MySQLで軽く分析できる人が、BigQueryに慣れるための最短・最速手順
これは何?
MySQLのSQLクエリ書いて軽い分析をやってた人がGoogle BigQuery(以後BQ)でも軽い分析ができるようになるための基礎知識をまとめました。業務で使う際に最低限必要な内容プラスアルファくらいの内容です。
これまでAWSのRDS(Read Onlyの分析用途)をRedash経由で叩いていましたが、BQでデータウェアハウス(以後DWH)を構築し始めたためBQを学ぶ必要が出てきました。
MySQLのクエリをBQに一部移行したりして、何となくBQが分かってきたので、基礎的な内容と躓きやすいポイントをまとめます。が、本当に触り始めたばかりなので、理解が間違っているところもあるかもしれません...
なお。redash経由でBQを叩く際の方法は記載していませんが、本記事の内容さえ頭に入れれば、問題なく使えます。
前提知識
- MySQLでクエリをある程度書ける方
参考図書
学ぶにあたり、以下の書籍を一部参考にしています。
集中演習 SQL入門 Google BigQueryではじめるビジネスデータ分析
BQでは、BQ独自の機能もたくさんありますが、利用用途などが書いてありまして、分かりやすかったです。BQで初めてSQLに触れる方から中〜上級者まで参考になるかと思います。
また、その他、色々なWebページを参考にさせてもらいましたが、それは記事内で紹介します。
Google BigQueryの概要と基礎知識を身に付ける
Google BigQueryとは
Google Cloudのサービスの1つで、ドデカいデータを超高速で解析することができるサービスです。
MySQLやPostgreSQL等のRDBに対して、くっそ重いクエリを投げて「またタイムアウトやん...」みたいなデータでも、数秒や数十秒で処理できる場合もあります。ただ、処理が早いデータは分散処理で対処しやすいものだけで、BQでも数時間かかるような場合もあります。
BQのイケてるところ(RDB比較)
BQは知れば知るほど、すげーサービスだ...と感動しているのですが、今だと以下が超絶便利なところだと感じています。
これまで、「BQにデータがあるとめっちゃ速く分析できるんでしょ?」くらいしか思っていませんでしたが、過去の自分をハリセンで叩きたいくらい便利。
とにかく速い
DBのサーバースケールアップしてよー!とか言ってたのがバカバカしくなるくらい速いです。
ただ、無尽蔵に速くなるわけではありません。
BQスロット(仮想CPU)という概念があり、使えるスロットを越えるような使い方をすると処理速度も低下します。
詳細は、スロットについてをご覧ください。
便利な関数や句がめっちゃ多い
- まだ触りだけしかやっていませんが、MySQLではできなかった分析がBQならできる!みたいなことが非常に多いです。
スプシやデータポータルとの連携
- 他のグーグルサービスとの連携がかなりイケてます。
- データポータルにエクスポートしたり、スプレッドシートと同期させることもできます。
- 特にスプレッドシートで色々なことをやろうとするとスプレッドシートが重すぎて動かないこともあったと思いますが、BQ側に計算を寄せればスプシをと軽くなりそうな予感
他のサービスとの連携
- BQとデータ連携できるサービスがとにかく豊富!自社で何かサービスを導入する際に他のサービスのデータをBQに入れたり、自社のBQのデータを他のサービスに連携させたりできます。
MySQLマンが覚えないといけないこと
MySQLマンが苦戦しそうなところも先に挙げときます。
ただ、これは覚えればいいだけなので、知っていれば問題なしです。
- From句の表現方法の違い
- データ型
- where句で、0と1(BOOLEAN)カラムに対して絞り込みするときは、true/falseで表現
- 料金体系を覚えないと大変なことになる
- データ容量を意識したクエリを書かないといけない
- asで日本語が使えずちょい不便
RDBとの違い、料金体系
BQは、RDBとは構造が異なっています。
また、BQの料金は、ストレージの料金とクエリの処理に必要なデータ量によって料金が発生します。
クエリを実行した結果が少ない場合でも、その対象のデータが多ければ料金が膨らみます。
上記については、
BigQuery とは 概要から料金体系を5分で入門
に端的にまとまっていましたので、一度ご覧ください。
Google BigQueryでSelect文を実行する
さて、それではまずはGoogle BigQueryでSelect文を実行する方法を紹介します。
最初から色々伝えると頭がパンクすると思うので、まずはSelect文を実行するための必要なことのみ説明していきます。
ログイン
まずは、ログイン!以下URLからログインします。
https://console.cloud.google.com/bigquery
BQの画面構成と管理構造
画面構成
ログインした後の画面構成は以下の図の通りです。
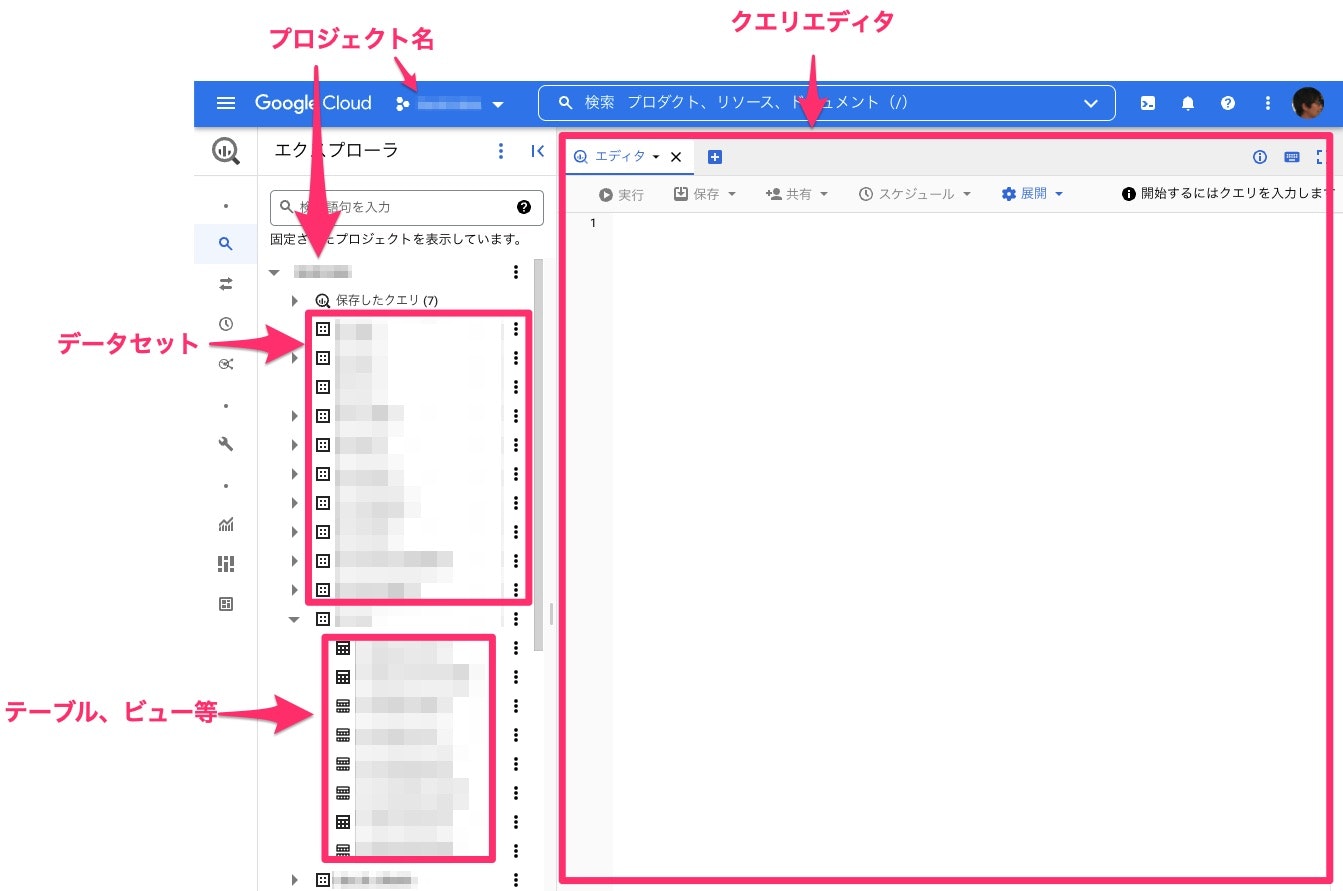
プロジェクトやデータセットという言葉は、初見かと思います。
BQは、以下のような階層構造(一部端折って記載)で管理されており、そのため、上記画面でもツリー構造になっています。
プロジェクト名を切り替えると、データセットの一覧もその対象プロジェクトの内容に切り替わります。
アカウント
Lプロジェクト
Lデータセット
Lテーブル、ビュー...
