今回はいよいよEqualumに接続します
前回は、準備編としてMBP上にkafka環境を導入し、Pythonを使った検証ツールを作成し、kafka上での動作確認までを行いました。今回はいよいよ具体的にkafkaのプロデューサに送りこまれたメッセージを、JSON形式に整えてEqualumの上流側データソースとして接続してみたいと思います。
まずは、受け側の準備
Equalumを通して受け取る側のデータソースを準備したいと思います。今回はMySQLをDocker上で動かして、この環境上に事前展開したテーブルに向かって、JSON形式をEqualumが通常のRDB系カラム情報に変換し、シンプルに連続して挿入処理を行う形にします。
MySQL側のテーブルを作る
基本的には、今までのパターンを修正して「サクッと!」準備してしまいます。
# coding: utf-8
#
# MySQL側のテーブル作成
#
# Python 3版
#
#
# 初期設定
import sys
stdout = sys.stdout
sys.stdout = stdout
import pymysql.cursors
# 作成するテーブル名
Table_Name = "kafka_TGT_Table"
# テーブル初期化
Table_Init = "DROP TABLE IF EXISTS "
# テーブル定義
DC0 = "ts_key VARCHAR(30) PRIMARY KEY, "
DC1 = "xx INT, yy INT "
try:
print("TGTテーブル作成処理を開始")
# デモ用のテーブルの作成
Table_Create = "CREATE TABLE IF NOT EXISTS " + Table_Name + " (" + DC0 + DC1 + ")"
# MySQLとの接続
db = pymysql.connect(host = 'localhost',
port=xxxx,
user='xxxxxx',
password='xxxxxxxxx',
db='xxxxx',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 既存テーブルの初期化
cursor.execute(Table_Init + Table_Name)
db.commit()
# 新規にテーブルを作成
cursor.execute(Table_Create)
db.commit()
except KeyboardInterrupt:
print('!!!!! 割り込み発生 !!!!!')
finally:
# データベースコネクションを閉じる
db.close()
print("TGTテーブル作成処理が終了")
検証用のトピックを作る
今回の検証に使うトピックを作ります。コマンドは前回の形式(最小構成なのでパーティション等は1個で対応します)で実行し、名前はTPC4JSONとします。
% kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TPC4JSON
Equalumの設定の際に、プレビューを使って説明したいので「テストを兼ねてコンシューマ側に向かって」少しデータを作成しておきます。このテスト分はEqualumが繋がったタイミングで「初期抽出」が自動的に行われます。コンソールを見ながら10個程度有れば十分なので、適当なタイミングで切り上げればOKです。
プロデューサ側の入力
{'id': '2021/04/11-08:18:59:171423', 'x': -1399, 'y': 85}
{'id': '2021/04/11-08:19:00:304312', 'x': -791, 'y': 476}
{'id': '2021/04/11-08:19:01:309313', 'x': -1001, 'y': 508}
///////// 途中省略 //////////
{'id': '2021/04/11-08:19:12:382028', 'x': 544, 'y': 200}
{'id': '2021/04/11-08:19:13:389613', 'x': 518, 'y': 205}
コンシューマ側の出力
読み出したデータ
1個目
Data ID: 2021/04/11-08:18:59:171423
Data X: -1399
Data Y: 85
読み出したデータ
2個目
Data ID: 2021/04/11-08:19:00:304312
Data X: -791
Data Y: 476
読み出したデータ
3個目
Data ID: 2021/04/11-08:19:01:309313
Data X: -1001
Data Y: 508
//////// 途中省略 ////////
読み出したデータ
14個目
Data ID: 2021/04/11-08:19:12:382028
Data X: 544
Data Y: 200
読み出したデータ
15個目
Data ID: 2021/04/11-08:19:13:389613
Data X: 518
Data Y: 205
!!!!! 割り込み発生 !!!!!
