■はじめに
データ分析とデータ品質改善に従事してきた筆者が、SQLを用いた分析の基本である「ウィンドウ関数」の使い方をまとめてみようと思います。
こちらの記事は前回投稿した「そろそろSQLのウィンドウ関数を理解したい - 連載1/3話」、「そろそろSQLのウィンドウ関数を理解したい - 連載2/3話」の続きとなっております。連載1話ではウィンドウ関数の基礎と動作イメージを、連載2話ではpartition byやorder byによる集計範囲と処理順の説明が書いてありますので、もし未読でしたらそちらも見ていただけると幸いです。
今回は、様々なウィンドウ関数を使ったときの挙動を詳しく解説していきます。
■環境
本記事の内容は、下記RDBMSで動作確認しています。記事中の実行結果画面などの図はPostgreSQLの結果を使います。
- PostgreSQL 11.5
- Oracle xe 18.4
- SQL Server 2017 Express
- MySQL 8.0.17
※MySQLは2018年4月リリースの8.0からウィンドウ関数が搭載されました。つい最近の出来事なので、8.0より前のバージョンを使用しているシステムがまだ多いので使えるか要確認。
■前回と前々回の記事の簡単な振り返り
- ウィンドウ関数とは「他のレコードの情報」を使って値を求めることができる関数
- ウィンドウ関数は大きく以下の二種類ある
- sumやcountといった見慣れた集計関数をウィンドウ関数として利用するもの
- 分析専用のウィンドウ関数を利用するもの
- ウィンドウ関数は sum(売上金額) over() という構文で記述することができる
- over()の中に partition by <列名> と書いて集約範囲を指定することができる
- over()の中に order by <列名> と書いてレコード並び順を意識した累積和の計算や連番付与ができる
- over()の中の order by <列名> の後に rows between <開始行> and <終了行> と書いてウィンドウ範囲を細かく指定できる。
■よく使うウィンドウ関数の一覧(再掲)
この一覧は今回検証のために利用した4つのRDBMSに共通して搭載されています。
| 関数名 | 説明 |
|---|---|
| AVG | 全体の平均、グループごとの平均、累積平均を求める |
| COUNT | 全体の件数、グループごとの件数、累積件数を求める |
| MAX | 全体の最大、グループごとの最大を求める |
| MIN | 全体の最小、グループごとの最小を求める |
| SUM | 全体の合計、グループごとの合計、累積合計を求める |
| ROW_NUMBER | ソートして順位付けする(同じ値の場合も重複なし)1,2,3,4,5 |
| RANK | ソートして順位付けする(同じ値の場合に重複あり、値は重複分飛ぶ)1,2,2,4,5 |
| DENSE_RANK | ソートして順位付けする(同じ値の場合に重複あり、値は飛ばない)1,2,2,3,4 |
| NTILE | レコードを等分割した値を付与する |
| FIRST_VALUE | 最初の行の値を利用できる |
| LAST_VALUE | 最後の行の値を利用できる |
| LAG | 前の行の値を利用できる |
| LEAD | 次の行の値を利用できる |
