はじめに
業務でセッション データやUIDデータをGoogleAnalytycsから BigQuery にエクスポートし、BQをデータ基盤として活用しはじめた頃の話です。
その当時、GAからエクスポートされたデータが特徴的で最初に出したいデータが出せずハマったのでアウトプットしていきます。
※個人ブログから技術的アウトプットはQiitaへ引っ越ししたので、こちらは過去に書いたブログとなります。
ハマったポイント
下記のようなクエリで、とりあえずhoge_viewsのカウントをとりたかった。
select
event_params.value.string_value
, count(*) as hoge_views
from 'テーブル名'
where event_name = "play_count"
group by 1
order by hoge_views desc
すると
Cannot access field key on a value with type ARRAY<STRUCT<key STRING,
value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64
と、エラーになった。
上記のエラーは「配列内の要素にはアクセスできません」ということ。
「配列??」「テーブルに配列なんてあんの??」
となった。
BigQueryでよくみるデータ形式 - ネスト形式 -
実は、BigQueryのカラムには配列も入れることが可能で、
Google AnalyticsやFirebaseのデータには多くの配列が含まれています。
Fireabaseの送信する「イベント情報」は、1つのイベントに対してparamsという配列データが渡ってきます。
下記の部分で1行となり、
event_params.key や event_params.value.string_value
が配列となっています。

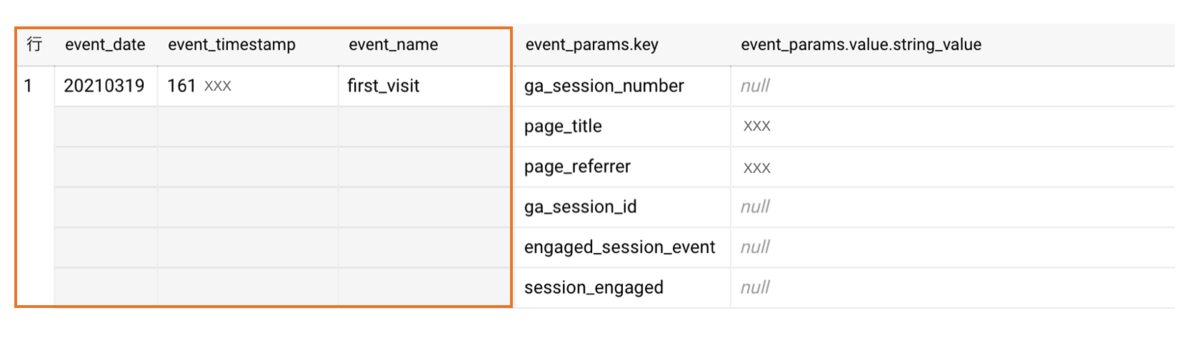
一方、event_dateやevent_timestamp, event_name は配列ではないため、空白になっています。
ですが、データがないわけではなく、下記のリストのようにevent_paramsの中にさらにデータが入っているという感じになるので、
表形式で表現すると空白ができてしまいます。
- event_date
- event_date
- event_timestamp
- event_name
- event_params
- event_params1
- event_params2
- event_params3
これを**「ネストされたデータ形式」**といいます。
ネストされたデータ形式
- 各レコードの1個のカラムに複数の値、つまり複数行に相当するデータを入れることができる仕様になっているのが大きな特徴
実際のデータ構造:1つのセルにテーブルが入るイメージ