疎通が確認出来ましたので、いよいよ検証の本番に移ります。
Equalumの設定
次にEqualumの設定を行って行きます。
kafkaの接続も、基本的には他のデータソースと同じ様にGUIベースの設定項目を埋めて行く作業になります。
(1)ダッシュボードのSOURCES項目にある**+ADD**ボタンを選択

(2)kafkaを選択

(3)必要事項を設定
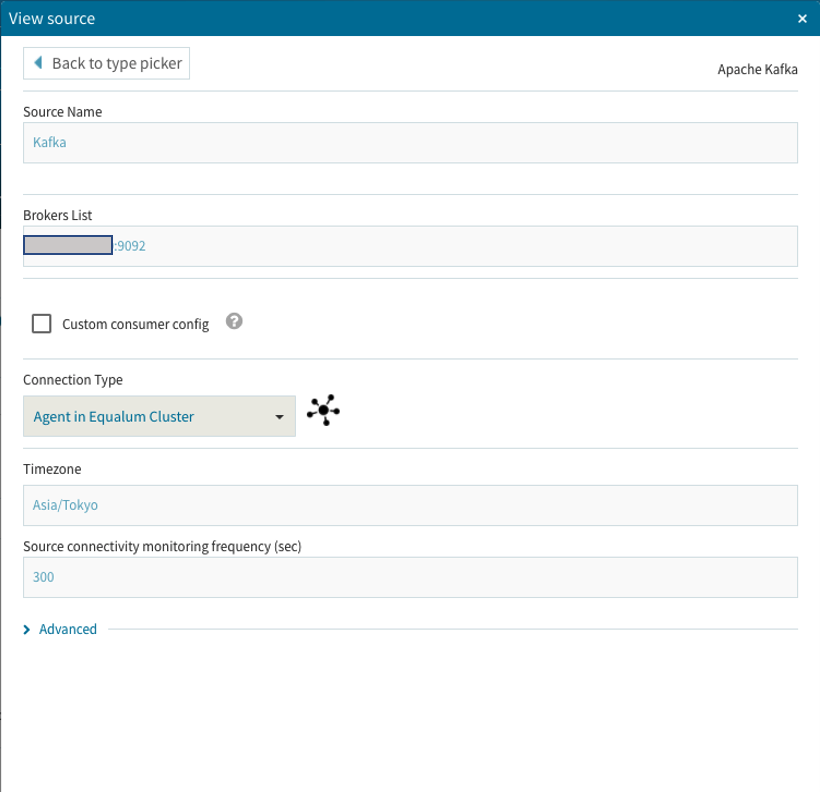
今回はオールインワンなのでBrokers Listは1個だけ**「IPアドレス:ポート番号」**で設定しました。
(4)設定したソースにトピックを登録
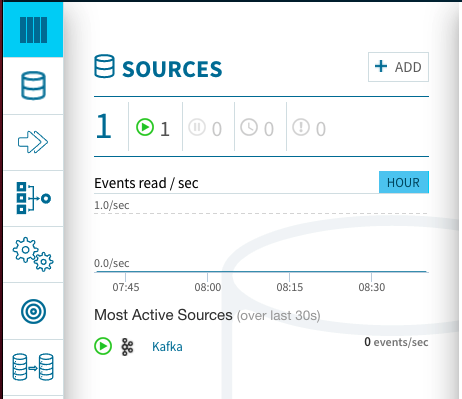
(4−1)ダッシュボードに先程のkafkaが登録されたら、そのソースを選択してトピックを登録します。
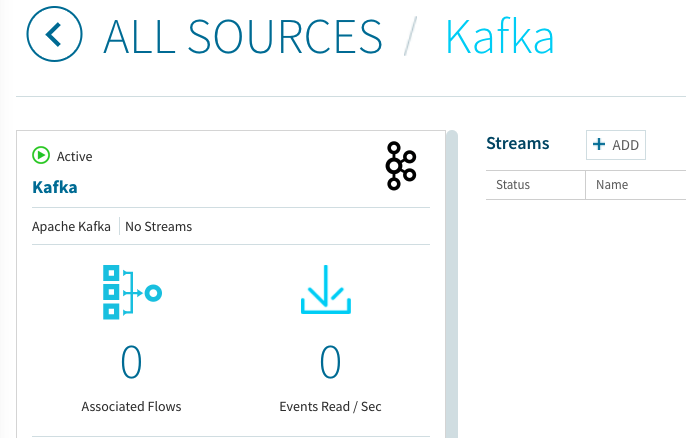
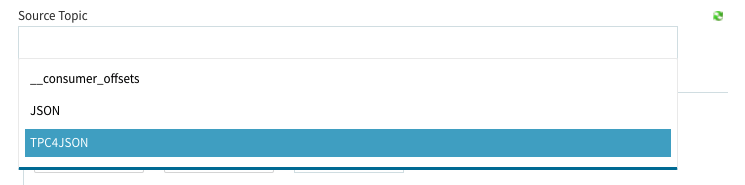
Streamsの右側にある**+ADD**ボタンを選択して、表示されるGUI上で必要な項目を設定します。先程のソース登録が正常に行われていると、Source Topicの所でプルダウンメニューが出てきて、事前に登録されたトピックが選択可能になっています。