上記の関数一覧にてpartition byとorder byを指定した時の動きを説明します。表に書いてある説明で結果のイメージが大体理解できているかもしれませんが、結構使いどころありそう!と感じていただけるかと思います。
以下のデータを使ってそれぞれの動きを見ていきます。
select 部門, 売上金額, 売上日 from 売上テーブル;
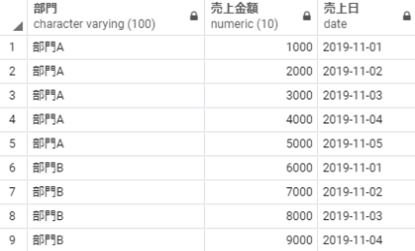
sum:合計値を算出する
sum over partition 部門
以下のSQLを実行することで、部門ごとの売上金額の合計を算出することができます。
select 部門,
売上金額,
sum(売上金額) over(partition by 部門) as 部門ごとの売上金額合計
from 売上テーブル;
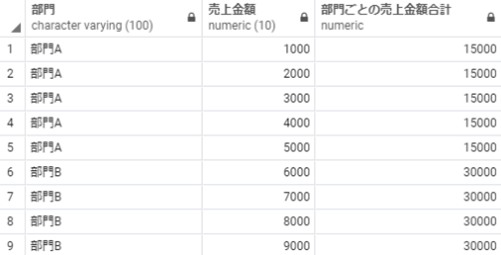
sum over partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとにその売上日時点の売上金額の合計を算出することができます。
select 部門,
売上金額,
売上日,
sum(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの売上金額合計推移
from 売上テーブル;
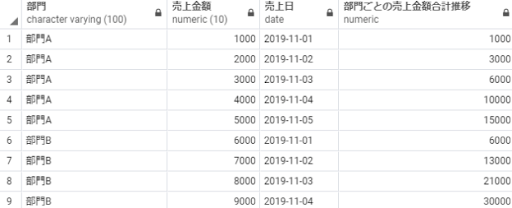
※補足:最初の行から現在の行までを対象に部門別で売上を合計した結果が「部門ごとの売上金額合計推移」に算出されています。
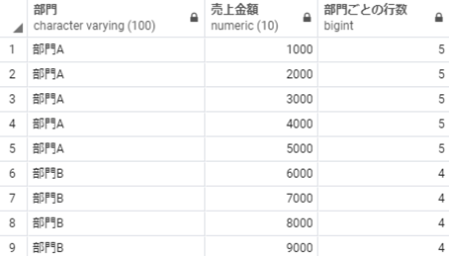
count:件数を算出する
count over partition 部門
以下のSQLを実行することで、部門ごとのレコード数を算出することができます。
select 部門,
売上金額,
count(売上金額) over(partition by 部門) as 部門ごとの行数
from 売上テーブル;
count over partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとにその売上日時点のレコード数を算出することができます。
select 部門,
売上金額,
売上日,
count(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの行数推移
from 売上テーブル;
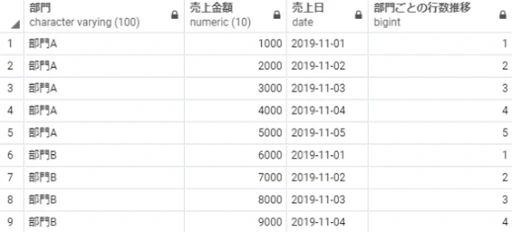
※補足:最初の行から現在の行までを対象に部門別で件数を数えた結果が「部門ごとの行数推移」に算出されています。
max:最大値を算出する
max over partition 部門
以下のSQLを実行することで、部門ごとの最大の売上金額を算出することができます。
select 部門,
売上金額,
max(売上金額) over(partition by 部門) as 部門ごとの最大金額
from 売上テーブル;
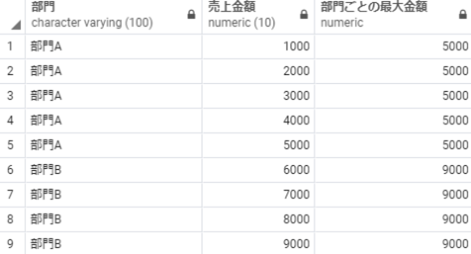
max over partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとにその売上日時点の最大の売上金額を算出することができます。
select 部門,
売上金額,
売上日,
max(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの最大金額推移
