LangChainは、大規模な言語モデルを使用したアプリケーションの作成を簡素化するためのフレームワークです。言語モデル統合フレームワークとして、LangChainの使用ケースは、文書の分析や要約、チャットボット、コード分析を含む、言語モデルの一般的な用途と大いに重なっています。
LangChainは、PythonとJavaScriptの2つのプログラミング言語に対応しています。LangChainを使って作られているアプリケーションには、AutoGPT、LaMDA、CodeAnalyzerなどがあります。
- AutoGPTは、文章生成、翻訳、コード生成などの機能を持つアプリケーションです。
- LaMDAは、対話や文章生成を行うチャットボットです。
- CodeAnalyzerは、コードを分析するアプリケーションです。
記事概要
この記事では、LangChainの具体的な機能を紹介する前に、全体の概要の紹介と利用イメージを紹介します。
以下のオフィシャルサイトでの内容をまとめています。
具体的には、以下のトピックについて議論します。
- モデル (Models)
- プロンプト (Prompts): モデルに操作を実行させる方法
- インデックス (Indexes): データを取得する方法。モデルと組み合わせて使用可能
- チェーン (Chains): エンドツーエンドの機能の実現
- エージェント (Agents): 推論エンジンとしてのモデルの使用
なぜLangChainが必要なのか
LangChainは、LLMを操作するための抽象化とコンポーネントを提供するフレームワークです。このフレームワークでは、OpenAIだけではなく、他のモデルAzureMLやAWSのものとか、すべてサポートしています。
あと、自分の外部データを投入して、このデータに対して質問する際に、LangChainを利用して簡単にできます。
また、その他の履歴の管理やAgentなども便利なので、LangChainを使わない理由がないです。
事例- 質問の回答(Question Answering)
まずLangChainってどんな感じなのか、全体的にイメージを掴めてから後続内容を理解しやすくなります。
以下のページでの事例を実現します。
LangChainを通してローカルのデータを投入して、LLMに対して質問します。
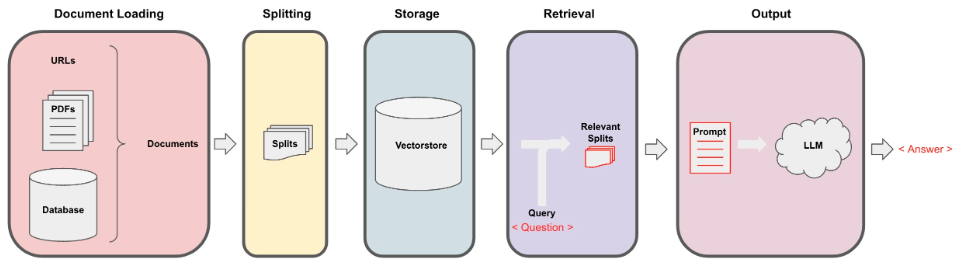
- ドキュメントを投入します。
- ドキュメントを分割します。
- 分割したものを外部やローカルのVectorストレージに保存します。
- 次は、抽出します。ユーザの質問と関連する分割されたデータを抽出します。
- ユーザ質問と分割されたデータを合わせて、プロンプトを作成します。最後に、このプロンプトをLLMに投げます。
必要なインストールと設定
! pip install langchain
! pip install openai
! pip install openai chromadb tiktoken
import os
import openai
from dotenv import load_dotenv, find_dotenv
# 環境変数取得:OPENAI_API_KEY
openai.api_key = os.environ['OPENAI_API_KEY']
環境変数の事前設定が必要です。
毎回APIキーを設定するのが面倒且つ不安全なので、環境変数に設定しておきます。
- 変数名:OPENAI_API_KEY
- 変数値:自身のOpenAIキー
from langchain.llms import OpenAI
# 以下の二つ:どちらでも大丈夫
llm = OpenAI(openai_api_key=openai.api_key) # 直接Key設定
# llm = OpenAI() # 環境変数からopenaiのapi keyを利用
print(llm)
出力結果、デフォルトの設定は以下の通りです。
OpenAI
Params: {'model_name': 'text-davinci-003', 'temperature': 0.7, 'max_tokens': 256, 'top_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'n': 1, 'request_timeout': None, 'logit_bias': {}}
次は二つライブラリのインストール:
# ChromaDBは、オープンソースのAIネイティブ埋め込みデータベースです。
# tiktokenは、OpenAI のモデルで使用する高速 BPE トークナイザーです
! pip install openai chromadb tiktoken
次は、SQLite関連のインストールです。
-
こちらからWindowsのバイナリファイル、
sqlite-tools-win32-*.zipとsqlite-dll-win64-*.zipの二つをダウンロードします。 - この二つZipファイルを
C:\sqliteに解凍して、sqlite3.def、sqlite3.dll、sqlite3.exeの三つファイルが解凍されます。 -
C:\sqliteをPATHの環境変数に追加します。 - 最後に、コマンドプロンプトで