File format optionsのプルダウンメニューからJSONを選択します。
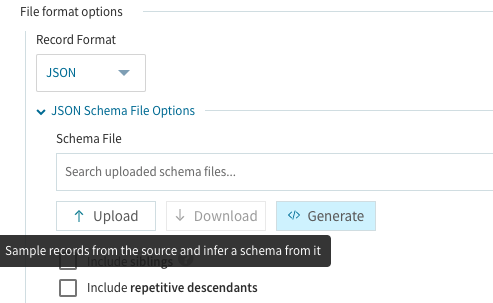
JSON Schema File Optionsの項目にあるSchema Fileの設定部分でGenerateを選択します。前もって正しい内容のファイルが有れば此処でアップロードする事も可能ですが、今回はEqualum任せでサクッと!前に進める事にします。
次にTag Name to Eventを設定します。今回はシンプルな形式ですので、デフォルトの**/root**を選択しました。

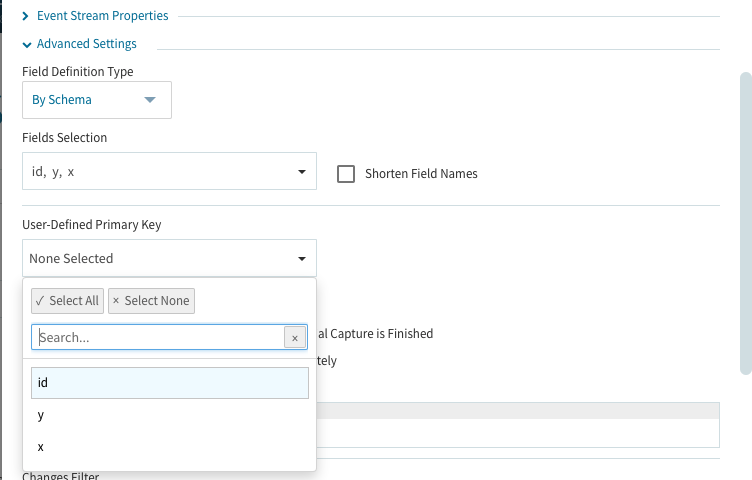
最後にAdvanced Settingsの中にあるUser-Defined Primary Keyを設定(今回はidを選択)しておきます。
此処までの作業で、kafkaとEqualumの接続設定は終了になります。
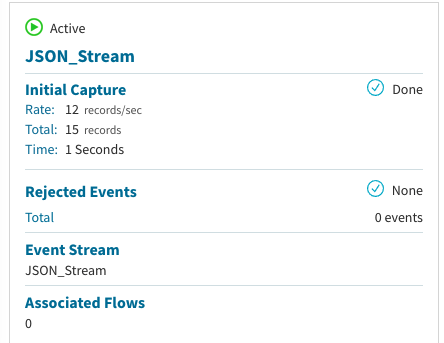