from 売上テーブル;
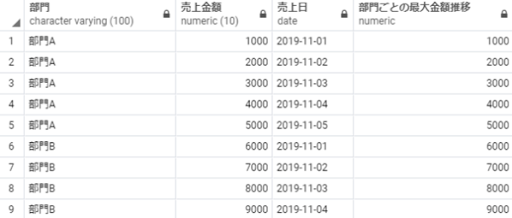
※補足:最初の行から現在の行までを対象に部門別の最大値が「部門ごとの最大金額推移」に算出されています。売上日が古い順にレコードの売上金額も上がっているため、上記のような1件ごとに最大金額が変化する動きになっています。もし部門Aの2019-11-02の売上が20000だった場合、部門Aの最大金額推移は「1000, 20000, 20000, 20000, 20000」という結果になります。
min:最小値を算出する
min over partition 部門
以下のSQLを実行することで、部門ごとの最小の売上金額を算出することができます。
select 部門,
売上金額,
min(売上金額) over(partition by 部門) as 部門ごとの最小金額
from 売上テーブル;
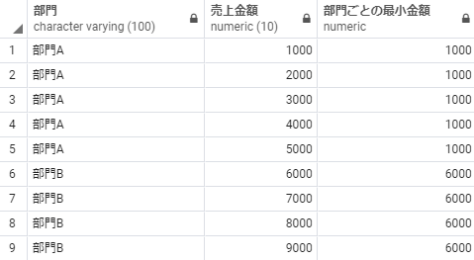
min over partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとにその売上日時点の最小の売上金額を算出することができます。
select 部門,
売上金額,
売上日,
min(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの最小金額推移
from 売上テーブル;
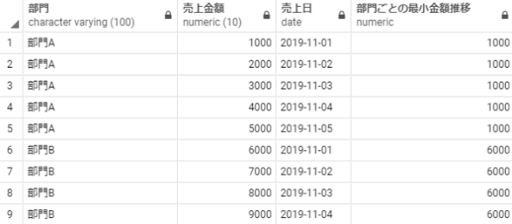
※補足:最初の行から現在の行までを対象に部門別の最小値が「部門ごとの最小金額推移」に算出されています。売上日が一番古いレコードの売上金額が最小のため、上記のような最小金額が変わらない動きになっています。もし部門Aの2019-11-03の売上が500だった場合、部門Aの最小金額推移は「1000, 1000, 500, 500, 500」という結果になります。
avg:平均値を算出する
avg over partition 部門
以下のSQLを実行することで、部門ごとの売上金額の平均を算出することができます。
select 部門,
売上金額,
avg(売上金額) over(partition by 部門) as 部門ごとの売上金額平均
from 売上テーブル;
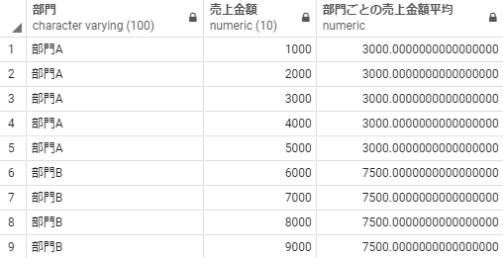
avg over partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとにその売上日時点の売上金額の平均を算出することができます。
select 部門,
売上金額,
売上日,
avg(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの売上金額平均推移
from 売上テーブル;
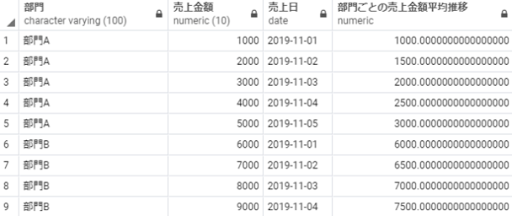
※補足:最初の行から現在の行までを対象に売上金額の平均値を算出した結果が「部門ごとの売上金額平均推移」に算出されています。
row_number:順位づけをする(順位は重複しない)
row_number order by 売上日
以下のSQLを実行することで、売上日の古い順番で連番を算出することができます。
select 部門,
売上金額,
売上日,
