今回はMemSQLのSQL処理能力を検証します
過去数回に渡って実施してきたMemSQLの検証ですが、今回からは少し(かなり・・)無理矢理ではありますが、実際の処理に近い感じで検証を行ってみたいと思います。
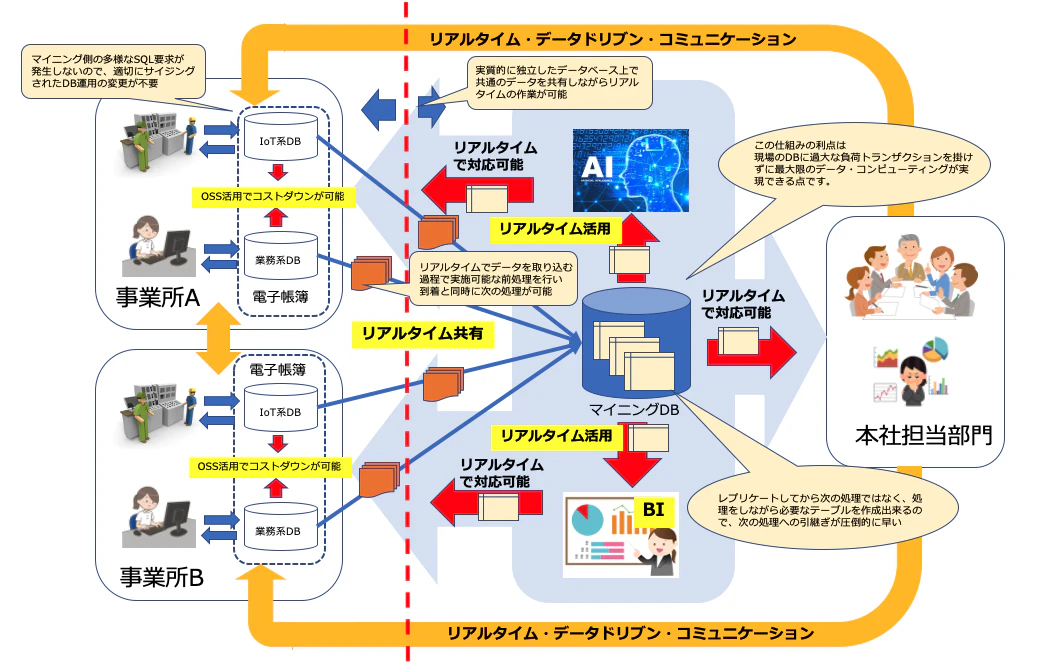
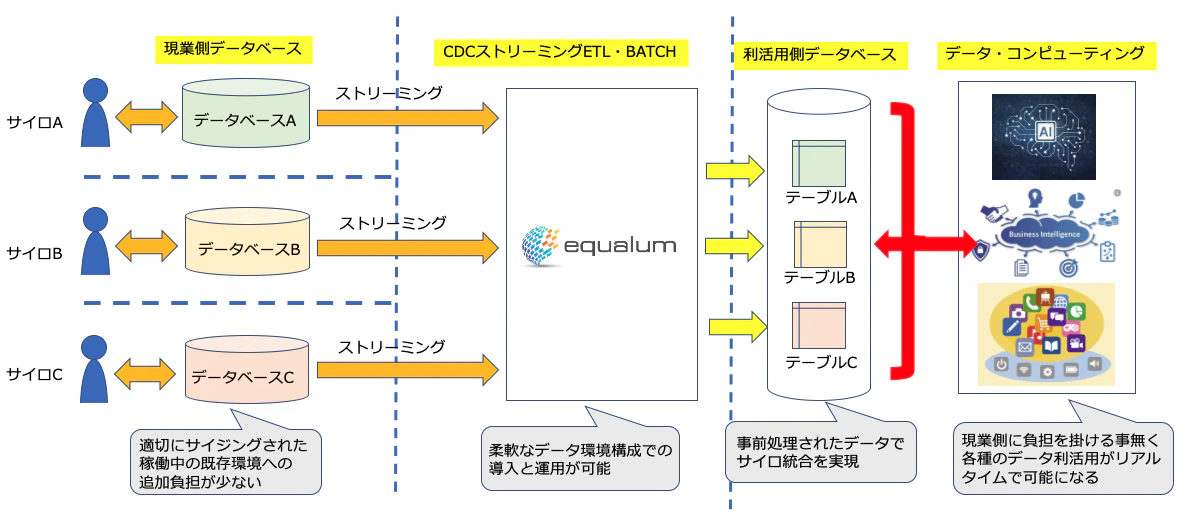
MemSQL自体は、インメモリで非常に高いMySQLとの互換性を持っていますが、その高いトランザクション性能を何処で活用するのか?と言う部分で、そこまで速い処理能力は必要ないです・・・といったコメントを頂くケースが有ります。そこで、今回はMemSQLを以前より検証している誰でもリアルタイム・ストリーミング処理が作れるEqualumのターゲット側データソースとして、さらにそこに準備されるデータを活用するAIやBI、また今後はAIとの境目が益々無くなるであろう各種のロボット系システムに対する、高速シュミレーション可能な知識ベース的位置付けの可能性を探ってみたいと思います。
想定シナリオ
MemSQL上にリアルタイムで販売情報が入ってくる状況で・・・
(1)一定時間間隔のバッチ処理的なSQLプロセスを走らせて、必要な情報を取り出してみる。
(2)最終的には抽出情報を新たなテーブルとして自動的に生成し、そのテーブルを活用した外部処理(Rを想定)と連携させてみる。
事にします。
ポイントは、MemSQL上に溜まるデータは、Equalumによって制御されるので
(1)どれだけSQLで弄っても、オリジナルのデータ提供側に対するトランザクション泥棒事象は発生しない。
(2)オリジナルデータは、枯れて安定稼働している既存データベースの上で、いつも通りに維持管理されるのでMemSQL側の仕組みは性能重視のデータ・コンピューティング仕様で構築できる。
(3)上流側の異なるデータベースから抽出されたデータを、MemSQL上で透過的SQL対象に出来るので、上流側データソース層を無理やり統合する必要が無い
といった利点が生まれる・・であろう!と言う都市伝説的(?)な仮説になります。
事前の準備
まずは、Pythonで自動的に連続処理を行う仕組みを作ります。今回は**”今は懐かし(?)のバージョン2.7”で取り急ぎ「動作優先」**で作成します(バージョン3向けは後日時間が有れば移植します・・(汗))
# coding: utf-8
#
# Pythonでタスクを一定間隔に実行する (力技バージョン)
# Version 2.7版
#
import sys
stdout = sys.stdout
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = stdout