設定後にすぐに初期抽出の処理が行われ、下流側の設定が済み次第処理が実行されます(デフォルトでは、初期抽出がONになっています)。またこの処理準備により、実際のFLOWデザインの際に実際のデータをシュミレートした作業が出来る様になりますので、途中に組み込む処理によっては、設定した処理の結果が即確認出来る等の便利機能になっています。
(5)FLOWの作成
次にFLOWの作成を行います。今回はデータ自体が超シンプルなので、間の処理は省略した形(ある意味レプリケーションになりますが)で検証を行います。Equalum的には、正常に接続されたデータは、FLOWの中においては全て操作対象になりますので、JSONの項目にルックアップ情報を埋め込み、それをFLOWの中で抽出・参照・置き換えといった作業等も他のデータソース同様に簡単に行えます。
ダッシュボードのFLOWS右側にある**+ADD**ボタンを選択します。

(5−1)FLOWデザイン上でマウスのダブルクリックを行い、上流側のデータソースを選択します。

(5−2)同様にFLOWデザイン上でマウスのダブルクリックを行い、下流側のデータソースを選択します。
(5−3)FLOWデザイン上で両者を関連付けます。
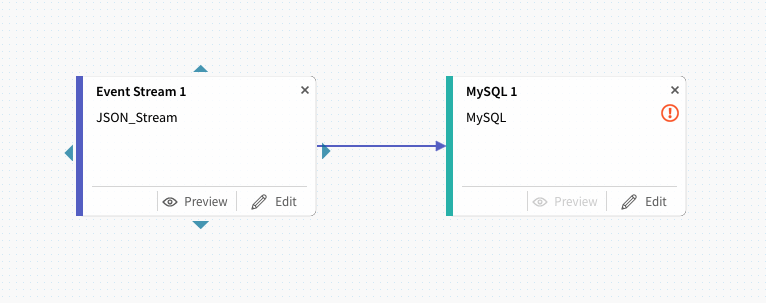
此処で、最初に動作確認で生成したJSONデータの状況を確認するには、上流側のPreviewを選択します。