Lデータセット
Lテーブル、ビュー...
Lプロジェクト
Lデータセット
Lテーブル、ビュー...
Lデータセット
Lテーブル、ビュー...
管理構造の詳細とプロジェクト/データセットとは?
ここでプロジェクトとデータセットについて説明します。
RDBのみに触れていると、、
- データベースの中にテーブルがあるから、プロジェクトの存在意義とは何?
- データセットとテーブルだけでの構造で十分では?
と考える方もいそうです。
MySQL(RDB)ではサーバー>データベース>テーブルという構造があるのに対し、
BigQueryではプロジェクト>データセット>テーブルという構造になっていると思ってもらうとスッキリするかと思います。
今回は、BQに限って説明しているため、プロジェクトはBQだけの概念のように思えます。
しかし、プロジェクトはBigQueryだけのものではなく、Google Cloud Platform全体(他のあらゆるインフラ)で共有されています。
会社によっては、一つのGCPプロジェクトに社内の全てのインフラを詰め込んでいる会社、BQ専用にプロジェクトを作っている会社もあると思います。
プロジェクトという概念があることで、データの管理や権限の管理は、かなり便利で柔軟になります。
三階層でデータ等の管理ができて、かつ、それらに対してアクセスコントロールできることは、会社で使うためには必須と言えます。
プロジェクトとデータセットの使い方については、会社毎に運用形態を決めるのが良いでしょう。
詳細については、BigQuery 管理者リファレンス ガイド: リソース階層が参考になるので、一度みておきましょう。
なお、テーブルについては馴染みがあると思いますが、ビューについても初見かと思います。