sqlite3コマンドを入力して、sqliteが正常にインストールされたのかを確認します。
C:\Users\jun.li>sqlite3
SQLite version 3.43.1 2023-09-11 12:01:27
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite>
現在の実行環境を確認して、'c:\\Users\\jun.li\\AppData\\Local\\anaconda3'が出力されます。
import os
import sys
os.path.dirname(sys.executable)
プロキシサーバーがある場合は、以下のように、プロキシサーバーを設定します。
import os
os.environ['http_proxy'] = 'http://127.0.0.1:10809'
os.environ['https_proxy'] = 'http://127.0.0.1:10809'
外部データ(Webページ)取り込む
LangChainを使うと、外部データを取り組むことができます。LangChainでは、色んな外部データ(S3,Github...)を取り組めるコレクターがあります。こちらでまずWebページのを利用します。

詳細は以下のページをご参照ください。
以下のソースコードで、外部ウェブページをロードします。このウェブページでぎっくり腰の対処方法を紹介しています。
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
# 外部データをロード
loader = WebBaseLoader("https://www.nhk.or.jp/kenko/atc_558.html")
index = VectorstoreIndexCreator().from_loaders([loader])
次は質問してみる:
index.query("ぎっくり腰の原因は何ですか。50文字内で教えてください。")
出力結果が以下の通りで回答がありました。
' 不適切な姿勢や運動不足、筋肉の不均衡などが原因となります。'
が、本当に外部ウェーブページの参照をしていたかどうか、再度質問をしてみます。
index.query("テキストの購入希望があったら、どうすればいいですか。")
今回の結果は:' 書店かNHK出版お客様注文センター 0570-000-321 までお問い合わせください。'ですので、以下のウェーブページとあっているので、外部ウェーブページを参照しているのは間違いがないかと思います。

ステップ1:外部データ(PDF)のロード
これから、ステップ分けて、各ステップでの役割や入出力を見ていきます。せっかくなので、もっとUiPathの業務と近い請求書PDFを読み込んで、PDFに対して質問をしてみます。
請求書PDFは以下のようなものです:

外部のPDFを取り込むために、違うライブラリが必要なので、関連ライブラリをインストールします。
pip install unstructured
pip install pdf2image
pip install pdfminer.six
次はこの請求書PDFをロードします:
from langchain.document_loaders import OnlinePDFLoader
loader = OnlinePDFLoader("https://junli-web-host.s3.ap-northeast-1.amazonaws.com/invoice03.pdf")
data = loader.load()
data
dataを出力すると、PDFでのデータと同じだと分かります。
[Document(page_content='発行日\n\n2104/12/31\n\n請求No.\n\n23445984-0112\n\n請\u3000求\u3000書\n\n株式会社おはよう\u3000\u3000\u3000\u3000御中\n\n株式会社ROBOT PAYMENT\n\n下記の通り、ご請求申し上げます。\n\n〒150-0001\n\n合計金額\n\n108,000\n\n東京都渋谷区神宮前6-19-20-4F\n\nTEL: 03-5469-5780\n\n振 込 先 :\n\n三井住友銀行\u3000蒲田支店(普通)4233765\n\nカ)ロボットペイメント\n\n支 払 期 日 :\n\n令和3年6月30日\n\n※ 振込手数料は貴社ご負担にてお願い申し上げます。\n\n品番・品名\n\n数量\n\n単位\n\n単価\n\n金額\n\nデザイン\n\n2\n\n頁\n\n20,000\n\n40,000\n\n企画•取材費用\n\n1\n\n式\n\n60,000\n\n60,000\n\n備\u3000考:\n\n小計\n\n100,000\n\n消費税(10%)\n\n10,000\n\n合計金額\n\n110,000', metadata={'source': 'C:\\Users\\jun.li\\AppData\\Local\\Temp\\tmpm9s6n1es\\tmp.pdf'})]
ステップ2:データ分割