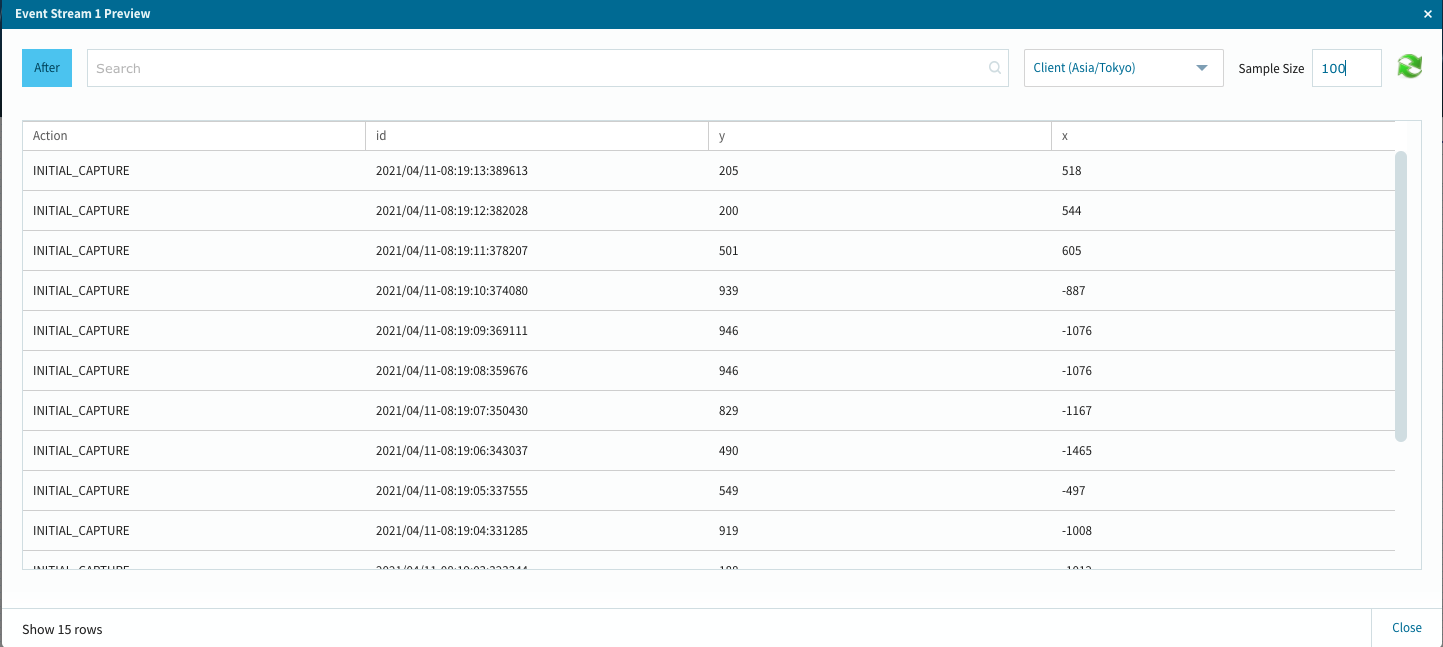
無事にカラム属性を含めて処理対象になっている事が確認出来ました。
(5−4)ターゲット側のマッピングを行います。
Equalumの柔軟性の一つに、この最終段でのカラム項目のマッピング機能が有ります。この段階で上流側から流れてくるデータを送らない設定も出来ますし、途中で派生させたカラムに対するデータ適用なども行えます(ルックアップ処理などで便利)。
Editボタンを選択して設定GUIを呼び出します。今回は必要項目だけを設定して検証作業を行います。
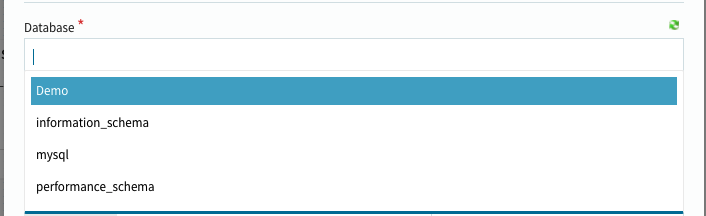
データベースとテーブルを選択します。
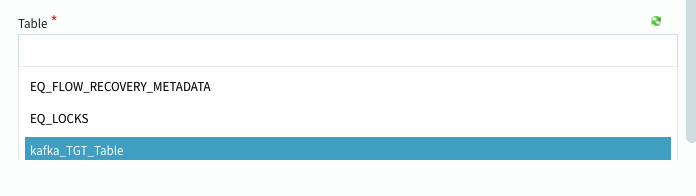
+MAPPINGボタンを選択します。
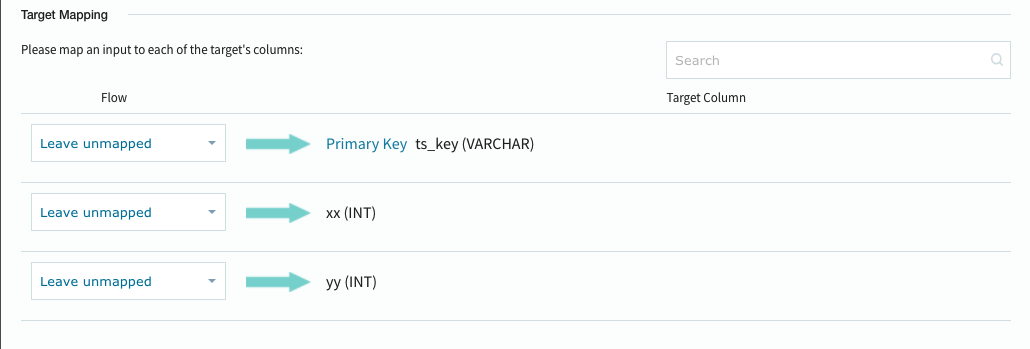
Target Mappingの部分を適切に選択・設定します。

問題がなければOKボタンを選択して設定を終了します。
この状況まで来れば、あとは以前の検証で行った作業と同じですので、FLOWをセーブして配備・実行するだけです。
これで準備が整いました。
では検証開始!