ビューの説明は少し先にします。
SQL文の記述作法
SQL文の例
以下、BQでのSQLクエリの実行例です。
SELECT id as 'user_id', first_name, last_name
FROM `sample_project.sample_dataset.users`
WHERE first_name = "takeshu"
BQでは、FROM句の記法が『プロジェクト名.データセット名.テーブル/ビュー名』という形になります。
MySQLでもUSE構文を使うとこのようなピリオドで繋いだ記法になるときもありますが、BQでは上記が基本となります。
覚えておきたいSQLの関数・引数のルール
- カラム名やテーブル名の記述ルール
- テーブル名は大文字と小文字が厳密に区別される
- FROM句は、プロジェクト名、データセット名、テーブル名を「.」で繋いでいき、「`」で囲む
- ただ、特殊文字を使わない限り、「`」は常に省略可能です。「hoge-data」のようにハイフンが入っていたりするとプロジェクト指定の有無に関わらず囲わないと動かない
- ASに日本語は使えない
実際に実行する
実行方法と実行結果の確認
それでは、実際にクエリを実行していきましょう。
クエリの実行画面にクエリを書いて、実行していきます。流れは画像の通りです。
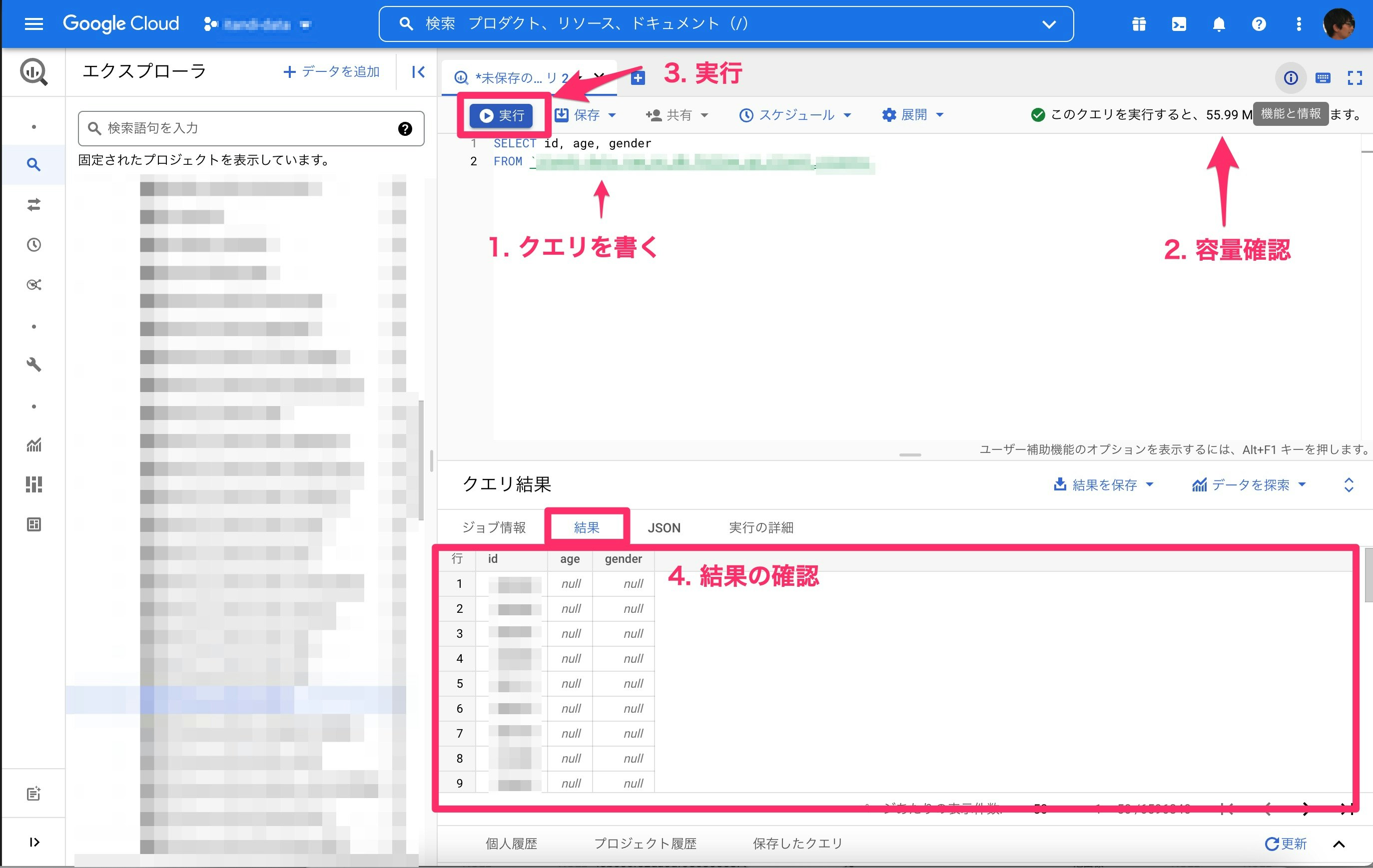
【重要】実行容量(料金)を減らす方法:selectではカラムを必ず指定
前述したとおり、クエリ実行時のデータの読み込み量に応じて、BQは課金されます。
なので、不必要なデータは処理させないということが重要です。