今回のPDFは一枚しかないですが、ファイルが大きくなると、分割しないと、LLMモデルのToken制限サイズを超えてしまうので、データを分割します。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 200, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
len(all_splits)
all_splitsの長さの出力が4なので、4分割されています。一つ目の分割されたデータを確認します。
all_splits[0]
出力がPDFの一部なので、分割されていることが分かります。
Document(page_content='発行日\n\n2104/12/31\n\n請求No.\n\n23445984-0112\n\n請\u3000求\u3000書\n\n株式会社おはよう\u3000\u3000\u3000\u3000御中\n\n株式会社ROBOT PAYMENT\n\n下記の通り、ご請求申し上げます。', metadata={'source': 'C:\\Users\\jun.li\\AppData\\Local\\Temp\\tmpm9s6n1es\\tmp.pdf'})
ステップ3:保存
文書を分割して検索するためには、最初にそれらを後で参照できる場所に保存する必要があります。これを行う最も一般的な方法は、各文書の内容を埋め込み、その埋め込みと文書をベクトルストアに保存することです。埋め込みは文書のインデックスとして使用されます。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
ステップ4:抽出
こちらは分割して保存されたデータから、ベクトル類似度を計算して、質問と近いの分割データを抽出します。(KNN、SVNなどの分類アルゴリズムを使って類似度計算して分類します。)
question = "振込の口座番号を教えてください。"
docs = vectorstore.similarity_search(question)
len(docs)
出力が4ですので、全部のデータが関連データと認識されました。
ステップ5: 生成
取得したドキュメントをLLM/Chatモデル(例:gpt-3.5-turbo)を使用してRetrievalQAチェーンで答えにまとめます。
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever())
qa_chain({"query": question})
出力が以下の通り:
{'query': '振込の口座番号を教えてください。',
'result': '振込先の口座番号は「三井住友銀行\u3000蒲田支店(普通)4233765」です。'}
ステップ6: チャット
チャットするため、LangChainでのチャット履歴を設定します。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
メモリをchatに設定します:
from langchain.chains import ConversationalRetrievalChain
retriever = vectorstore.as_retriever()
chat = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
質問をしてみます:
result = chat({"question": "請求元の住所を教えてください。?"})
result['answer']
出力結果:
'請求元の住所は「東京都渋谷区神宮前6-19-20-4F」です。'
もう一つ質問をしてみます:
result = chat({"question": "振込手数料はどちら負担ですか?"})
result['answer']
出力結果:
'振込手数料は貴社ご負担にてお願い申し上げます。'
クイックスタート
こちらのクリックスタートでは、LLMアプリケーションを構築します。LangChainは、LLMアプリケーションを構築するために使用できる多くのモジュールを提供しています。モジュールは、シンプルなアプリケーションで単体として使用することができるほか、より複雑な使用ケースのために組み合わせることもできます。
以下の3つが最も重要なものです:
- LLM:言語モデルは、ここでの主要な推論エンジンです。LangChainで作業するためには、異なるタイプの言語モデルとそれらの使用方法を理解する必要があります。
- プロンプトテンプレート:これは言語モデルへの指示を提供します。これにより、言語モデルの出力が制御されるため、プロンプトの構築方法や異なるプロンプティング戦略を理解することが重要です。
- OutputParsers:これらは、LLMからの生の応答をより取り扱いやすい形式に変換し、出力を下流で簡単に使用できるようにします。
これからこの三つを紹介します。
LLM
Langchainでは、LLMs(Large Language Models)とChat Modelsの2つの異なるモデルタイプが提供されています。
- LLMs:LLMsは、テキスト文字列を入力として受け取り、テキスト文字列を返すモデルです。これは、OpenAIのGPT-3などの純粋なテキスト補完モデルを指します。