row_number() over(order by 売上日) as 売上日昇順の行番号
from 売上テーブル;
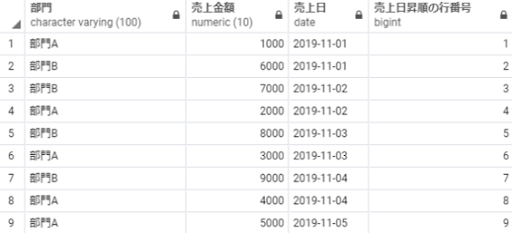
※補足:通常のorder byと同じく、並び替え対象の列に同じ値(2019-11-01)があるとき、取得される順番は保証されていないため実行のたびに異なる可能性があります。そのため、上記結果のように、部門A,B,B,Aのように取れることもあれば、部門B,A,A,Bと取れることもあります。実行するたびに実行結果が変わってしまうのを避けるためには、通常のorder byと同様に第二ソートキー・第三ソートキーを設定することで実行結果を安定させることができます。
row_number order by 売上日, 部門
以下のSQLを実行することで、売上日の古い順番かつ重複した売上日の場合は部門の名称順で連番を算出することができます。
select 部門,
売上金額,
売上日,
row_number() over(order by 売上日, 部門) as 売上日昇順の行番号
from 売上テーブル;
※補足:第一ソートキーに売上日、第二ソートキーに部門を設定しています。売上日が一緒の場合は部門の昇順で扱う設定のため、同一売上日内で部門A,B,A,Bと行番号付与ができています。
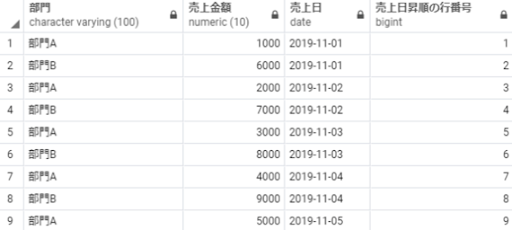
row_number partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとに売上日の古い順番で連番を算出することができます。
select 部門,
売上金額,
売上日,
row_number() over(partition by 部門 order by 売上日) as 部門ごとの売上日昇順の行番号
from 売上テーブル;
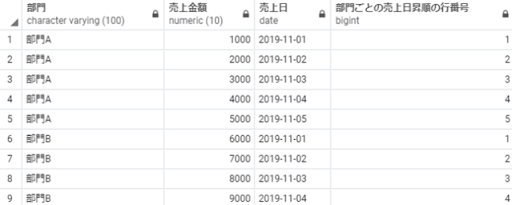
rank:順位づけをする(順位は重複して、重複分は順位を飛ばす)
rank order by 売上日
以下のSQLを実行することで、売上日の古い順番で順位を算出することができます。
select 部門,
売上金額,
売上日,
rank() over(order by 売上日) as 売上日昇順の重複飛び番号
from 売上テーブル;
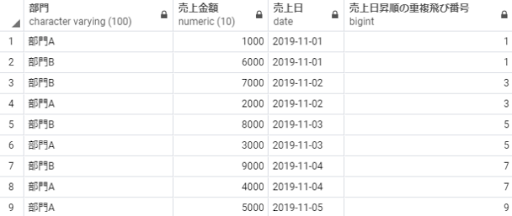
※補足:重複があると、その分ランキングが飛ぶため、2位を表す2という値が出てきません。もし1位のデータが3つあったら2, 3が飛ばされ1, 1, 1, 4 という結果を得られます。
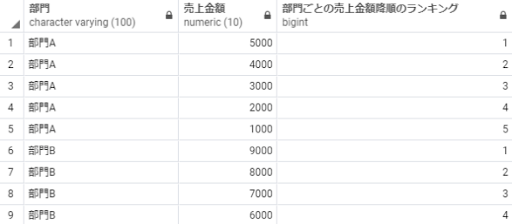
rank partition 部門 order by 売上金額 desc
以下のSQLを実行することで、部門ごとに売上金額の多い順番で順位を算出することができます。
select 部門,
売上金額,
rank() over(partition by 部門 order by 売上金額 desc) as 部門ごとの売上金額降順のランキング
from 売上テーブル;
dense_rank:順位づけをする(順位は重複して、重複分は順位を飛ばさない)
dense_rank order by 売上日 desc
以下のSQLを実行することで、売上日の古い順番で順位を算出することができます。
select 部門,
売上金額,
売上日,