データ容量を減らすはいくつかあります。例えば、
- select句でカラムを指定
- そもそも対象となるデータを減らす
などがあります。(他にもあると思います。)
とりあえずデータがみたい...という時に『select *』とやってしまいがちですが、
BQではアスタリスクを使う際は注意が必要です。
レコード数600万、カラム数40くらいのテーブルに対してselect文を実行すると、下図のような差があります。
カラムは絞る!これだけまずは意識していきましょう。

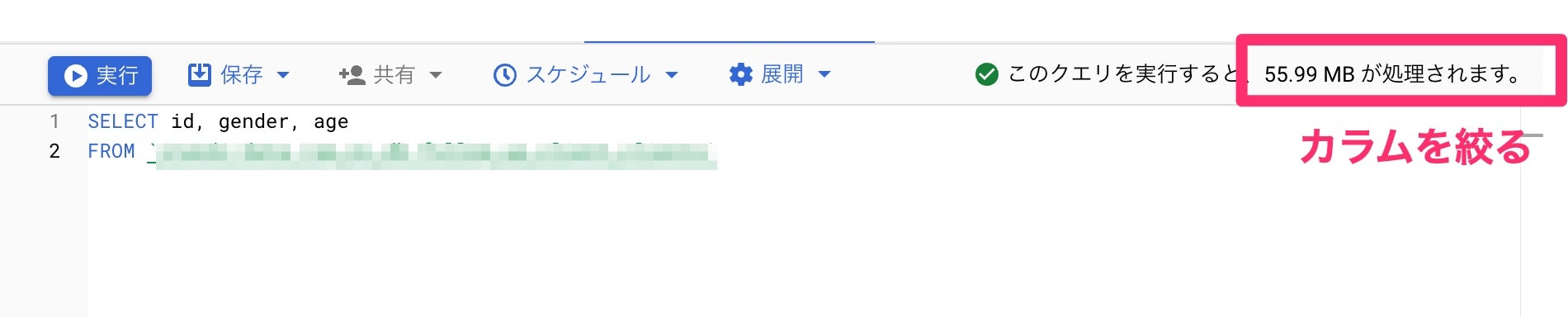
なお、limit等で表示数に制限を入れても、料金は変わりません。
理由としては処理するデータ量は変わらないためです。
このあたりは少しずつ慣れていくしかなさそうです。。
補足事項
BQの契約形態には、「オンデマンド料金」と「定額料金」があり、
データ容量を気にせずにする場合もありますので、自社の契約形態を確認しましょう。
詳細は、Reservations の概要をご覧下さい。
クエリ結果の保存
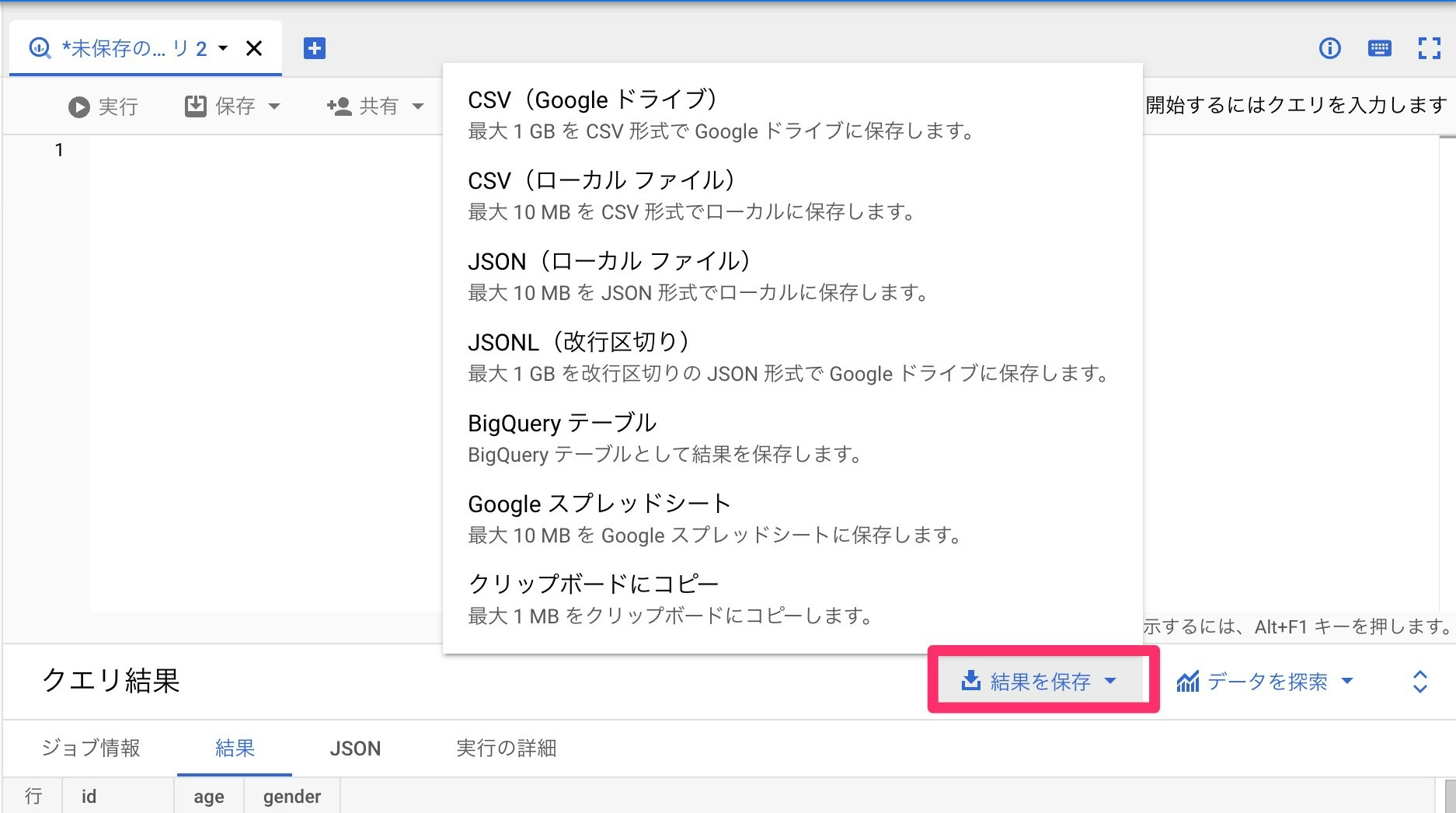
クエリの実行結果については、下図の画面から様々な方法でエクスポート可能です。
特にスプレッドシートに直接エクスポートできる点はかなり便利ですね。
実行履歴の確認とキャッシュ(一時テーブル)
BQでは、実行されたクエリ及び結果は、約24時間キャッシュされます。
実行されたクエリは、画面下部の履歴から確認できます。
個人履歴自分で実行した履歴、プロジェクト履歴はプロジェクト内で実行された履歴です。
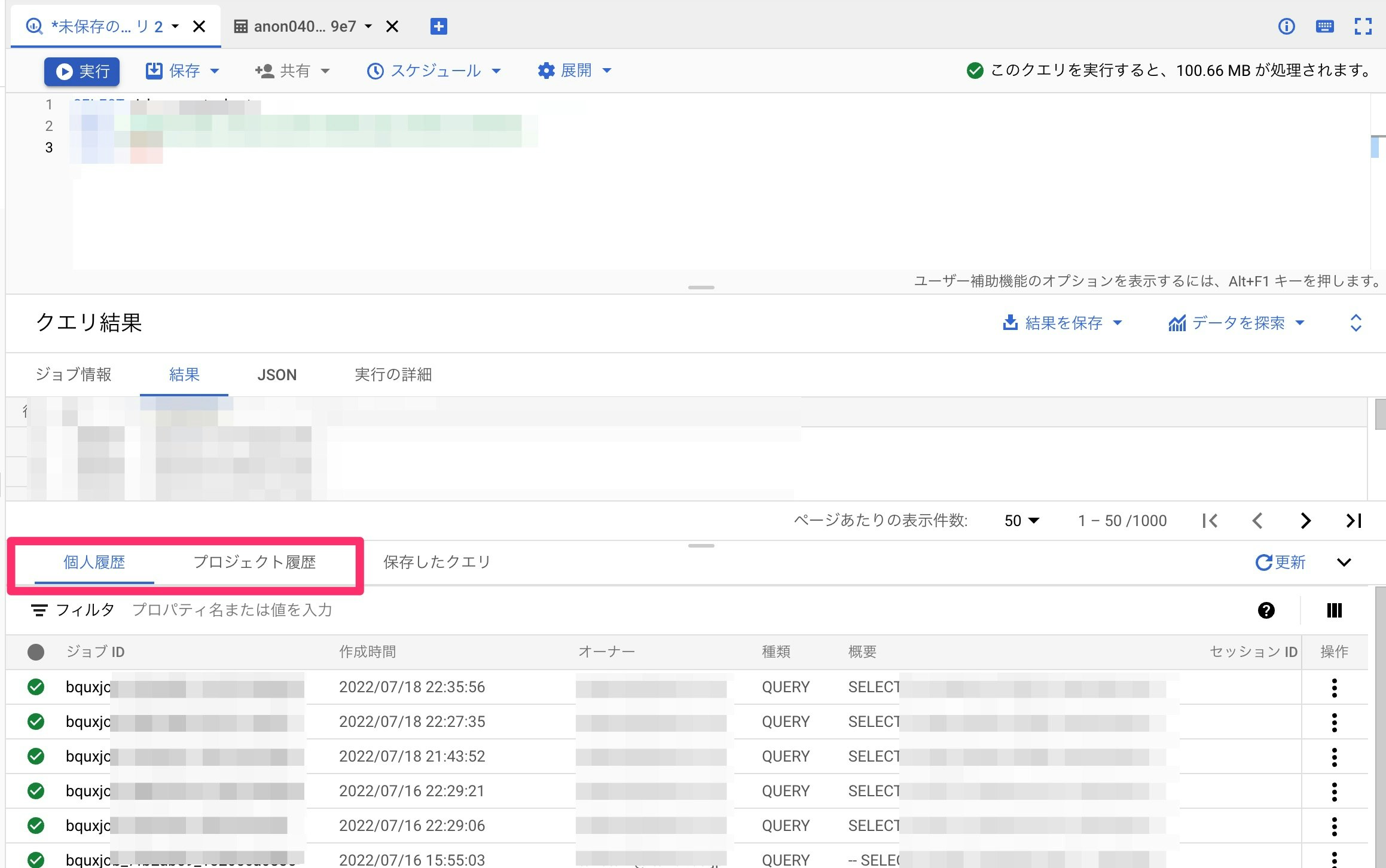