- ChatModels:一方、Chat Modelsは、LLMsをベースにしていますが、会話を行うために特別に調整されたモデルです。これらのモデルは、チャットメッセージのリストを入力として受け取り、AIのチャットメッセージを出力として返します。通常、これらのメッセージには話者(通常は「システム」、「AI」、「人間」のいずれか)がラベル付けされます。
LangChainが提供する標準インターフェースには2つの方法があります:
- predict: 文字列を入力として受け取り、文字列を返します。
- predict_messages: メッセージのリストを入力として受け取り、メッセージを返します。
LLMs
LLMsの入力/出力はシンプルで理解しやすいです。
from langchain.llms import OpenAI
llm = OpenAI()
llm.predict("おはようございます!!")
出力結果:'\n\nおはようございます!今日も一日頑張りましょう!'
text = "入社する際の挨拶お願い致します。?"
llm.predict(text)
出力結果:'\n\nお世話になります。私は◯◯といいます。社内のみなさんにお会いできるのを楽しみにしております。一緒に仕事をしていくことを楽しみにしています。よろしくお願い致します。'
predict_messagesを使ってみます:
from langchain.schema import HumanMessage
messages = [HumanMessage(content=text)]
llm.predict_messages(messages)
出力が:
AIMessage(content='\n\nBot: はじめまして。私は○○と申します。今日からお世話になります。よろしくお願いいたします。')
ChatModels
ChatModelsの方がより設定ができます。入力はChatMessagesのリストで、出力は単一のChatMessageです。ChatMessageには2つの必須のコンポーネントがあります:
- content: メッセージの内容です。
- role: ChatMessageが来ているエンティティのロールです。
roleには、以下の四つがあります。
- HumanMessage: ユーザーや人間からのメッセージ。
- AIMessage: AIやアシスタントからのメッセージ。
- SystemMessage: システムからのメッセージ。
- FunctionMessage: 関数呼び出しからのメッセージ。
実際に試してみます:
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI()
chat_model.predict("おはようございます!")
出力が'おはようございます!どのようなご用件でしょうか?'。
次もpredict_messagesを使います:
chat_model.predict_messages(messages)
出力結果:
AIMessage(content='はじめまして、私は〇〇と申します。入社しました新入社員の一人です。まずは皆様にお会いできて嬉しく思っております。これから一緒に働くことを楽しみにしております。\n\n私は〇〇出身で、〇〇大学で〇〇を専攻していました。入社前には〇〇の経験も積んでおり、〇〇のスキルを持っています。これからは会社の一員として、皆様のお力になれるよう努めてまいります。\n\n入社後は、先輩方から多くのことを学びたいと思っております。どうぞよろしくお願いいたします。私自身も、できるだけ早く仕事に慣れて、皆様と協力しながら成長していきたいと思っております。\n\nまた、コミュニケーションを大切にし、チームワークを大事にしたいと考えております。どんな小さなことでも積極的に相談したり、助け合ったりする姿勢を持ちたいと思っております。皆様のお力をお借りしながら、一緒に素晴らしい成果を生み出していけるよう努めます。\n\nこれから一緒に働く皆様には、多くのことを学びたいという思いと、信頼関係を築いていくことを大切にしています。どうぞよろしくお願いいたします。')
また、2つの関数に対して、temperatureもパラメータに入れて確認します。
llm.predict(text,temperature=1)
llm.predict_messages(messages,temperature=1)
chat_model.predict(text,temperature=1)
chat_model.predict_messages(messages,temperature=1)
プロンプトテンプレート
通常、ユーザーの入力を追加して、特定のタスクの追加の文脈を提供する大きなテキスト、プロンプトテンプレートと呼ばれるものに追加します。
プロンプトテンプレートでは、ユーザーの入力から完全にフォーマットされたプロンプトに移行するすべてのロジックをまとめています。
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("これから会社を作りたくて、この会社では {product}を作っています、どんな会社名がいいですか?")