# インポートするモジュール
import schedule
import time
#
# 此処に一定間隔で走らせる処理を設定する
#
def job():
print("********************************")
print(" 指定されたJOBを実行します ")
print("********************************")
from datetime import datetime
print ("JOBの開始日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
JOB_SQL = "SELECT DISTINCT * FROM Test_Table WHERE DATE_SUB(NOW(),INTERVAL 60 SECOND) AND Category = 'Test_Category' ORDER BY ts"
print JOB_SQL
print("********************************")
print(" 指定されたJOBを実行しました ")
print("********************************")
print
#
# 此処からメイン部分
#
def main():
# 使用する変数の設定
Loop_Count = 3
Count = 0
Interval_Time = 60
# 処理全体のスタート時間
from datetime import datetime
print ("プログラム開始日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
# 10分ごと
# schedule.every(10).minutes.do(job)
# 2時間ごと
# schedule.every(2).hours.do(job)
# 毎日10時
# schedule.every().day.at("10:00").do(job)
# 毎週月曜日
# schedule.every().monday.do(job)
schedule.every(Interval_Time).seconds.do(job)
# 無限ループで処理を実施
while True:
schedule.run_pending()
# 謎の呪文・・ww
time.sleep(Interval_Time)
# 規定回数をチェック
if (Count >= Loop_Count):
break
else:
Count += 1
print (str(Count) + "回 : 規定回数のJOBが終了しました!")