今回の検証は、画面上のマウス座標をPythonで抽出し、シンプルで小規模のJSON形式でプロデューサに送出する形で行った関係上、利き腕の労力が半端ない状況でしたので、あまり長時間のデータ生成は出来ませんでした。。。(汗)
以下は、検証作業時のEqualumダッシュボードの状況になります。
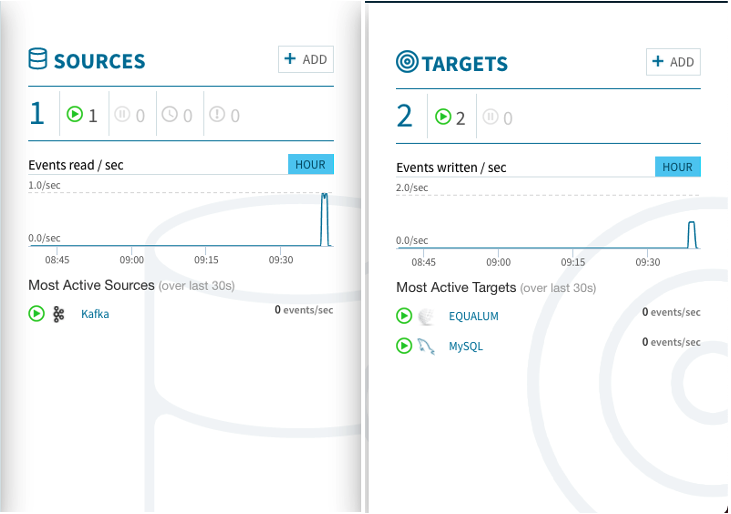
以下は、今回の検証結果データになります(左側はMySQLに格納されたデータ、右側がkafkaのプロデューサへの送出データになります)
2021/04/11-09:37:58:330350| 527|223| {'id': '2021/04/11-09:37:58:330350', 'x': 527, 'y': 223}
2021/04/11-09:37:59:335195| -993| 62| {'id': '2021/04/11-09:37:59:335195', 'x': -993, 'y': 62}
2021/04/11-09:38:00:341232| 1059| 0| {'id': '2021/04/11-09:38:00:341232', 'x': 1059, 'y': 0}
2021/04/11-09:38:01:347066| 1350| 69| {'id': '2021/04/11-09:38:01:347066', 'x': 1350, 'y': 69}
/////// 途中省略 //////
2021/04/11-09:38:11:412048| -911|229| {'id': '2021/04/11-09:38:11:412048', 'x': -911, 'y': 229}
2021/04/11-09:38:12:419794| -509|212| {'id': '2021/04/11-09:38:12:419794', 'x': -509, 'y': 212}
2021/04/11-09:38:13:425034| -272|246| {'id': '2021/04/11-09:38:13:425034', 'x': -272, 'y': 246}
2021/04/11-09:38:14:429277| -586|248| {'id': '2021/04/11-09:38:14:429277', 'x': -586, 'y': 248}
/////// 途中省略 //////
2021/04/11-09:38:30:523297|-1037|482| {'id': '2021/04/11-09:38:30:523297', 'x': -1037, 'y': 482}
2021/04/11-09:38:31:528702| -333|641| {'id': '2021/04/11-09:38:31:528702', 'x': -333, 'y': 641}
2021/04/11-09:38:32:535799|-1228|316| {'id': '2021/04/11-09:38:32:535799', 'x': -1228, 'y': 316}
2021/04/11-09:38:33:544202|-1110|690| {'id': '2021/04/11-09:38:33:544202', 'x': -1110, 'y': 690}
2021/04/11-09:38:34:550620| -990|197| {'id': '2021/04/11-09:38:34:550620', 'x': -990, 'y': 197}
/////// 途中省略 //////
2021/04/11-09:38:51:646299| -823|456| {'id': '2021/04/11-09:38:51:646299', 'x': -823, 'y': 456}
2021/04/11-09:38:52:655003|-1196|438| {'id': '2021/04/11-09:38:52:655003', 'x': -1196, 'y': 438}