クエリが実行されるとジョブIDが割り振られ、その結果は、一時テーブルに自動的に保存されます。
履歴からジョブIDをクリックすると以下の画面が表示され、詳細を確認できます。
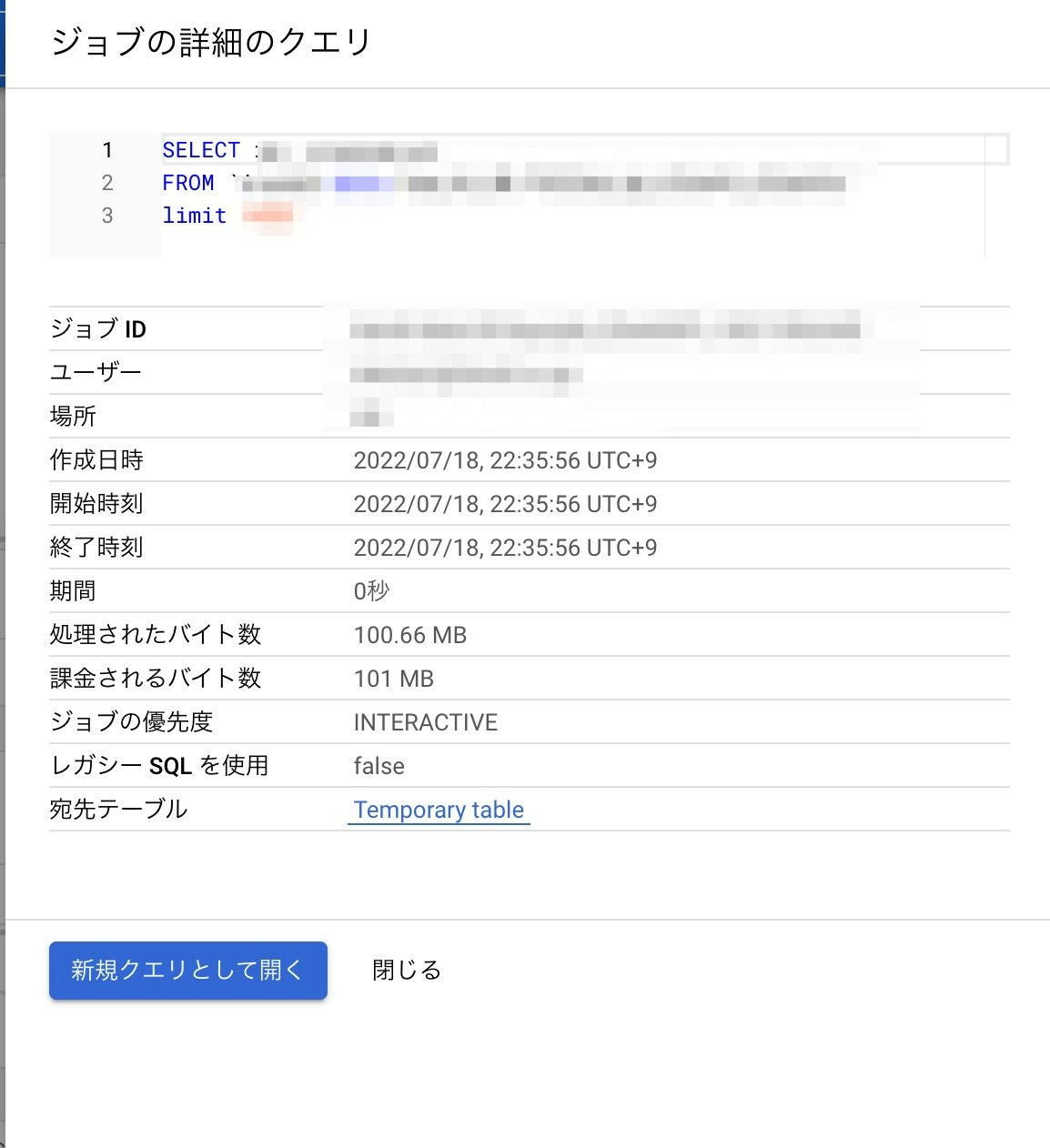
なお、BQのキャッシュについては、キャッシュに保存されているクエリ結果を使用する
に詳しく載っています。
2種類のクエリの保存方法:クエリとビュー
BQではクエリの保存方法として2つの方法があります。
それが、クエリとして保存するか、ビューとして保存するか、です。

簡単に用途の違いを説明すると、
クエリとして保存:何度か実行する可能性があるので、メモ的な形で保存しておきたい場合
ビューとして保存:呼び出した際にそのクエリが実行される仮想的なテーブルとして保存したい場合。 仮想テーブルは他のテーブルとjoinなども可能
です。詳細は以下に記載します。
クエリとして保存
クエリ自体をメモとして保存してしておきた場合は、こちらを使います。
保存方法として、2つあって、自分しか使わない場合は、個人用として保存。
全体で共有したい場合はプロジェクトに保存をします。
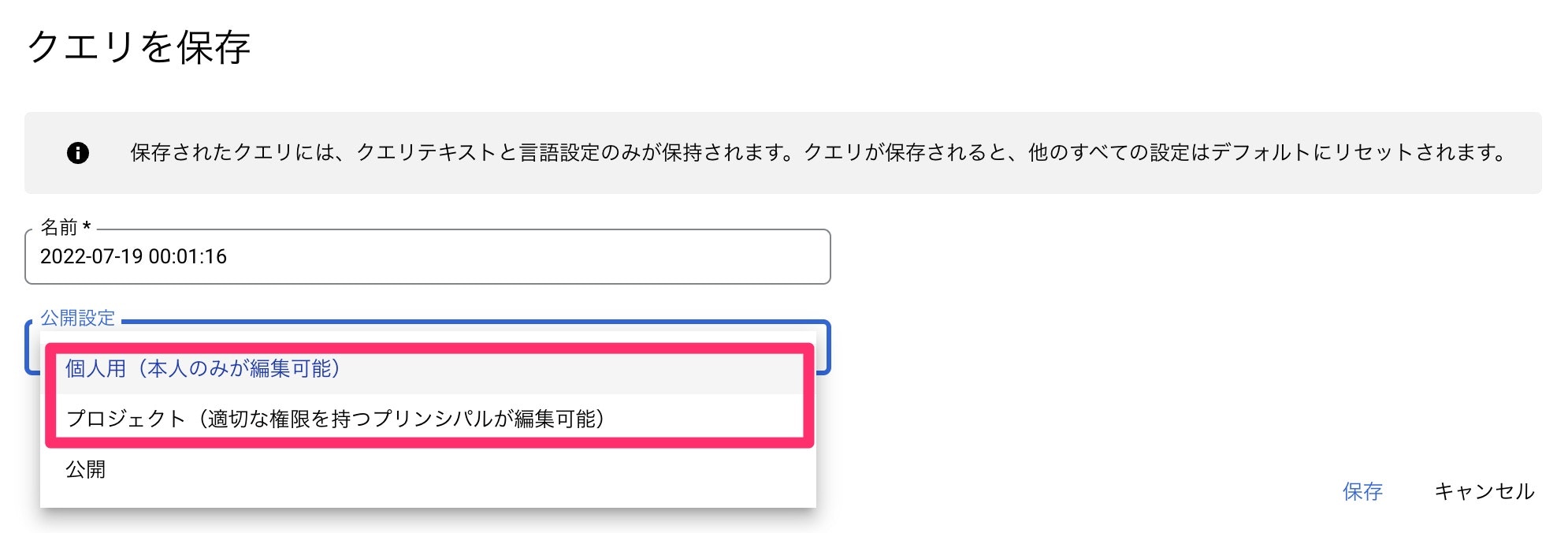
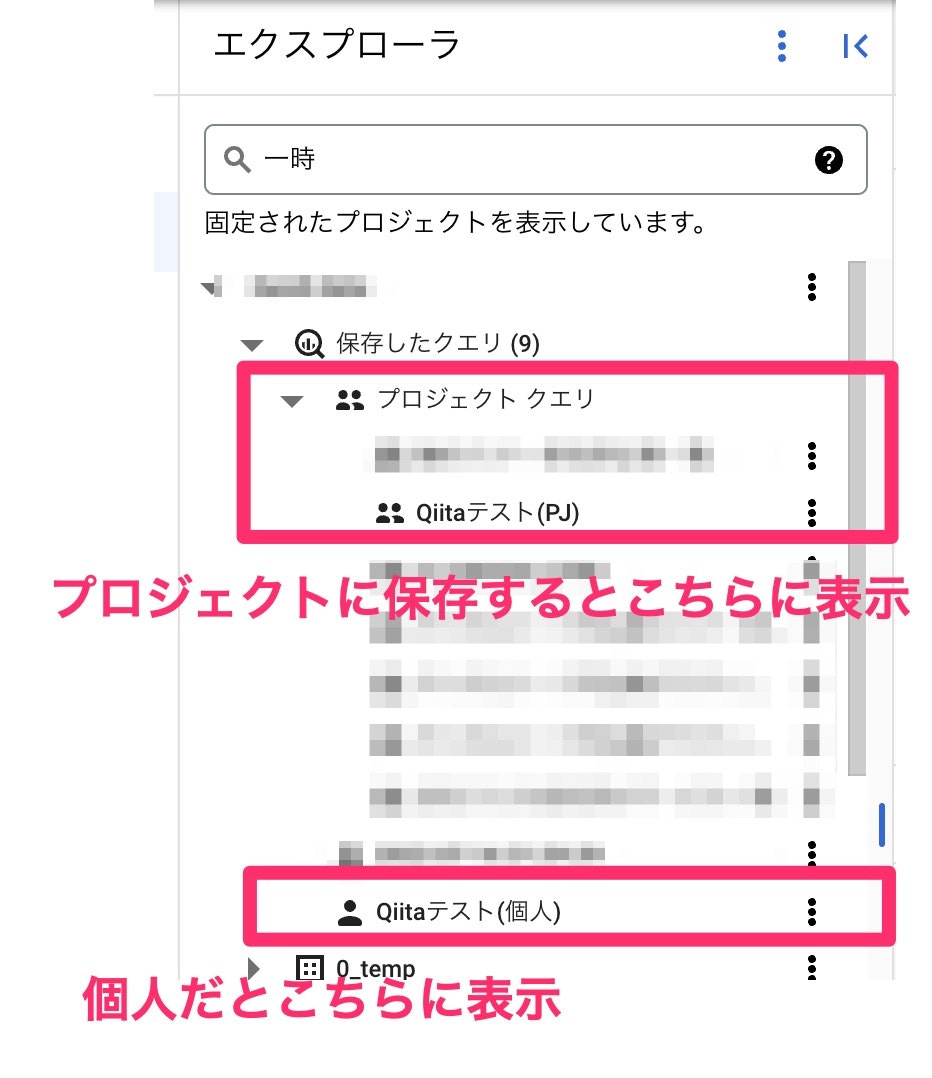
で、保存すると、画面左のエクスプローラーに表示されます。
保存場所を変えると表示場所やアイコンが変わります。
ビューとして保存
ビューとして保存するメリット
もう1つの方法がビューとして保存する場合です。
以下のような形で指定をすることで保存できます。

