今回は・・・・・
応用編1では、今回の検証で使用する環境整備を中心に作業を行いました。最後のSQLクエリ処理が想定通りに動きましたので、今回の検証ではその先の処理を検証して行く事にします。
最終的な目標は・・・
(1)データの生成側(現場作業)と同じ時間帯で
(2)キッチリとサイジングされ、運用周りまで枯れた既存データシステムに新たな負荷を掛ける事無く
(3)サイロの壁を超えたリアルタイムのデータ活用を実現する・・・・
という事が可能か?を確認・・・になります。
キーワードは、今を変えて未来を創るです。
貯めてドン!型の処理では見えなかったモノを、必要な情報をリアルタイムで自分の側の都合に合わせて自動的に準備をし、オンデマンドで創造的なデータ活用を実現する・・・多分、新しい形のデータドリブンが可能になるでしょう。
まずはシンプルにSQLクエリだけを繰り返し投げてみる
SQL的には基本系だと思いますが、先ずは集計系の関数を幾つかの条件に適合したデータに対してクエリしてみる事にします。
(1)自動生成された”なんちゃって販売情報”からカテゴリ別に集計系の処理を実施する。
(2)対象となる都道府県は、大阪府、東京都、福岡県、愛知県、北海道を選択して処理する。
(3)生成側が連続挿入しているデータベースのテーブルに対して、クエリを発行してその結果を確認する。
で行く事にします。
取り急ぎ処理を作成します。SQL文については、意図的に判読しやすい形(後でパターンを変えて実施する事を想定)にしていますが、効率的にはもう少し工夫出来るかと思います。また、次回以降のタイミングで、抽出対象のカラムを選択して別の新規テーブル(その内応を解析に回す想定)を作成する予定ですので、今回の処理の中にもこの操作を意識した書き方を取り込みました。
# coding: utf-8
#
# Pythonでタスクを一定間隔に実行する (力技バージョン)
# Version 2.7版
#
import sys
stdout = sys.stdout
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = stdout
# インポートするモジュール
import schedule
import time
#
# 此処に一定間隔で走らせる処理を設定する
#
def job():
# 今回使う集計系のSQLを設定します。
# 色々と試せるように意図的に分けてます・・・
SQL1 = "SELECT SUM(Units) AS Sum_of_Units, AVG(Payment) AS Avarage_of_Payment, "
SQL2 = "MAX(Payment) AS Max_of_Payment, MIN(Payment) AS Min_of_Payment, Category "
SQL3 = "FROM Qiita_Test "
SQL4 = "WHERE Category IN ('酒類','雑貨','書籍','家電','DVD/CD') "
SQL5 = "AND Prefecture IN ('大阪府','東京都','福岡県','愛知県','北海道') "
SQL6 = "GROUP BY Category"
SQL_Data = SQL1 + SQL2 + SQL3 + SQL4 + SQL5 + SQL6
# 処理開始
from datetime import datetime
print ("JOBの実行日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
# MemSQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='qiita',
password='adminqiita',
db='Test',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 作業用のバッファを初期化
Tmp_Data = []
# クエリの送信してコミット
cursor.execute(SQL_Data)
db.commit()
# クエリの結果を取得
rows = cursor.fetchall()
# 今後クエリの内容が増える予定なのでその準備を兼ねて・・
for Query_Data in rows:
for item in Query_Data.values():
Tmp_Data.append(item)
print
print("商材区分 : " + str(Tmp_Data[0]))
print("最低売価 : " + str(Tmp_Data[1]))
print("最高売価 : " + str(Tmp_Data[2]))
print("売価平均 : " + str(Tmp_Data[3]))
print("販売総数 : " + str(Tmp_Data[4]))
print
Tmp_Data = []
#データベース接続を閉じます
db.close()
#
# 此処からメイン部分
#
def main():
# 使用する変数の設定
Loop_Count = 3
Count = 0
Interval_Time = 60
# 処理全体のスタート時間
from datetime import datetime
print ("プログラム開始日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
# 10分ごと
# schedule.every(10).minutes.do(job)
# 2時間ごと
# schedule.every(2).hours.do(job)
# 毎日10時
# schedule.every().day.at("10:00").do(job)
# 毎週月曜日
# schedule.every().monday.do(job)
schedule.every(Interval_Time).seconds.do(job)
# 無限ループで処理を実施
while True:
schedule.run_pending()
# 謎の呪文・・ww
time.sleep(Interval_Time)
# 規定回数をチェック
if (Count >= Loop_Count):
break
else:
Count += 1
print (str(Count) + "回 : 規定回数のJOBが終了しました!")
