「cross join unnest」という関数と「split」関数を使えば実現できます。
サンプル
select
split_record
from
tbl_test t1
cross join unnest( --・・・(1)
split(t1.csv_column, ',') --・・・(2)
) as t (split_records)
処理概要
ざっくり説明すると
(2)のsplit関数で文字列(t1.csv_column)をカンマで分割して、配列にし、
その配列を(1)のcross join unnest関数で、単一の列のレコードに展開します。
イメージ
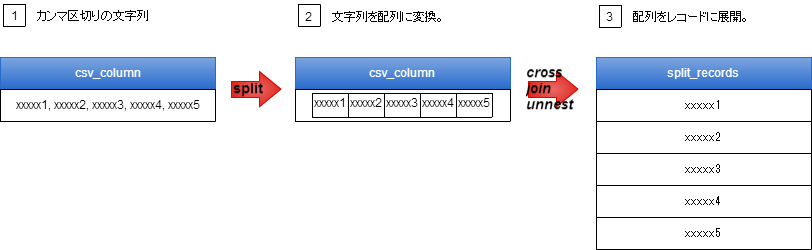
■split関数
split(文字列, 区切り文字)・・・
第1引数の文字列を第2引数の区切り文字で分割し、配列にします。
■cross join unnest関数
cross join unnest(配列) AS t (展開後のカラム名)・・・
第1引数の配列を単一の列のレコードに展開します。
カラム名は第2引数の展開後のカラム名になります。
まとめ
treasureデータなどのビックデータ基盤には、分析時に扱い易いように加工した上で
データが登録されているケースもありますが、必ずしもそうではなく
そのままでは分析に使い辛いようなデータも、登録されていることがあると思います。
今回のご紹介は、csv形式でデータが登録されているが
そのcsvの1区切りを1レコードとして扱いたい場合を例に紹介させて頂きました。
この記事が分析などの業務のお役に立てばと思います。