ビューとして保存するとデータセット内に表示され、あたかも1つのテーブルのように表示されます。
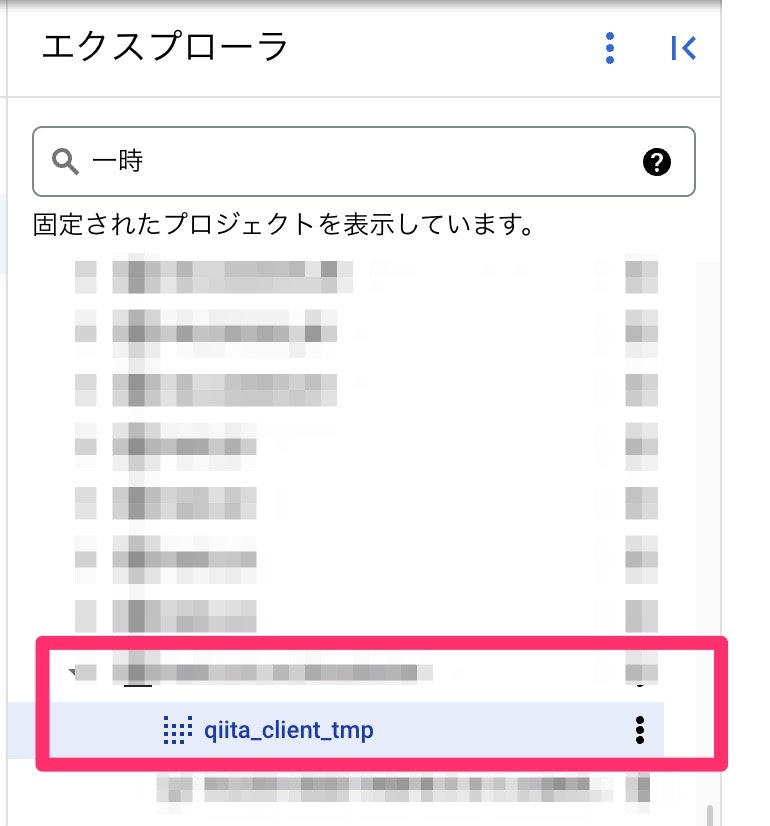
ビューとして保存できるメリットの1つがクエリの検索結果をテーブルとして利用できることです。
つまり、他のテーブルとJoinできるということです。
ビューを指定したクエリと注意事項
ビューとして保存したクエリは、FROM句で1つのテーブルとして指定可能です。
普通のテーブルデータのように扱うことができます。
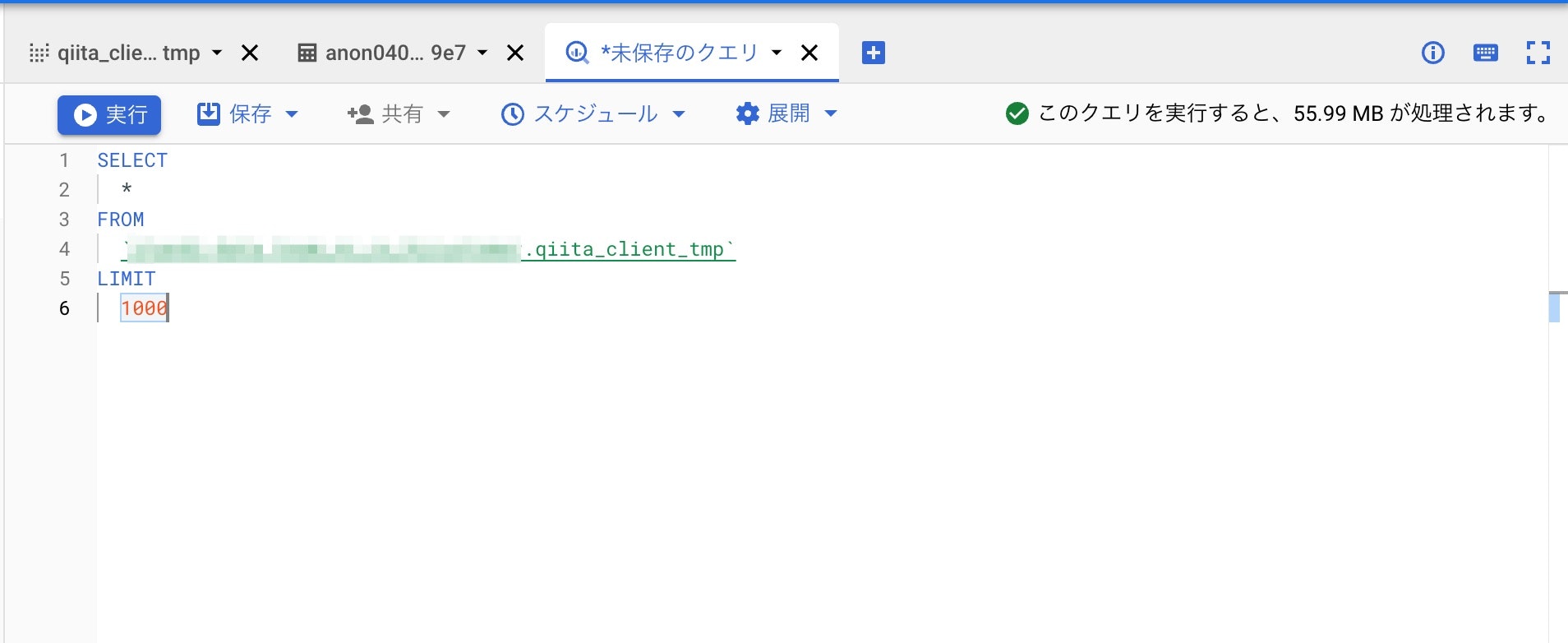
が、ここで注意事項があります。
ビューのクエリは参照される度に実行されるということです。
クエリ結果としては数行でも容量がめちゃめちゃ大きいクエリの場合、気軽に参照されると料金が膨らむ可能性があります。
そこで使えるのが、クエリ結果をテーブルとして保存する機能です。
クエリ結果をテーブルとして保存する機能
テーブルとして保存する方法
クエリ結果をテーブルとして保存する機能があります。
「おいおい。。。どんだけ保存方法あんねん!」と思わないで下さいw
まず、保存方法は以下の通りです。
保存からBigQueryテーブルを選択し、
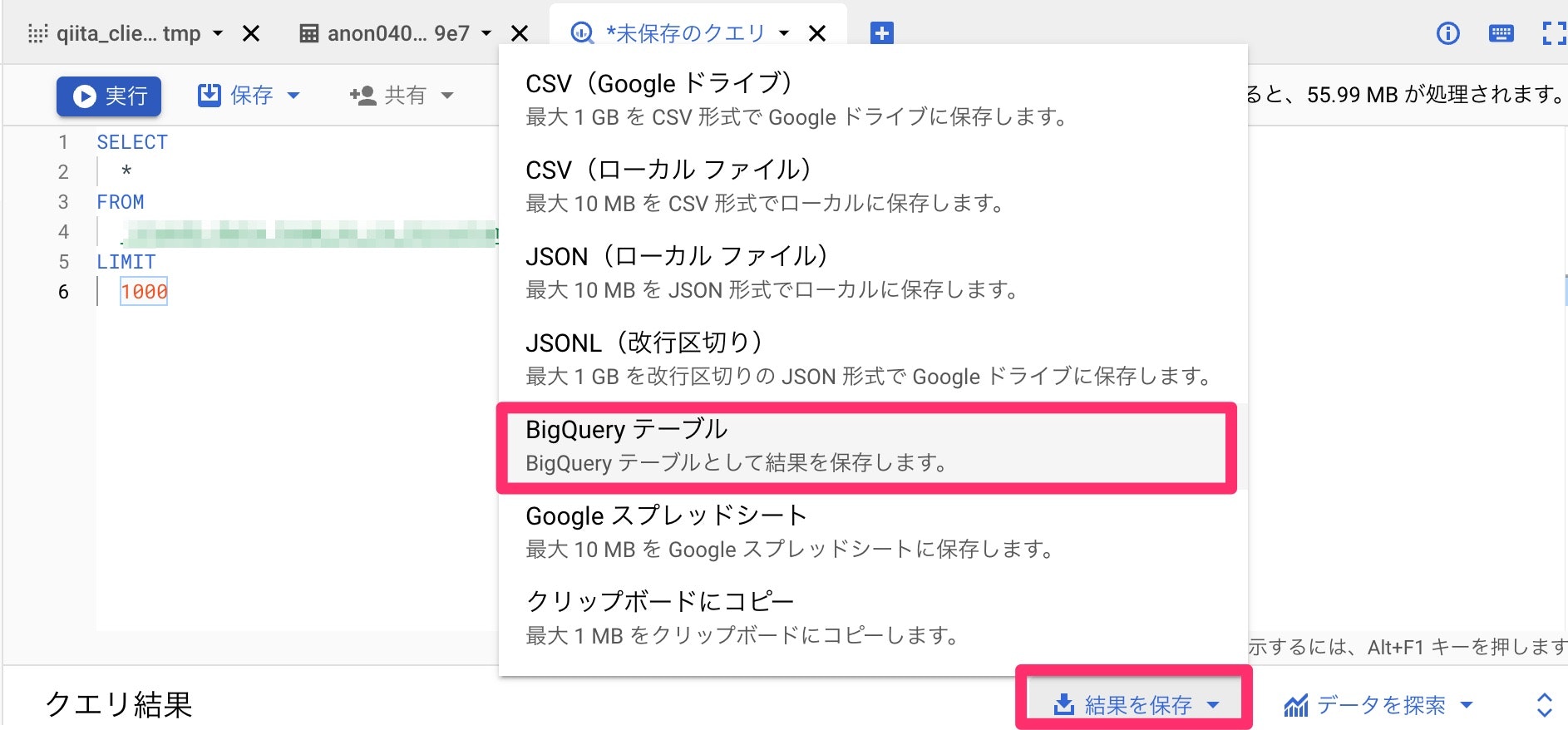
プロジェクト、データセット、テーブル名を入力します。
そうすると画面左のツリーのデータセット内に表示されます。
ビューとして保存した場合とテーブルとして保存した場合は、アイコンがちょっと違います。
ビューとテーブルの使い分け
ビューとテーブルを使いわけは、ざっくり以下の通りです。
他にもあると思いますのであくまで一例です。
【ビュー】
