モチベーション
エンジニアの皆さんは普段の開発でリレーショナルデータベースを触る機会が多いと思われますが、SQLで読み書きしているデータが最終的にどのような形で保存されているかみたことありますでしょうか?
僕自身、データが実際にディスク上でどう管理されているかは知りませんでした。そこで今回、PostgreSQLが実際にどのような形式でデータを保存しているのか、バイナリファイルを直接覗いてみることにしました。
前提知識1: ページ
PostgreSQLは、テーブルやインデックスのデータをバイナリファイルとして保存します。これらのファイルはページという単位で構成されています。
ページとは
- ページ:PostgreSQLがディスクとやり取りする最小単位
- サイズ:デフォルトで8KiB(8192バイト)
データベースの文脈では、B-Treeインデックスにおける「ノード」に相当する概念をページと呼ぶ。
前提知識2: スロット化ページ
代表的なデータベースのページレイアウトとして、スロット化ページが利用される。スロット化ページの基本構造は、1つのページを3つの領域に分割して管理します。ページの先頭には固定長のヘッダーがあり、その直後にアイテムポインタが続きます。ポインタはページの後端に配置されるセル(実データ)をポイントしている。
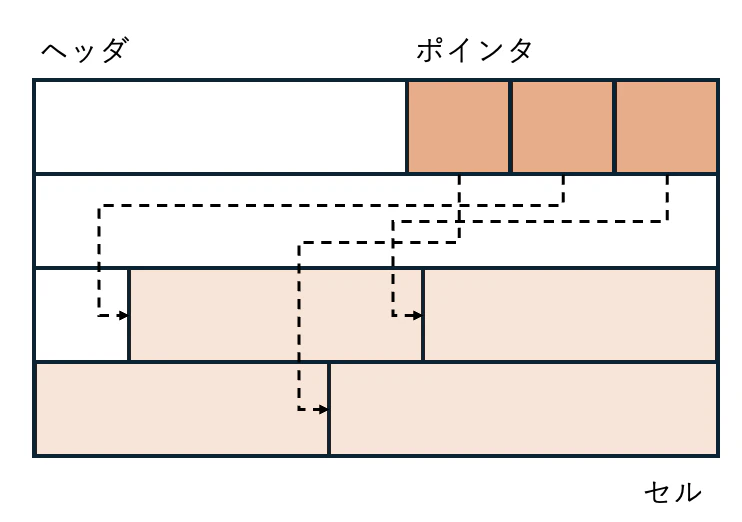
具体的なPostgreSQLのページレイアウトは次のサイトにまとめられている。: https://www.postgresql.org/docs/15/storage-page-layout.html
スロット化ページの利点
スロット化ページ構造の最大の利点は、データの物理的な移動を最小限に抑えられることです。
ページはB-Treeインデックスで利用される際にノードとして機能します。このとき、データの挿入や削除に伴い、ページ内でキーによるデータのソートを維持する必要があります。通常の配列構造では、データを挿入するたびに既存の要素を物理的にシフトする必要がありますが、スロット化ページではポインタを並べ替えるだけで済みます。
覗いてみる
それでは、実際にPostgreSQLのバイナリファイルを覗いてみましょう。まずは、できるだけシンプルなテーブルを作成して、そのデータがどのように保存されているかを確認します。今回は、INTEGER型の列を2つだけ持つテーブルを作成し、1行だけデータを挿入して、その内部構造を解析していきます。
-- PostgreSQLのインストールと起動(Homebrewを使用)
brew install postgresql@15
brew services run postgresql@15
-- テストデータベースを作成
createdb testdb
-- psqlでデータベースに接続
psql testdb
psqlに接続したら、以下のSQLを実行しリレーションを作成します。:
-- シンプルなテーブルを作成(INTEGER型の列を2つ)
CREATE TABLE simple_test (
id INTEGER,
value INTEGER
);
-- テストデータを挿入
INSERT INTO simple_test VALUES (1, 100);
-- テーブルが実際に保存されているファイルパスを確認
SELECT pg_relation_filepath('simple_test');
-- 結果例: base/16384/16388
-- これは「データディレクトリ配下の base/16384/16388 というファイル」を意味する
-- PostgreSQLのデータディレクトリの場所を確認
SHOW data_directory;
-- 結果例: /opt/homebrew/var/postgresql@15
上記2つの情報を組み合わせて、実際のファイルパスを特定します。例えば、データディレクトリが /opt/homebrew/var/postgresql@15 で、ファイルパスが base/16384/16388 の場合、実際のファイルは /opt/homebrew/var/postgresql@15/base/16384/16388 に存在します。
-- バイナリファイルの内容をhexdump形式で表示
-- 最初の8192バイト(1ページ分)だけを表示
head -c 8192 /opt/homebrew/var/postgresql@15/base/16384/16388 | hexdump -C
上記コマンドを実行すると、以下のようなhexdump形式の出力が得られます(一部抜粋):
このバイナリファイルはピッタリ8KiBとなっている。
00000000 00 00 00 00 60 d1 98 01 00 00 00 00 1c 00 e0 1f |....`...........|
00000010 00 20 04 20 00 00 00 00 e0 9f 40 00 00 00 00 00 |. . ......@.....|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001fe0 da 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00001ff0 01 00 02 00 00 08 18 00 01 00 00 00 64 00 00 00 |............d...|
バイナリファイルの構造
以下の画像は、hexdumpの出力結果に対して、それぞれのバイト列が何を示しているのかを色分けしたものです。
最初の24バイト(黄色)はページヘッダーを示しています。ページヘッダーには、LSN(Log Sequence Number)、チェックサム、pd_lower、pd_upperなどの情報が含まれています。
ページヘッダーの次の4バイト(オレンジ)がアイテムID(ItemId)です。今回は挿入したデータが1行だけなので、アイテムIDも1つだけ存在します。
アイテムIDはe0 9f 40 00 となっており、これをリトルエンディアンで解釈すると 0x00409fe0 になります。下位15ビットがオフセットを示しており、0x1FE0(10進数で8160)となります。つまり、このアイテムIDは「実際のデータ(タプル)がページの8160バイト目から始まる」ことを示しています。
実際に8160バイト目(00001fe0の位置)を見ると、オレンジ色で囲まれた部分にタプルヘッダーとデータが格納されています。タプルヘッダーの後(青色と緑色の部分)には、実際のデータである id: 1(01 00 00 00)と value: 100(64 00 00 00)が格納されていることが確認できます。

終わりに
学習のためにまとめました。間違いなどあれば勉強になりますためご指摘いただけると嬉しいです。