UiPath Document Understanding 第4回 基礎編 テンプレートを使おうの記事で、UiPath Studioで付属しているDocumentUnderstanding処理のテンプレートを利用して、英語版のドキュメント処理をしました。
そのテンプレートでは、デフォルトとして英語版ドキュメント処理が行われます。従って、日本語ドキュメントを処理するためには複数の修正が必要となります。
修正する箇所はUiPath Document Understanding 第3回 基礎編 日本語請求書と源泉徴収票からデータ抽出しようでの解説と同じです。第三回をまだ読んでいない方は、そちらを先にご覧ください。
1. 事前準備
今回の日本語請求書処理も、有人オートメーションとして実行するため、テンプレートでプロジェクトを作成した後、必要な環境設定やメインワークフローの変更が必要です。
手順:
- UiPath Studioを起動して、[スタート]パネル右側の[テンプレートから新規作成]より[Document Understanding Process]を選択してプロジェクトを作成します。
- UiPath OCRエンジンで必要なDocumentUnderstanding用のAPIキーを取得するため、Orchestratorで必要なアセットを設定します補足1。
- UiPath Studioで、実行フォルダや
Main-Attended.xamlのメイン設定をします補足2。 - 本記事で利用するPDFは日本語請求書サンプルPDFよりダウンロードします。
- プロジェクトフォルダ内のPDF(
\Data\ExampleDocuments\MergedDocuments.pdf)を削除して、ダウンロードした日本語請求書PDFを\Data\ExampleDocuments\フォルダに入れてください。
補足1 : 詳細は環境設定(アセット作成)で記載しています。
補足2 : 詳細はMain-Attended.xamlをメインに設定で記載しています。
2. タクソノミー定義の追加
既存のテンプレートには、英語版の四種類のドキュメントの定義しか含まれていないため、日本語請求書の定義を追加する必要があります。
以下のテーブルには、請求書から抽出した項目が示されています。
| No | フィールド名 | 種類 | 列-フィールド名 | 列-種類 |
|---|---|---|---|---|
| 1 | 会社名 | Name | ||
| 2 | 住所 | Address | ||
| 3 | 請求先会社名 | Name | ||
| 4 | 請求先会社住所 | Address | ||
| 5 | 日付 | Date | ||
| 6 | 品目明細 | Table | ||
| 6.1 | 品名 | Text | ||
| 6.2 | 数量 | Number | ||
| 6.3 | 単価 | Number | ||
| 6.4 | 金額 | Number | ||
| 7 | 総額 | Number |
UiPath Studioからタクソノミーマネージャーを起動して、[タクソノミー → Semi-StructuredDocuments → Financial]の配下で、[InvoiceJapan]の新しいドキュメント種類を追加して、上記テーブルでのフィールドを定義してください。

3. Configファイルでエンドポイントの変更
第3回 基礎編 日本語請求書と源泉徴収票からデータ抽出しようで解説したように、日本語帳票を処理するために、OCRエンジンの変更及びエンドポイントの変更が必要です。
テンプレートでは、エンドポイントがConfigファイルに保存しているので、先にConfigファイルを修正します。
Data\Config.xlsxでは、該当テンプレートで使われている各種パラメータを保存しています。今回日本語帳票を処理するため、[Settings]シートでのUiPathOcrEndpointとInvoicesEndpointの中身を変更する必要があります。
今回では、関連しているワークフローのアクティビティでの設定が、どのように関連しているかを解説するため、UiPathOcrEndpointとInvoicesEndpoint項目での中身をそのまま変更ではなく、二つ日本語帳票処理用の項目UiPathOcrEndpointCJKとInvoicesEndpointJapanを追加します。