print
from datetime import datetime
print ("プログラム終了日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
if __name__ == "__main__":
main()
取り急ぎの動作チェックを行います。
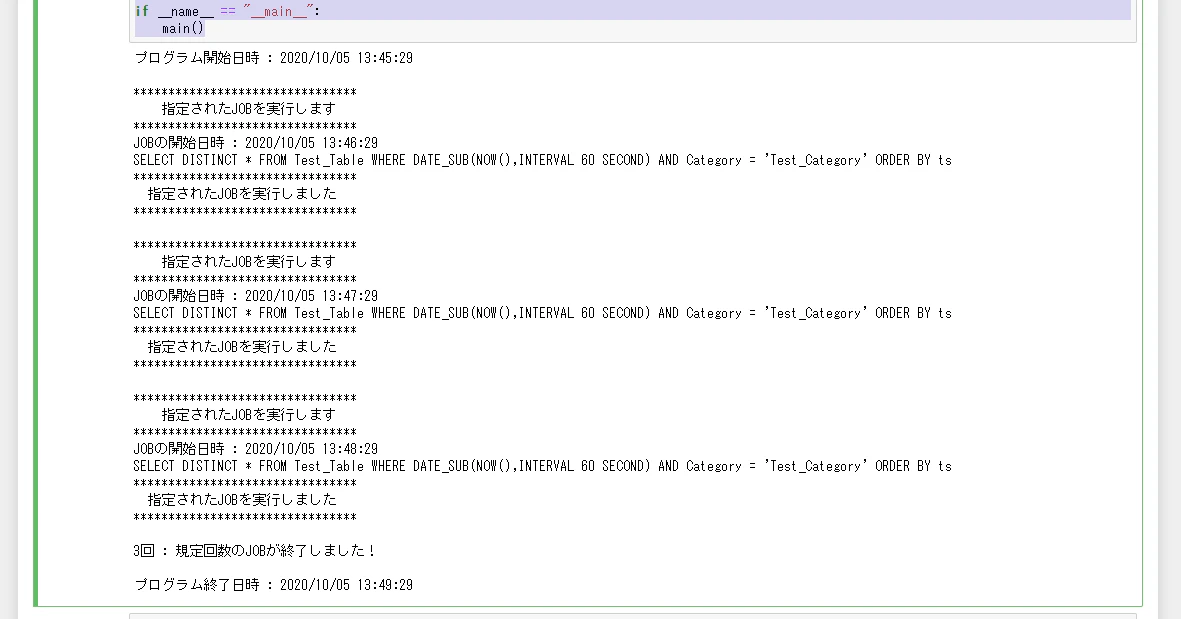
MemSQL上にオリジナルのデータテーブルを作成する
次にMemSQL上にオリジナルのデータを挿入していく為のテーブルを作成します。
これも力業になりますが、Pythonで以下の通りに設定します。
# coding: utf-8
#
# MemSQL上に集中型の売り上げデータテーブルを作成
# Version 2.7版
#
# 初期設定
import sys
stdout = sys.stdout
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = stdout
import time
# MemSQLのMySQL互換によりこれが活用出来ます!
import pymysql.cursors
# 既存のテーブルを初期化
Table_Init = "DROP TABLE IF EXISTS Qiita_Test"
Table_Make = "CREATE TABLE IF NOT EXISTS Qiita_Test"
# テーブル定義 (取り敢えずエイヤーっ!で列記しています)
DC0 = "id BIGINT AUTO_INCREMENT, ts TIMESTAMP(6), PRIMARY KEY(id, ts), "
DC1 = "Category VARCHAR(20), Product VARCHAR(20), Price INT, Units INT, "
DC2 = "Card VARCHAR(40), Number VARCHAR(30), Payment INT, Tax INT, "
DC3 = "User VARCHAR(20), Zip VARCHAR(10), Prefecture VARCHAR(10), Address VARCHAR(60), Tel VARCHAR(15), Email VARCHAR(40)"
# 処理開始
print("****************************************************")
print("MemSQL上に検証用の集中型売り上げテーブルを作成します")
print("****************************************************")
from datetime import datetime
print("テーブル作成処理の開始日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
try:
# MemSQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='qiita',
password='adminqiita',
db='Test',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 既存テーブルの初期化
cursor.execute(Table_Init)
db.commit()
# 新規にテーブルを作成
cursor.execute(Table_Make+"("+DC0+DC1+DC2+DC3+")" )
db.commit()
except KeyboardInterrupt:
print("************************")
print('!!!!! 割り込み発生 !!!!!')
print("************************")
print
finally:
# データベースコネクションを閉じる
db.close()
print("****************************************************************")
print("MemSQL上に検証用の集中型売り上げテーブルを作成処理が終了しました")
print("****************************************************************")
print ("テーブル作成処理の終了日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
Fakerを使って強引に検証用データを生成して挿入する
今回の検証も、Python定番のFakerを使った”なんちゃって”データ生成を行います。取り急ぎデータが生成されるという事を優先に力技で以下の通りに準備しました。実際の検証の際には、このスクリプトを連続して走らせながら、MemSQL上にメインのテーブルを成長させつつ、そのテーブルに対してSQLパターンを幾つか投げて処理をさせて結果を入手する・・事にします。