prompt.format(product="色んな色の靴下")
組み合わせしたプロンプト文は以下の通りです:
'これから会社を作りたくて、この会社では 色んな色の靴下を作っています、どんな会社名がいいですか?'
PromptTemplatesは、メッセージのリストを生成するためにも使用することができます。この場合、プロンプトは内容に関する情報だけでなく、各メッセージ(その役割、リスト内での位置など)についても情報を含みます。ここで最もよく起こるのは、ChatPromptTemplateがChatMessageTemplatesのリストであることです。各ChatMessageTemplateには、そのChatMessageをフォーマットする方法、その役割、そしてその内容に関する指示が含まれています。以下でこれを見てみましょう:
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
template = "あなたはプロの{input_language} から{output_language}への翻訳者です."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chat_prompt = chat_prompt.format_messages(input_language="日本語", output_language="英語", text="仕事が大好きです.")
chat_prompt
出力結果:作ったプロンプトは:
[SystemMessage(content='あなたはプロの日本語 から英語への翻訳者です.'),
HumanMessage(content='仕事が大好きです.')]
使ってみると:
llm.predict_messages(chat_prompt)
結果が:
AIMessage(content='\n\nI love my job.')
chat_modelも同じです、出力結果がAIMessage(content='I love my job.')です。
chat_model.predict_messages(chat_prompt)
OutputParsers
OutputParsersは、LLMの生の出力を、下流で使用できる形式に変換します。主なOutputParsersのタイプはいくつかあり、以下の通りです:
- LLMからのテキストを構造化された情報(例:JSON)に変換する
- ChatMessageを文字列のみに変換する
- メッセージの他に呼び出しから返される追加情報(OpenAIの関数呼び出しのような)を文字列に変換する。
from langchain.schema import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser):
"""LLMの呼び出し結果をカンマ区切りのリストに解析する。"""
def parse(self, text: str):
"""LLMの出力を解析する."""
return text.strip().split(", ")
CommaSeparatedListOutputParser().parse("おはようございます, さようなら")
出力結果:
['おはようございます', 'さようなら']
三者組み合わせ
これらすべて(ChatModels、プロンプトテンプレート、OutputParsers )を一つのチェーンに組み合わせることができます。
このチェーンは入力変数を受け取り、それをプロンプトテンプレートに渡してプロンプトを作成し、そのプロンプトを言語モデルに渡し、そして出力を(オプションの)出力パーサーを通して渡します。
これは、モジュラーなロジックの部分をまとめる便利な方法です。それを実際に見てみましょう!
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.schema import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser):
"""LLMの出力をカンマ区切りのリストに解析する."""
def parse(self, text: str):
"""LLMの出力を解析する."""
return text.strip().split(", ")
template = """あなたは、カンマ区切りのリストを生成する役立つアシスタントです。
ユーザーはカテゴリを入力し、そのカテゴリ内の5つのオブジェクトをカンマ区切りのリストで生成する必要があります。
カンマ区切りのリストのみを返し、それ以上のものは返してはいけません。."""