dense_rank() over(order by 売上日) as 売上日昇順の重複飛ばず番号
from 売上テーブル;
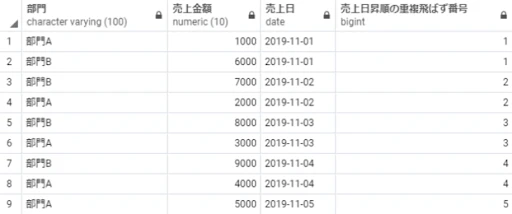
※補足:重複があってもその分ランキングが飛ばないため、抜け番は発生しません。もし1位のデータが3つあったら1, 1, 1, 2 という結果を得られます。
dense_rank partition 部門 order by 売上金額 desc
以下のSQLを実行することで、部門ごとに売上金額の多い順番で順位を算出することができます。
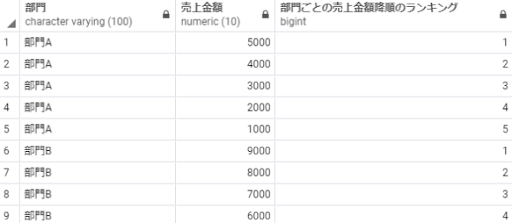
select 部門,
売上金額,
dense_rank() over(partition by 部門 order by 売上金額 desc) as 部門ごとの売上金額降順のランキング
from 売上テーブル;
ntile:データを等分割して順位をつける
ntile 3分割 order by 売上日
以下のSQLを実行することで、売上日の古い順番で全体を3分割した結果を算出することができます。
select 部門,
売上金額,
売上日,
ntile(3) over(order by 売上日) as 売上日昇順で3分割
from 売上テーブル;
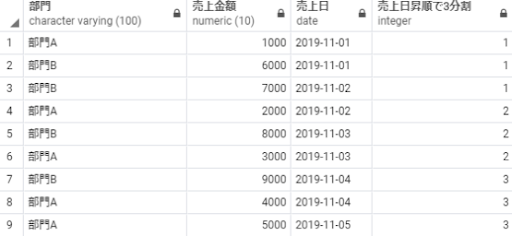
※補足:ntileというウィンドウ関数は、データを等分割してランク付けすることができます。分析手法のひとつである「デシル分析」という、レコードを10等分にしてそのうちの上位10%(1が付与されたレコード)や下位20%のレコード(9, 10が付与されたレコード)をまとまりとして売上割合などを確認する場合などによく使います。
ntile 4分割 partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとに売上日の古い順番で全体を4分割した結果を算出することができます。
select 部門,
売上金額,
売上日,
ntile(4) over(partition by 部門 order by 売上日) as 部門ごとの売上日昇順で4分割
from 売上テーブル;
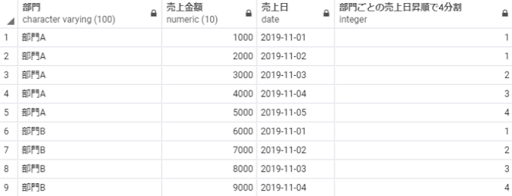
※補足:分割する際、割り切れない場合は上位の順番からひとつずつ増分されます。例えば6件のデータを4分割したら1, 1, 2, 2, 3, 4となります。
first_value:最初の値を利用する
first_value partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとに売上日の最も古いレコードの売上金額を算出することができます。
select 部門,
売上金額,
売上日,
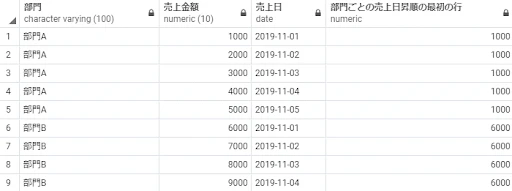
first_value(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの売上日昇順の最初の行
from 売上テーブル;
last_value:最後の値を利用する
last_value partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとに売上日の最も新しいレコードの売上金額を算出することができま、、、せん。結果と補足を見てみましょう。