print
from datetime import datetime
print ("プログラム終了日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
if __name__ == "__main__":
main()
実行結果は・・・
MemSQLに対して、自動的に無作為ランダムなデータの連続生成・挿入を開始し、先ほど作成したスクリプトを走らせた結果が以下の通りです。今回はデータが有る程度溜まってから処理をさせたかったので、各回の実行間隔は60秒に設定し3回の実行を行いました。(実際には30秒とかでも問題有りません)
プログラム開始日時 : 2020/10/06 16:46:54
JOBの実行日時 : 2020/10/06 16:47:54
商材区分 : 家電
最低売価 : 35800
最高売価 : 88000
売価平均 : 51840.0000
販売総数 : 5
商材区分 : 書籍
最低売価 : 1710
最高売価 : 5940
売価平均 : 3825.0000
販売総数 : 6
商材区分 : 雑貨
最低売価 : 1592
最高売価 : 3580
売価平均 : 2586.0000
販売総数 : 5
商材区分 : 酒類
最低売価 : 9000
最高売価 : 18000
売価平均 : 12750.0000
販売総数 : 23
商材区分 : DVD/CD
最低売価 : 4400
最高売価 : 5960
売価平均 : 5246.6667
販売総数 : 6
JOBの実行日時 : 2020/10/06 16:48:54
商材区分 : 家電
最低売価 : 198
最高売価 : 88000
売価平均 : 38177.8000
販売総数 : 10
商材区分 : 書籍
最低売価 : 280
最高売価 : 5940
売価平均 : 2601.6667
販売総数 : 14
商材区分 : 雑貨
最低売価 : 1592
最高売価 : 3580
売価平均 : 2254.6667
販売総数 : 9
商材区分 : 酒類
最低売価 : 3960
最高売価 : 50000
売価平均 : 16456.0000
販売総数 : 64
商材区分 : DVD/CD
最低売価 : 4400
最高売価 : 7600
売価平均 : 6188.0000
販売総数 : 10
JOBの実行日時 : 2020/10/06 16:49:54
商材区分 : 家電
最低売価 : 198
最高売価 : 88000
売価平均 : 44548.1667
販売総数 : 12
商材区分 : 書籍
最低売価 : 280
最高売価 : 5940
売価平均 : 2601.6667
販売総数 : 14
商材区分 : 雑貨
最低売価 : 396
最高売価 : 3580
売価平均 : 1790.0000
販売総数 : 11
商材区分 : 酒類
最低売価 : 2450
最高売価 : 50000
売価平均 : 13355.0000
販売総数 : 79
商材区分 : DVD/CD
最低売価 : 1980
最高売価 : 7600
売価平均 : 5633.3333
販売総数 : 17
3回 : 規定回数のJOBが終了しました!
プログラム終了日時 : 2020/10/06 16:50:54
ちなみに、同様にデータを挿入させながらMemSQLのSQLエディタ上で同じクエリを走らせた検証結果です。
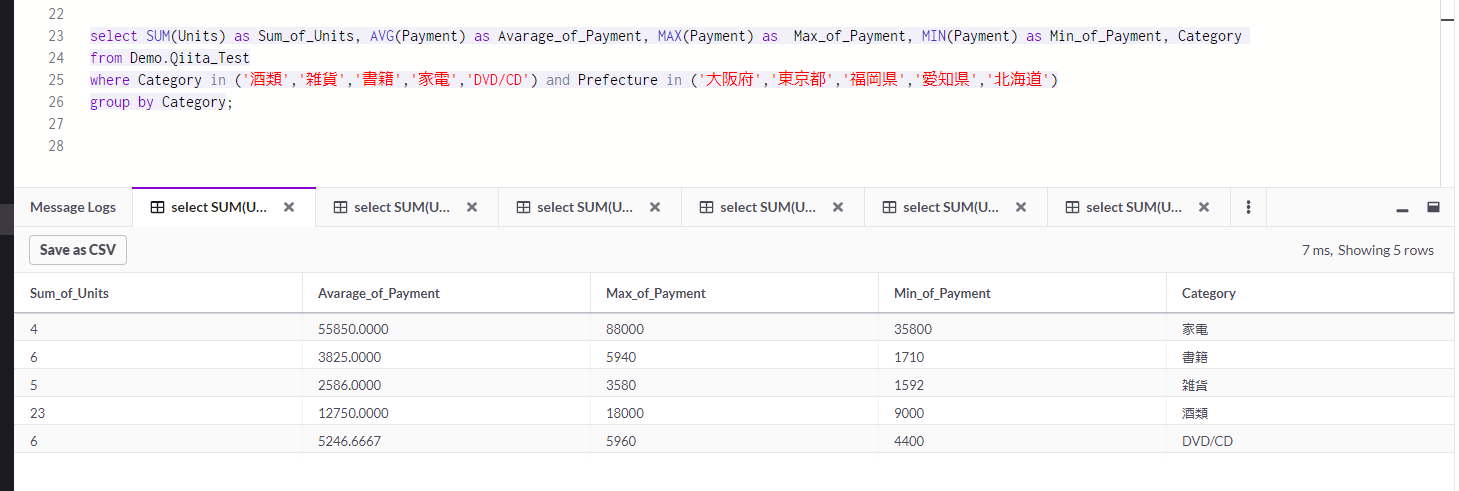
クエリの実行を時間推移に合わせて(ラフに時計を見ながら実施)行いましたが、実行時間的には数ミリ秒台で安定して処理を行ってくれました。以前、10万行の同様データに対して、このSQLクエリ(その場合は静的なテーブル状態に対して実施)を処理させましたが、それでも10ミリ秒台で結果をきちんと出してくれていましたので、実際の展開量に合わせてインメモリ領域をスケールさせ、また分散クラスタ処理を活用する事により、より大規模なデータ処理に対しても、劇的な性能での処理対応が期待出来るでしょう。
次回の前振り・・
次回は、いよいよ今回のSQL文を少し改造して、短い時間間隔でのスナップショット的なテーブル作成を自動的に行えるようにしたいと思います。MemSQLのインメモリ性能を活かす事により、Equalum経由でデータをリアルタイムに収集しつつ、MemSQLの爆発的な性能を活用して上流側にトランザクション負荷を掛ける事なく、必要なSQL処理をオンデマンドで実行し活用していく・・・事を検証出来ればと考えています。
また、余裕があれば意図的に複数のテーブルを作成し(サイロ化したデータシステムから抽出してきた・・をイメージ)それらのテーブル横断でSQLを走らせて結果を見る事にも挑戦したいと思います。
謝辞
本検証は、MemSQL社の公式Freeバージョン(V6)を利用して実施しています。
この貴重な機会を提供して頂いたMemSQL社に対して感謝の意を表すると共に、本内容とMemSQL社の公式ホームページで公開されている内容等が異なる場合は、MemSQL社の情報が優先する事をご了解ください。