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chain = LLMChain(
llm=ChatOpenAI(),
prompt=chat_prompt,
output_parser=CommaSeparatedListOutputParser()
)
chain.run("色んな色")
出力結果:['赤', '青', '黄色', '緑', 'オレンジ']です。
また、最後の部分の呼び出し方ですが、以下のもできます、同じ結果になります。
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
chain = chat_prompt | ChatOpenAI() | CommaSeparatedListOutputParser()
chain.invoke({"text": "色んな色"})
Agent
Agentのコアなアイディアは、LLMを使用して取るべきアクションのシーケンスを選択することです。エージェントでは、どのアクションを取るべきか、そしてどの順序で取るべきかを判断するための推論エンジンとして言語モデルが使用されます。
こちらでgoogle-searchのAPIを使うので、先にインストールします
pip install google-search-results
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
import os
os.environ["SERPAPI_API_KEY"] = "b3b7b3014ad3fb61039c66010d486d55e2e2869fb890ea4adbfc729078b5c48f"
tools = load_tools(["serpapi", "llm-math"], llm=llm)
上記のGoogle Search APIのため、こちらでAPIキーを発行します。
Agentを初期化します。
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=False)
agent.run("現在の日本の総理大臣は誰ですか? 総理大臣の奥様がおいくつですか")
出力結果:
'現在の日本の総理大臣はFumio Kishidaで、奥様は59歳です。'
途中のアクションも確認するとしたら:
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("現在の日本の総理大臣は誰ですか? 総理大臣の奥様がおいくつですか")
出力結果:
[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m I need to find out who the current Prime Minister of Japan is and how old their spouse is.
Thought: I should use a search engine to find this information.
Action: Search
Action Input: Current Prime Minister of Japan[0m
Observation: [36;1m[1;3mFumio Kishida[0m
Thought:[32;1m[1;3m I should search for the age of the Prime Minister's spouse.
Action: Search
Action Input: Age of Fumio Kishida's spouse[0m
Observation: [36;1m[1;3m59 years[0m
Thought:[32;1m[1;3m I now know the final answer.
Final Answer: 現在の日本の総理大臣はFumio Kishidaで、その奥様は59歳です。[0m
[1m> Finished chain.[0m
'現在の日本の総理大臣はFumio Kishidaで、その奥様は59歳です。'
Memory
ほとんどのLLMアプリケーションは会話型のインターフェースを持ち、過去のメッセージを参照する能力が必要です。この情報の保存能力を「メモリ」と呼びます。LangChainは、このメモリ機能をシステムに追加するためのユーティリティを多く提供しています。
from langchain import OpenAI, ConversationChain
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, verbose=True)
conversation.predict(input="こんにちは!")
出力結果:
[1m> Entering new ConversationChain chain...[0m
Prompt after formatting:
[32;1m[1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: こんにちは!
AI:[0m
[1m> Finished chain.[0m
' こんにちは!私はAIです。どうぞよろしくお願いします!'
conversation.predict(input="元気です!ただAIと会話をしているだけです。")
出力結果:
[1m> Entering new ConversationChain chain...[0m
Prompt after formatting:
[32;1m[1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: こんにちは!
AI: こんにちは!私はAIです。どうぞよろしくお願いします!
Human: 元気です!ただAIと会話をしているだけです。
AI:[0m
[1m> Finished chain.[0m
' 私も元気です!会話を楽しみにしています!あなたは何をしていますか?'
ここで、メモリにあった会話を確認します。
conversation.predict(input="私は一番最初に何が言った?")
出力結果:
[1m> Entering new ConversationChain chain...[0m
Prompt after formatting:
[32;1m[1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: こんにちは!
AI: こんにちは!私はAIです。どうぞよろしくお願いします!
Human: 元気です!ただAIと会話をしているだけです。
AI: 私も元気です!会話を楽しみにしています!あなたは何をしていますか?
Human: 私は一番最初に何が言った?
AI:[0m
[1m> Finished chain.[0m
' あなたは「こんにちは!」と言いました!'
上記のCurrent conversationで表示したように、全ての会話がメモリに残っています。
最後に
これで完了です!LangChainアプリケーションの中核となる部品の作り方の概要の紹介をしました。これから各部品の詳細を見ていきます。