- 通常のSQLであれば、**「列×行のデータ」**として格納されます。
- それに対して、「RECORD型(レガシーSQL)」「**配列型(標準SQL)」**は「ネストされた構造」を取ることとなり、ちょっと発想を変える必要がある。
type: RECORD型
mode: REPEATED
クエリでは
- 親エンティティ:
event_params - 子エンティティ:
event_params.key
のようにドットをつけたhoge.fugaの形式でアクセスできる。
配列の中身を取るにはUNNESTとCROSS JOIN
「BigQueryには配列がある」ということを説明しましたが、エラーにもあったように、配列の中身をそのまま参照することができないです。
そこで、配列の中身を参照するには、いったん配列を「展開」する必要があります。
それをできるのがUNNEST関数とCROSS JOIN。
- UNNEST は配列を行に展開する関数
- 「入れ子構造を解く」という働きをしてくれます。
- CROSS JOINは総当り的にJOINする結合方法。
- CROSS JOINとUNNESTを組み合わせて使い、元のテーブル
{bigqueryプロジェクトID}.{データセット}.{ga_sessions_*}に対して
配列のunnestをCROSS JOINのする。(相関クロス結合という処理)
書式と実行
書式
テーブル名 「,」 UNNEST as hoge-
,がCROSS JOINの役割
実際にUNNESTとCROSS JOINを使ってみる
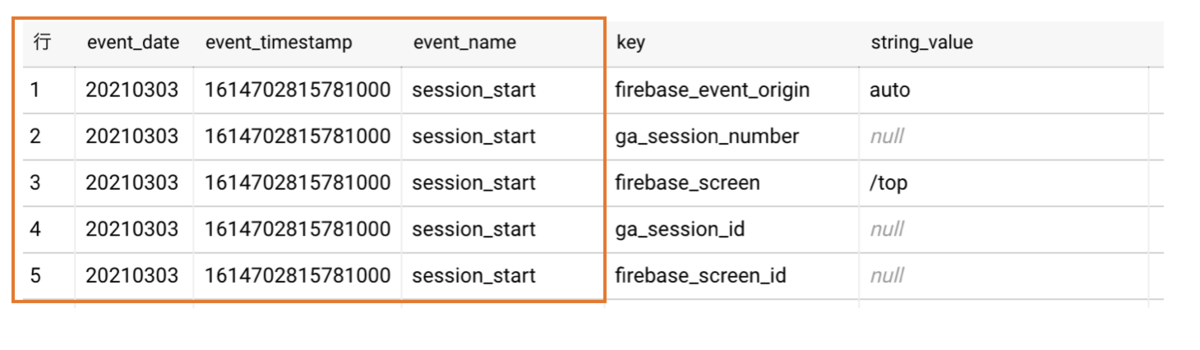
下記のようなSQLを実行すると、先程はevent_dateやevent_timestamp, event_nameが空白になっていたところが、埋め尽くされていて、
行番号も各行に振られているのがわかります。
select
event_date
, event_timestamp
, event_name
, e.key
, e.value.string_value
from 'テーブル名',unnest(event_params) as e
UNNEST前
UNNESTした結果
つまり
- UNNEST(配列)とすることで、配列が1行ずつに展開できる。
また、
-
テーブル名 「,」 UNNEST as hogeの,はCROSS JOINにも置き換えられる。つまり上記のSQLはいかに置き換えられる。
select
event_date
, event_timestamp
, event_name
, e.key
, e.value.string_value
from 'テーブル名',unnest(event_params) as e
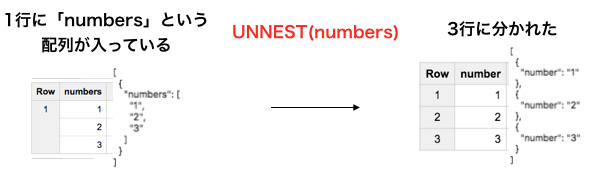
これらをうまく使って
select
e.value.string_value as hoge_name,
count(*) as hoge_views
from 'テーブル名',unnest(event_params) as e
where event_name = "hoge_play_count"
and e.key = "hoge_name"
group by 1
order by 2 desc
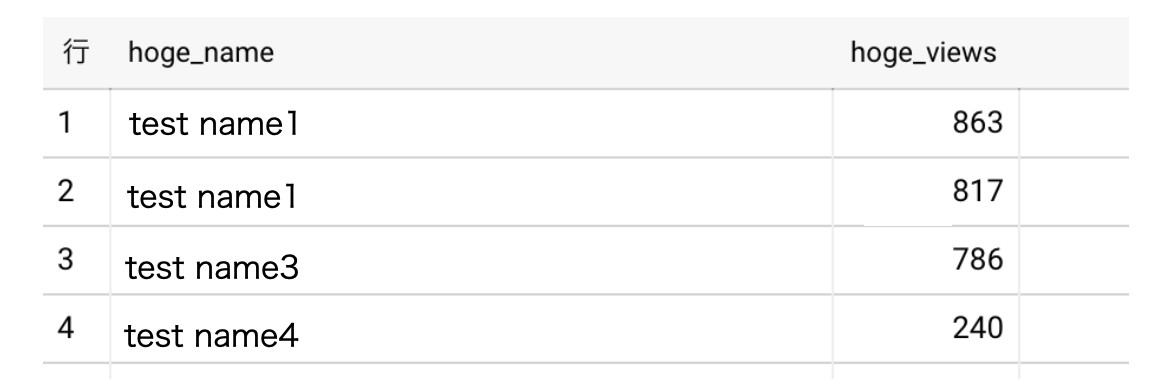
とネスト構造になっていたhoge_nameを抽出し、view数のランキングとして抽出できた。
よく使う事例2:unnestを使って配列を横展開
配列を横展開し、1つの行として複数列(横型)に変換したい場合がある。
-
ex/ 配列内のデータを失いたくない時
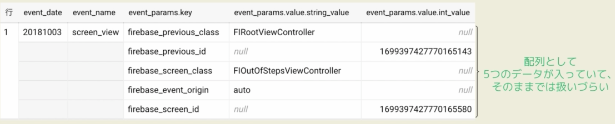
-
理想

このような場合、
selectの中で入れ子でselectする
どういうことかというと、
1/ from区の中でunnest関数を使って配列を展開
2/ whereでkey を指定
3/ selectで必要な列(value)を取得
4/ 横展開が必要なkeyに対して,1~3を繰り返す
select
event_date
, event_name
, (select value.int_value from unnest(event_params) where key = 'firebase_previpus_id') as prev
, (select value.int_value from unnest(event_params) where key = 'firebase_screen_id') as current
from 'テーブル名'
これで、横型にできる。
今日のまとめ
- BigQueryのカラムには配列も入れることが可能で、Google AnalyticsやFirebaseのデータには多くの配列が含まれている
- Fireabaseの送信する「イベント情報」は、1つのイベントに対して
paramsという配列データが渡ってくる。 - 配列の中身を参照するには、いったん配列を展開する必要があります。それをできるのがUNNEST関数とCROSS JOIN。
- UNNEST は配列をフラットなレコードに直す(展開する)ための関数
- 「入れ子構造を解く」という働きをしてくれます。
- CROSS JOINは総当り的にJOINする結合方法。
- 書式は
テーブル名 「,」 UNNEST as hoge -
「,」は、CROSS JOIN にも置き換えられる。つまりテーブル名 CROSS JOIN UNNEST as hogeでもOK