select 部門,
売上金額,
売上日,
last_value(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの売上日昇順の最後の行
from 売上テーブル;
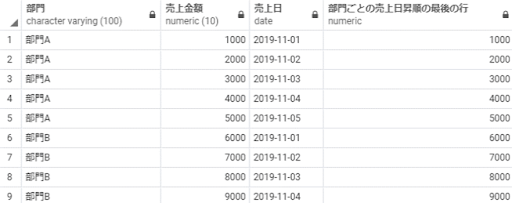
※補足:最初の行から現在の行までを対象にlast_value(最後の行)の結果が「部門ごとの売上日昇順の最後の行」に算出されています。そのため全てのレコードにて、現在の行がウィンドウ範囲の中で最後の行となるので上記のような動きになっています。last_valueを本来の利用イメージ通り日付順に並べた時の最後の行として扱いたい場合は、rows between を指定してウィンドウ範囲を適切に設定する必要があります。
last_value partition 部門 order by 売上日 rows between指定
以下のSQLを実行することで、部門ごとに売上日の最も新しいレコードの売上金額を算出することができます。
select 部門,
売上金額,
売上日,
last_value(売上金額) over(partition by 部門 order by 売上日
rows between unbounded preceding and unbounded following) as 部門ごとの売上日昇順の最後の行
from 売上テーブル;
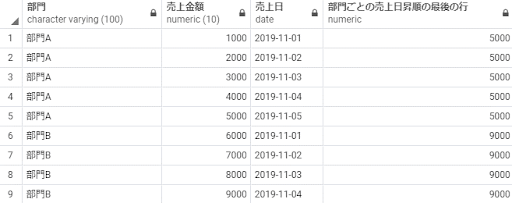
※補足:rows between の指定により、部門ごとの全レコードをウィンドウ範囲として、その中の最終行の売上金額を取得するようにしたため、イメージ通りの結果とすることができました。rows between の詳細は前回の「そろそろSQLのウィンドウ関数を理解したい - 連載2/3話」の記事にて説明しています。
lag:前の行の値を利用できる
lag partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとに売上日の古い順番で並べた時の一つ前のレコードの売上金額を算出することができます。
select 部門,
売上金額,
売上日,
lag(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの売上日昇順の一つ前の行
from 売上テーブル;
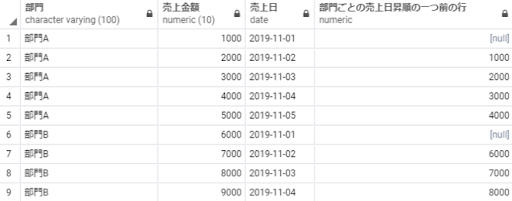
※補足:最初の行は前の行がないためNULLとなります。
lead:次の行の値を利用できる
lead partition 部門 order by 売上日
以下のSQLを実行することで、部門ごとに売上日の古い順番で並べた時の一つ次のレコードの売上金額を算出することができます。
select 部門,
売上金額,
売上日,
lead(売上金額) over(partition by 部門 order by 売上日) as 部門ごとの売上日昇順の一つ後の行
from 売上テーブル;
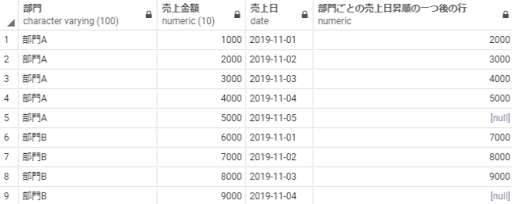
※補足:最後の行は次の行がないためNULLとなります。
■まとめ