# coding: utf-8
#
# MemSQL上の集中型売り上げテーブルにデータを連続挿入する
# Version 2.7版
#
# 初期設定
import sys
stdout = sys.stdout
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = stdout
import time
import pymysql.cursors
import re
# SQLで使う命令設定
SQL_Head = "INSERT INTO Qiita_Test"
# 検証で使うメタデータ定義
Category_Name = ["酒類","家電","書籍","DVD/CD","雑貨"]
Product_Name0 = ["日本酒","バーボン","ビール","芋焼酎","赤ワイン","白ワイン","スコッチ","ブランデー","泡盛","テキーラ"]
Product_Price0 = [1980, 2500, 490, 2000, 3000, 2500, 3500, 5000, 1980, 2000]
Product_Name1 = ["テレビ","洗濯機","ラジオ","ステレオ","電子レンジ","パソコン","電池","エアコン","乾燥機","掃除機"]
Product_Price1 = [49800, 39800, 2980, 88000, 29800, 64800, 198, 64800, 35800, 24800]
Product_Name2 = ["週刊誌","歴史","写真集","漫画","参考書","フィクション","経済","自己啓発","月刊誌","新刊"]
Product_Price2 = [280, 1500, 2500, 570, 1480, 1400, 1800, 1540, 980, 1980]
Product_Name3 = ["洋楽","演歌","Jポップ","洋画","アイドル","クラッシック","邦画","連続ドラマ","企画","アニメ"]
Product_Price3 = [1980, 2200, 2500, 3500, 2980, 1980, 3800, 2690, 1980, 2400]
Product_Name4 = ["洗剤","電球","贈答品","医薬部外品","ペットフード","乾電池","文房具","男性用品","女性用品","季節用品"]
Product_Price4 = [498, 198, 1980, 398, 980, 248, 398, 2980, 3580, 1980]
# 書き込み用のデータカラム(テーブルの生成と合わせておきます)
DL1 = "Category, Product, Price, Units, "
DL2 = "Card, Number, Payment, Tax, "
DL3 = "User, Zip, Prefecture, Address, Tel, Email"
# デモ処理開始
print("********************************************************************")
print("MemSQL上の集中型売り上げテーブルにデータの自動生成&挿入を開始します")
print("********************************************************************")
print
from datetime import datetime
print("データ挿入処理の開始日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
try:
# Pythonのデータ自動生成機能の設定
from faker.factory import Factory
Faker = Factory.create
fakegen = Faker()
fakegen.seed(0)
fakegen = Faker("ja_JP")
# 各種変数定義
# 生成するデータの総数 -> ここは適宜変更
##########################################################
Loop_Count = 10000
##########################################################
# タイミング調整フラグ (0:待ち時間無し 1:1秒 2:ランダム)
##########################################################
Wait_Flag = 2
##########################################################
# 後々でデモっぽくするために、幾つかのオプションを用意しました。
# 一定間隔の場合(システム時間で秒単位)
Sleep_Wait = 1
# ランダム間隔の場合(実態に合わせて調整)
Base_Count = 500000
# その他の変数
Counter = 0
Work_Count = 1
# MemSQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='qiita',
password='adminqiita',