実行する度に結果が変わるものです。
例えば「最新のユーザー数」などです。もちろん、BQにあるデータは更新されていることが前提です。
【テーブル】
何度実行しても結果が変わらないものです。
例えば、2000-2010年までのユーザ数などです。
これは過去のデータであり、何度実行しても変わりません。
日付や日時の取り扱いに関して知っておくと良いこと
日時や日付関連のカラムのデータ型
BQでは、日時や日付関連のカラムのデータ型として、
- 日付型(DATE);0001-01-01~9999-12-31
- 日時型(DATETIME):0001-01-01 00:00:00~9999-12-31 23:59:59.999999
- タイムスタンプ型(TIMESTAMP):0001-01-01 00:00:00~9999-12-31 23:59:59.999999 UT
があります。
で、なぜにこんなことを話したかというと、where句でデータを絞ったり、データをエクスポートしたときに、このあたりを理解していないとハマるためです。
where句での比較時の注意
where句で日付を絞ってデータを出す時があると思います。
その際に、以下のようなノリでクエリを書いているとエラーが発生する時があります。
WHERE created_at >= DATE_SUB(CURRENT_DATETIME('Asia/Tokyo'), INTERVAL 1 month)
具体的にどういう時かと言うと、比較対象で型があっていないときです。
実行すると、
signature for operator >= for argument types: TIMESTAMP, DATETIME...
