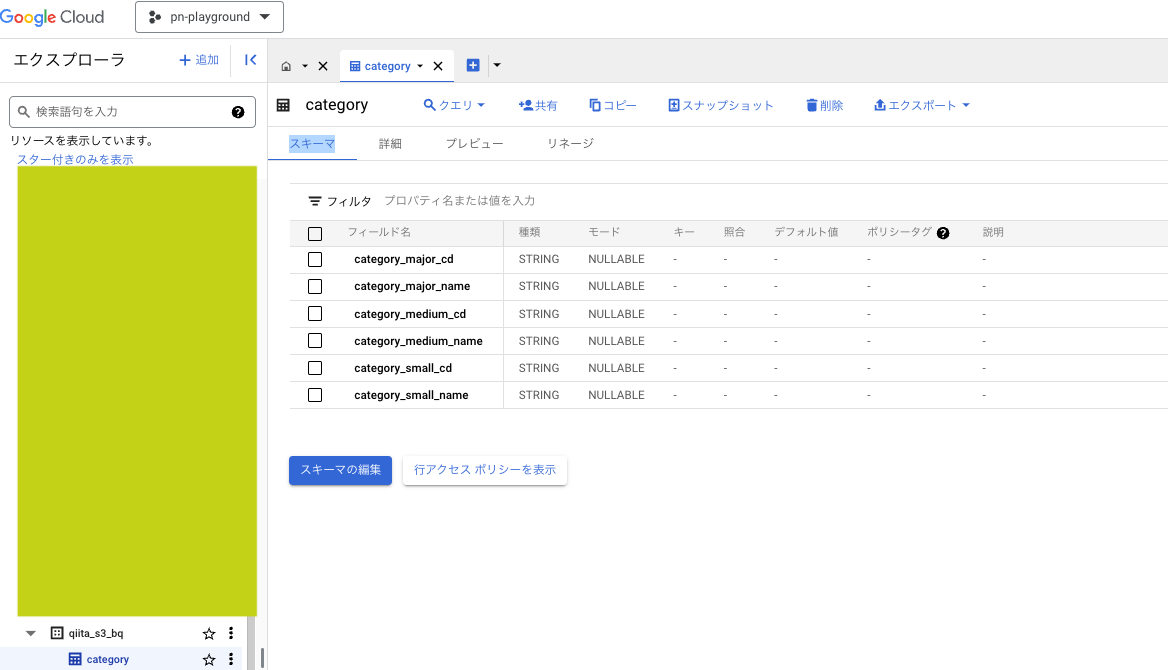
中のテーブルもプレビュー機能見る限り問題なく転送されており、category_small_cdの箇所が意図通りマスキングされてます。
おわりに 〜これからデータ活用を進めたいアナタへ〜
今回は、これからデータ活用を進めたい方向けに、troccoのポピュラーな処理である「S3→BQ」をご紹介しました。
前職時代の私もそうでしたが、多くの企業ではcsvでのデータ保管がされています。しかし、SQLを使って構造化データを扱うことは先にあげたようにもメリットも多いです。さらに、今回紹介したBQであれば高度な分析も対応可能かつ敷居が低いので始めやすいと思ってます。BQは回転数早くデータ活用するのにはうってつけですので、troccoを活用して始めてみてはいかがでしょうか。
最後に今回使ったデータcategory.csvはデータ分析100本knock(構造化データ加工編)からとってきました。
この教材は、これからSQLを始める方にとってみると、SQLの所作や構造化データがどのような加工のされ方をするのかを体系的に学べるものになってます。 データ活用始めたい方にとってみると良質な教材ですので、ぜひお手にとってみてください。