db='Test',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 検証データの生成
while Counter < Loop_Count:
# ランダムに書き込む商材の種類を選択(今回は5種類なので強制的に0-4へ変換します)
Category_ID = fakegen.random_digit()
if Category_ID > 4: Category_ID = Category_ID - 5
# カテゴリ名の設定
Category = Category_Name[Category_ID]
# 各カテゴリ内の10種の商品を選択
Product_ID = fakegen.random_digit()
# 条件に合ったカラム情報を選択
# 個数はそれっぽく調整しています
if Category_ID == 0:
Product = Product_Name0[Product_ID]
Price = Product_Price0[Product_ID]
Units = fakegen.random_digit() + 1
elif Category_ID == 1:
Product = Product_Name1[Product_ID]
Price = Product_Price1[Product_ID]
Units = 1
elif Category_ID == 2:
Product = Product_Name2[Product_ID]
Price = Product_Price2[Product_ID]
Units = fakegen.random_digit() + 1
if Units >3: Units = 3
elif Category_ID == 3:
Product = Product_Name3[Product_ID]
Price = Product_Price3[Product_ID]
Units = fakegen.random_digit() + 1
if Units >2: Units = 2
else:
Product = Product_Name4[Product_ID]
Price = Product_Price4[Product_ID]
Units = fakegen.random_digit() + 1
if Units >4: Units = 4
# 支払い情報
if str(fakegen.pybool()) == "True":
Card = "現金"
else:
Card = fakegen.credit_card_provider()
Number = fakegen.credit_card_number()
if Card == "現金": Number = "N/A"
# 支払総額と消費税を計算
Payment = Price * Units
Tax = Payment * 0.1
# 購入者情報の生成
User = fakegen.name()
Zip = fakegen.zipcode()
Address = fakegen.address()
# 都道府県情報の抽出
pattern = u"東京都|北海道|(?:京都|大阪)府|.{2,3}県"
m = re.match(pattern , Address)
if m:
Prefecture = m.group()
Tel = fakegen.phone_number()
Email = fakegen.ascii_email()
# 此処から先を各データベースの規程テーブルへ書き込みます
DV1 = Category+"','"+Product+"','"+str(Price)+"','"+str(Units)+"','"
DV2 = Card+"','"+Number+"','"+str(Payment)+"','"+str(Tax)+"','"
DV3 = User+"','"+Zip+"','"+Prefecture+"','"+Address+"','"+Tel+"','"+str(Email)
SQL_Data = SQL_Head +"("+DL1+DL2+DL3+") VALUES('"+DV1+DV2+DV3+"')"
cursor.execute(SQL_Data)
db.commit()
# コンソールに生成データを表示(不要な場合はコメントアウトする)
print SQL_Data
print
# 生成間隔の調整
if Wait_Flag == 1:
time.sleep(Sleep_Wait)
elif Wait_Flag == 2:
Wait_Loop = Base_Count * fakegen.random_digit() + 1
for i in range(Wait_Loop): Work_Count = Work_Count + i
# ループカウンタの更新
Counter=Counter+1
except KeyboardInterrupt:
print("************************")
print('!!!!! 割り込み発生 !!!!!')