ウィンドウ関数の種類によって、イメージしていた通りの結果を出してくれるものと、イメージとは違う結果が混在していたと思います。これらは、可能な限り補足に記載していましたが、ウィンドウの範囲が適切でないため起こっているものがほとんどです。ウィンドウの範囲や関数の仕組みが理解できてくると、想定通りの結果を算出することができるようになります。
最後にウィンドウ関数の利用における注意点と便利な表記をそれぞれ1つずつ紹介します。
■ウィンドウ関数の結果をwhere句で使う際の注意点
例えば次のウィンドウ関数を利用した際に、where句で抽出条件を書こうとするとエラーとなります。
where句を利用しない場合の結果は次の通りです。
select 部門,
売上金額,
売上日,
ntile(3) over(order by 売上日) as 売上日昇順で3分割
from 売上テーブル;
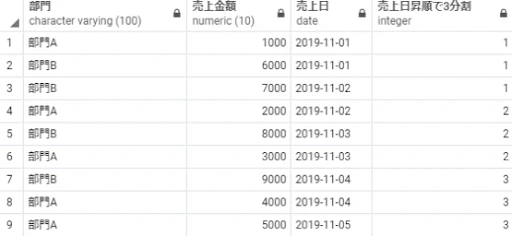
一方、where句で抽出条件を書くと以下のようなエラーが起きます。
select 部門,
売上金額,
売上日,
ntile(3) over(order by 売上日) as 売上日昇順で3分割
from 売上テーブル
where 売上日昇順で3分割 = 1;
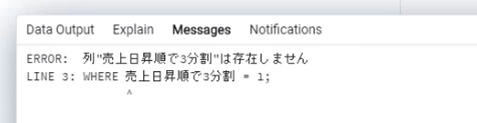
エラーとなる原因ですが、where句が先に実行されて、ウィンドウ関数の処理が後から実行されてしまうからです。ウィンドウ関数の結果をwhere句で絞り込みたいときは、全体をサブクエリ化することで簡単に回避することができます。
SQLの階層が1つ深くなってしまいますが、ウィンドウ関数を使うときは全体をサブクエリとすることでwhere句の絞り込みができる、といった理解でよいと思います。
select *
from (
select 部門,
売上金額,
売上日,
ntile(3) over(order by 売上日) as 売上日昇順で3分割
from 売上テーブル
) as tmp
where 売上日昇順で3分割 = 1;

■window句を用いた集計設定の再利用
※こちらの記述はPostgreSQL, MySQLでは使用できましたが、SQL Server, Oracleでは使用できませんので参考情報として。
select 部門,
売上金額,
売上日,
count(売上金額) over win1,
sum(売上金額) over win1,
avg(売上金額) over win1
from 売上テーブル
window win1 as (partition by 部門 order by 売上日);
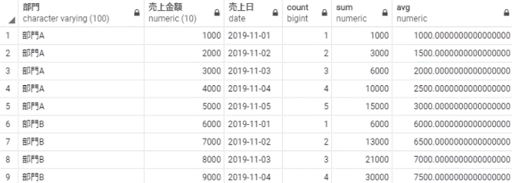
このように書くことでselect句の記述をスッキリさせたり、window句を変えるだけでselect句のウィンドウ範囲をまとめて変更できるので便利です。
■最後に
今回はよく使うウィンドウ関数の使い方と結果を一覧でまとめてみました。繰り返しとなりますが、ウィンドウ関数を利用すると他の行のデータを扱った処理ができるため、この仕組みを知る前と知った後では出来る事の幅が広がったと思います。
本連載はこちらの記事で最終回となりますが、この記事を通じてSQLとウィンドウ関数に興味を持った人が増え、様々な場面で活用していただければ幸いです。この連載に書ききれなかった「実務で役立つ分析手法」や「データ品質調査手法」や「データ管理手法」など周りからの反響や反応によって、また投稿するかもしれません。
それでは機会があればまたお会いしましょう!
最後まで見ていただきありがとうございました。