のようなエラーが出ます。
created_atのカラムはTIMESTAMP型で、DATE_SUB...の方はDATETIME型なので、型を合わせろというエラーです。
プロダクトDBに入っている際はDATETIME型でBQに入れるタイミングで型が変わるとこのようなことになります。
なお、この場合は、
DATETIME(created_at, 'Asia/Tokyo') >= DATE_SUB(CURRENT_DATETIME('Asia/Tokyo'), INTERVAL 1 month)
のようにすると、DATETIME型になり問題無くクエリは実行されます。
DATE_ADDやDATE_SUBなどの記法が若干違う
過去3ヶ月〜などのデータで絞り込む際にDATE_ADDやDATE_SUBを使うときがあると思いますが、少し記法が違う場合があります。
このあたりは調べながらやりましょう。その際は、型の違いも要注意です。
知っておくと良いこと
1. 仮想テーブル(with句)
BQには、仮想テーブル(with句)という便利な句があります。
SQLが読みづらくなるパターンとして、大きく2パターンあると思います。
- Joinが多い
- サブクエリが多い
本問題は、withを使うことで可読性を上げることできます。
詳細については書くと長いため、「BigQuery with句」などでググってくださいましw
なお、サクッと検索したところ、以下の記事はわりと分かりやすそうでした。
BQでは、select句でカラムを指定することが多そうなので、より重宝しそうです。
https://about-analysis.com/bigquery_with/
2. Record型のカラムの取り扱い(カラムの中にデータが入っている場合の)
テーブル/ビュー内のカラムは、1つのデータが入っている場合が多いかと思います。BQでは、RECORD型と呼ばれる型がありまして、その場合、1つのカラムの中に複数のデータを入れることができます。それがRecord型です。
Record型のカラムに対してselect文を実行する場合、クエリの書き方が少し特殊です。
詳細については、以下の記事が分かりやすかったので、Record型を見かけたら以下の記事を参考にして、データ抽出してください。
https://qiita.com/uehiro22/items/485bb30ce1a70457d335
3. ユーザー定義関数
BigQueryは、ユーザー定義関数(UDF)が使えます。
これを使うことで、クエリがかなりスッキリかけそうです。
UDFについては、ZoZoのテックブログに丁寧に詳しく解説されていました。
是非一度目を通しておくと良いと思います。
BigQueryでユーザー定義関数(UDF)は武器になるという話
4. スケジュール実行
BQでは、定期的にクエリをスケジュール実行することができます。
クエリを実行して、テーブルデータを更新する際に使えそうです。
ググればいくらでもやり方はでてきました。
注意事項
本機能は気軽に使える反面、クエリ実行時に料金もかかります。
1担当者が勝手に登録していくと管理面でも大変です。
勝手に登録せず、きちんと管理者に相談する形にしましょう。
5.データポータルやスプレッドシート(コネクテッドシート)との連携
BQの結果をデータポータルやスプレッドシートと同期させることができます。
以下の画面からできます。
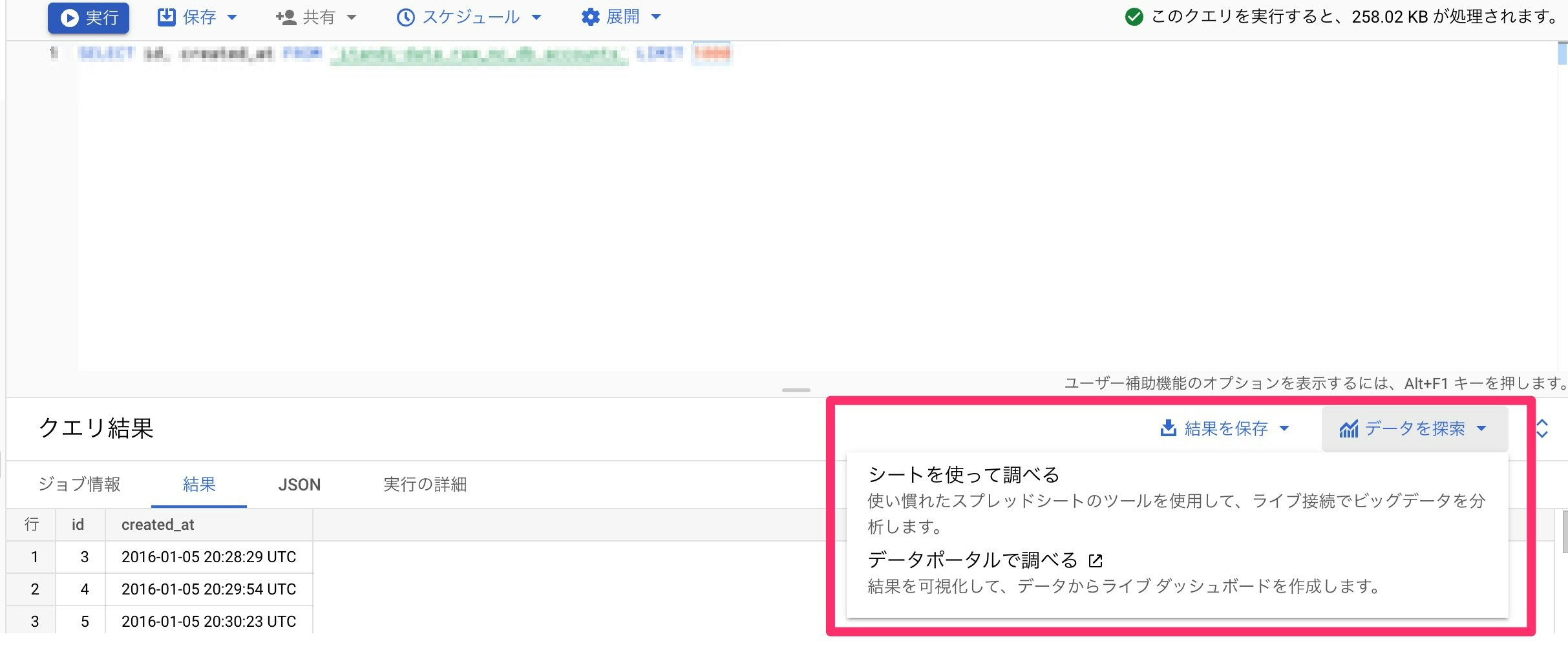
スプレッドシート連携(コネクテッドシート)については、以下のURLが参考になります!
https://cloud.google.com/bigquery/docs/connected-sheets?hl=ja
https://www.youtube.com/watch?v=rkimIhnLKGI
なお、データポータル連携は、少し注意が必要なようです。
頻繁にクエリが実行され、料金が肥大化するときがあるみたいです。
このあたりはきちんと調べてから使いましょう!