print("************************")
print
finally:
# データベースコネクションを閉じる
db.close()
print("**************************************")
print("生成したデータの総数 : " + str(Counter))
print("**************************************")
print
print("************************************************************************")
print("MemSQL上の集中型売り上げテーブルへのデータの自動生成&挿入が終了しました")
print("************************************************************************")
print("データ挿入処理の終了日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
念のため動作をチェックしておきます。
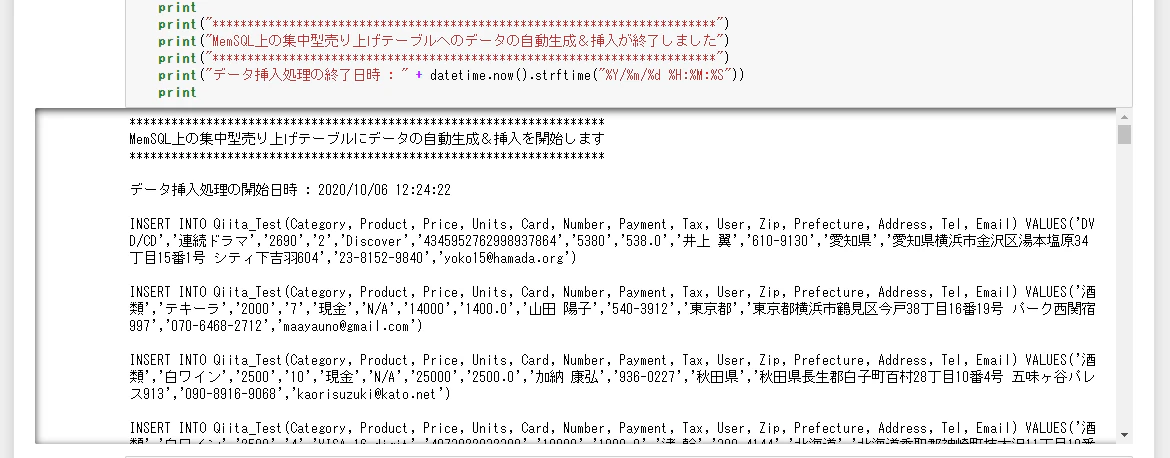
テーブルの内容も確認しておきます。
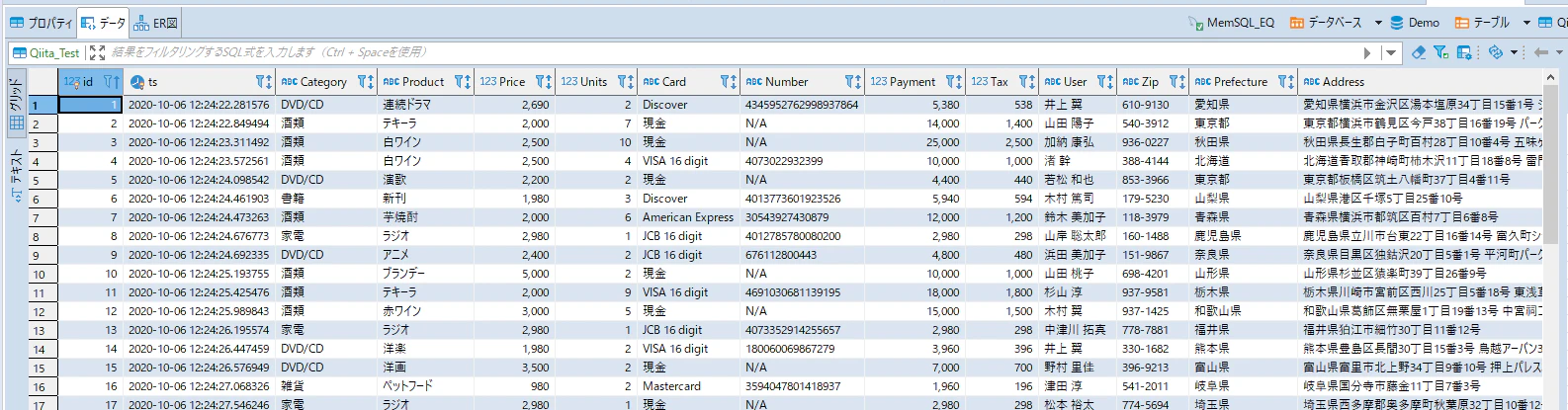
取り急ぎの検証を実施
最初に準備したスクリプトの**job()**部分を以下の様に変更します。(クエリの戻りを扱う部分は、今後の検証を意識した形にしてあります)
# 処理開始
from datetime import datetime
print ("JOBの実行日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
# MemSQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='qiita',
password='adminqiita',
db='Test',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 取り急ぎデータの挿入数をカウントするクエリを設定
SQL_Data = "SELECT Count(*) FROM Qiita_Test"
# クエリの送信してコミット
cursor.execute(SQL_Data)
db.commit()
# クエリの結果を取得
rows = cursor.fetchall()
# 作業用のバッファを初期化
Tmp_Data = []
# 今後クエリの内容が増える予定なのでその準備を兼ねて・・
for Query_Data in rows:
for item in Query_Data.values():
Tmp_Data.append(item)
print("この時点のデータ数:"+ str(Tmp_Data[0]))
print
db.close()
この検証では、5秒おきに3回実施するように変数設定しています。データ生成間隔は、少しリアル目を狙ったランダム間隔を設定して先に起動しておき、その後間髪を入れずに変更を加えたスクリプトを実行します。
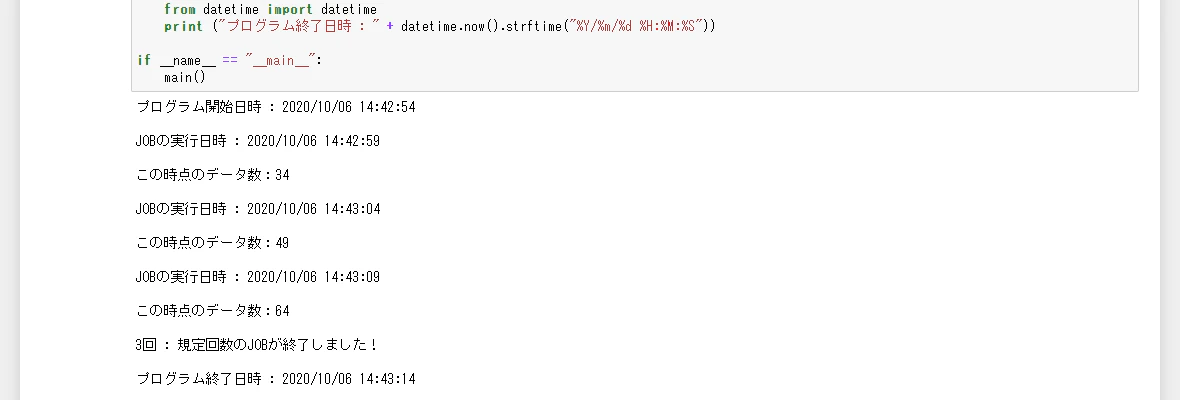
無事に動いた様なので、今回の準備編は此処までとしておきます。
次回は、定期処理用のテーブルと今回作成した**job()**の中身を少し増やしてみようと思います。
謝辞
本検証は、MemSQL社の公式Freeバージョン(V6)を利用して実施しています。
この貴重な機会を提供して頂いたMemSQL社に対して感謝の意を表すると共に、本内容とMemSQL社の公式ホームページで公開されている内容等が異なる場合は、MemSQL社の情報が優先する事をご了解ください。