2021/04/11-09:38:53:662194| -624|305| {'id': '2021/04/11-09:38:53:662194', 'x': -624, 'y': 305}
2021/04/11-09:38:54:668645| -242|568| {'id': '2021/04/11-09:38:54:668645', 'x': -242, 'y': 568}
2021/04/11-09:38:55:674050| -328|163| {'id': '2021/04/11-09:38:55:674050', 'x': -328, 'y': 163}
2021/04/11-09:38:56:678265|-1332|646| {'id': '2021/04/11-09:38:56:678265', 'x': -1332, 'y': 646}
/////// 途中省略 //////
2021/04/11-09:39:14:792023| 935| 55| {'id': '2021/04/11-09:39:14:792023', 'x': 935, 'y': 55}
2021/04/11-09:39:15:794852| 1116| 49| {'id': '2021/04/11-09:39:15:794852', 'x': 1116, 'y': 49}
2021/04/11-09:39:16:798872| 557|121| {'id': '2021/04/11-09:39:16:798872', 'x': 557, 'y': 121}
2021/04/11-09:39:17:804355| 637|199| {'id': '2021/04/11-09:39:17:804355', 'x': 637, 'y': 199}
無事にストリーミング出来た様です。
今回のまとめ
今回は、前回に引き続きEqualumのストリーミング検証として、データソースにkafkaを使った場合の検証作業を行いました。Equalumは、仕組みの総力戦で効率的且つ即時的な**「Exactly Once」を実現し、CDCストリーミング対象のリレーショナル・データベース系に加えて、今回検証したkafkaにもこの機能を適用させています。これは、昨今のIoT系データ処理**の仕組みを構築する際に、周辺の既存業務系やエッジ展開しているデータベース群等とも、極めて有機的で能動的なデータ連携の可能性を提供出来る事を示しています。
もちろん、データは企業・団体活動の重要なエビデンスであり、その量・質を高める作業こそが日常の業務・課題であると言えるでしょう。そしてそれらを強固に守るという事も重要なITの役割だと言えますが、変化の激しい・不確定性の高い現代社会において、常時接続時代、5Gを始めとする低遅延・高速な次世代通信、全てがネットに繋がるコネクテッドXの流れが、それらのより良いデータを創る重要な資源として、多様なデータの利活用戦略や具体的な方法論・実装を要求してきています。
その新たなデータ・セントリックな時代における、データ・オプス(DataOps)の核として、Equalumは色々なシチュエーションの中で、確実に前に進めるソリューションなのかもしれません。
データの質や量・扱う時間に関係なく
情け容赦の無い、創造的で革新的なデータ利活用し
データを再生可能エネルギー(資源)として、より良い結果(データ)の創造を行う
それらを支えるデータ流通革命の一端を、Equalumは十分に担えると一連の検証を通じて感じました。
最近、国内でも正式に2社の外販代理店が立ち上がるという話も聞こえておりますので、また別の機会に**「小ネタ的な」**検証を行って皆様と共有させて頂きたいと考えております。
謝辞
本検証は、Equalum社の最新公式バージョン(V2.24)を利用して実施しています。この貴重な機会を提供して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。