パブリック エンドポイントページを参照して、ChineseJapaneseKoreanOCR (中国語、日本語、韓国語用の OCR)とInvoicesJapan (請求書 - 日本) (プレビュー)のURLを取得して、Configファイルの[Setting]シートに以下のように設定します。
- UiPathOcrEndpointCJK :
https://du-jp.uipath.com/cjk-ocr - InvoicesEndpointJapan :
https://du.uipath.com/ie/invoices_japan
追加後、エンドポイントの設定は以下の通りです。

4. デジタル化の変更
Framework\20_Digitize.xamlでは、ドキュメントのデジタル化をしています。日本語帳票をデジタル化するために、OCRエンジンの変更及びエンドポイントの変更が必要です。
手順:
-
Framework\20_Digitize.xamlを開いて、Retry Scope - Digitizeアクティビティをコピーして、名前をRetry Scope - Digitize_CJKに変更します。元のRetry Scope - Digitizeアクティビティをコメントアウトします。(*値を参照するため、削除しないにしています) - Retry Scope - Digitize_CJKアクティビティでのUiPath Document OCR - Digitizeアクティビティを削除して、OCR - 日本語、中国語、韓国語アクティビティを追加します。
- OCR - 日本語、中国語、韓国語アクティビティでの値を次の通りで設定します。
- APIキー:
in_Config("ApiKey") - エンドポイント:
in_Config("UiPathOcrEndpointCJK")(CJKのエンドポイントに変更)
- APIキー:
手順で変更したら、Write Lineアクティビティをつかって、ディジタル化の結果を確認してみましょう。
5. 分類器の変更
日本語請求書を分類するため、分類器でタクソノミーで追加されたInvoiceJapanの分類を追加する必要があります。
手順:
-
Framework\30_Classify.xamlを開いて、分類器を設定をクリックします。 - 分類器を設定 画面で、ドキュメントの種類のInvoiceJapanもIntelligent Keyword Classifier - Classifyのチェックを入れてください。
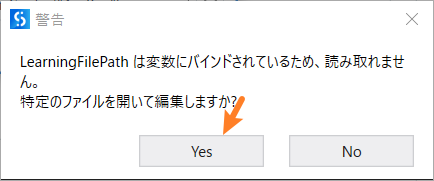
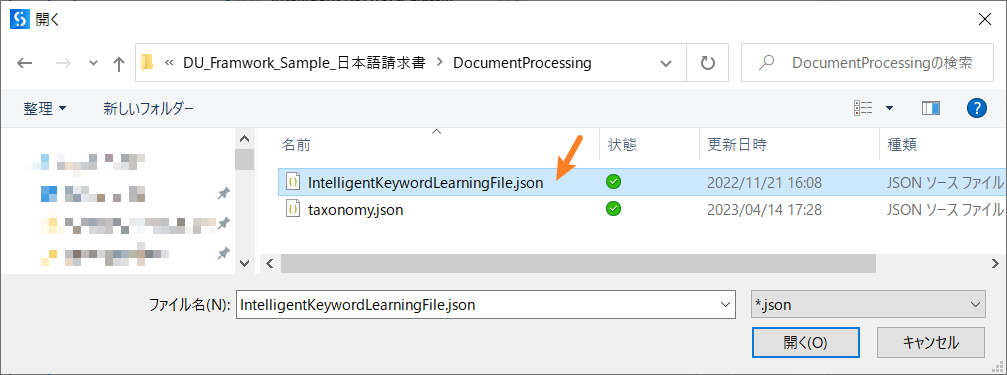
- 次に、学習を管理をクリックします、警告が表示されますので、Yesをクリックして、プロジェクトフォルダ内の[DocumentProcessing\IntelligentKeywordLearningFile.json]を選んでください。
- 次に、インテリジェントキーワード分類器 画面でInvoiceJapanの[トレーニングを開始...]をクリックします。
- 次の画面に、日本語請求書を選択してトレーニングを開始します。
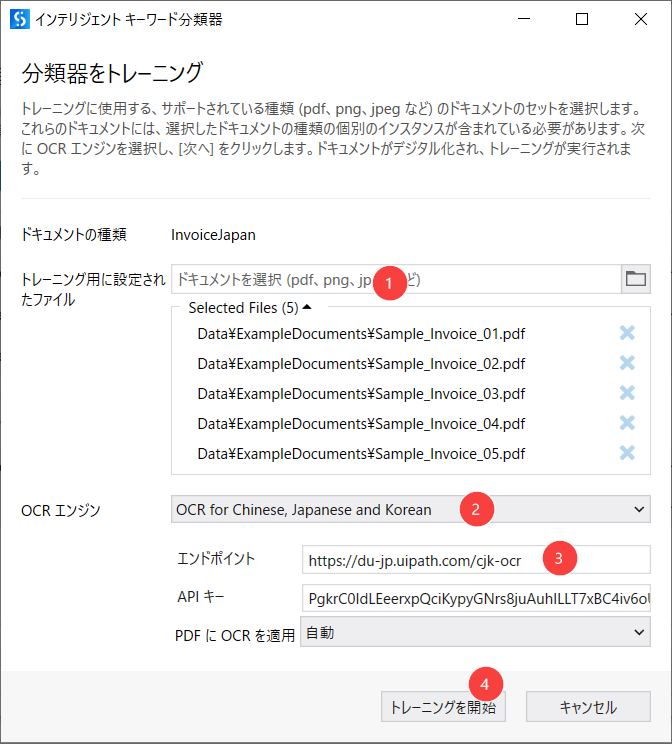
- トレーニングが終わったら、インテリジェントキーワード分類器で保存をクリックします。
- 最後に、Classify Document Scope - Classifyアクティビティの分類器を設定をクリックして、今回のInvoiceJapanもチェックします。
6. 抽出器(マシンラーニング抽出器)の変更
次に、日本語請求書に合わせてマシンラーニング抽出器を追加します。
手順:
-
Framework\50_Extract.xamlを開きます。 - マシンラーニング抽出器アクティビティを[Data Extraction Scope]に入れます。
- 表示された[マシンラーニング抽出器]画面では、エンドポイントに
https://du.uipath.com/ie/invoices_japanを入力して、機能を取得をクリックしてください。 - マシン ラーニング抽出器 アクティビティの名前をInvoicesJapan ML Extractorに変更してください。
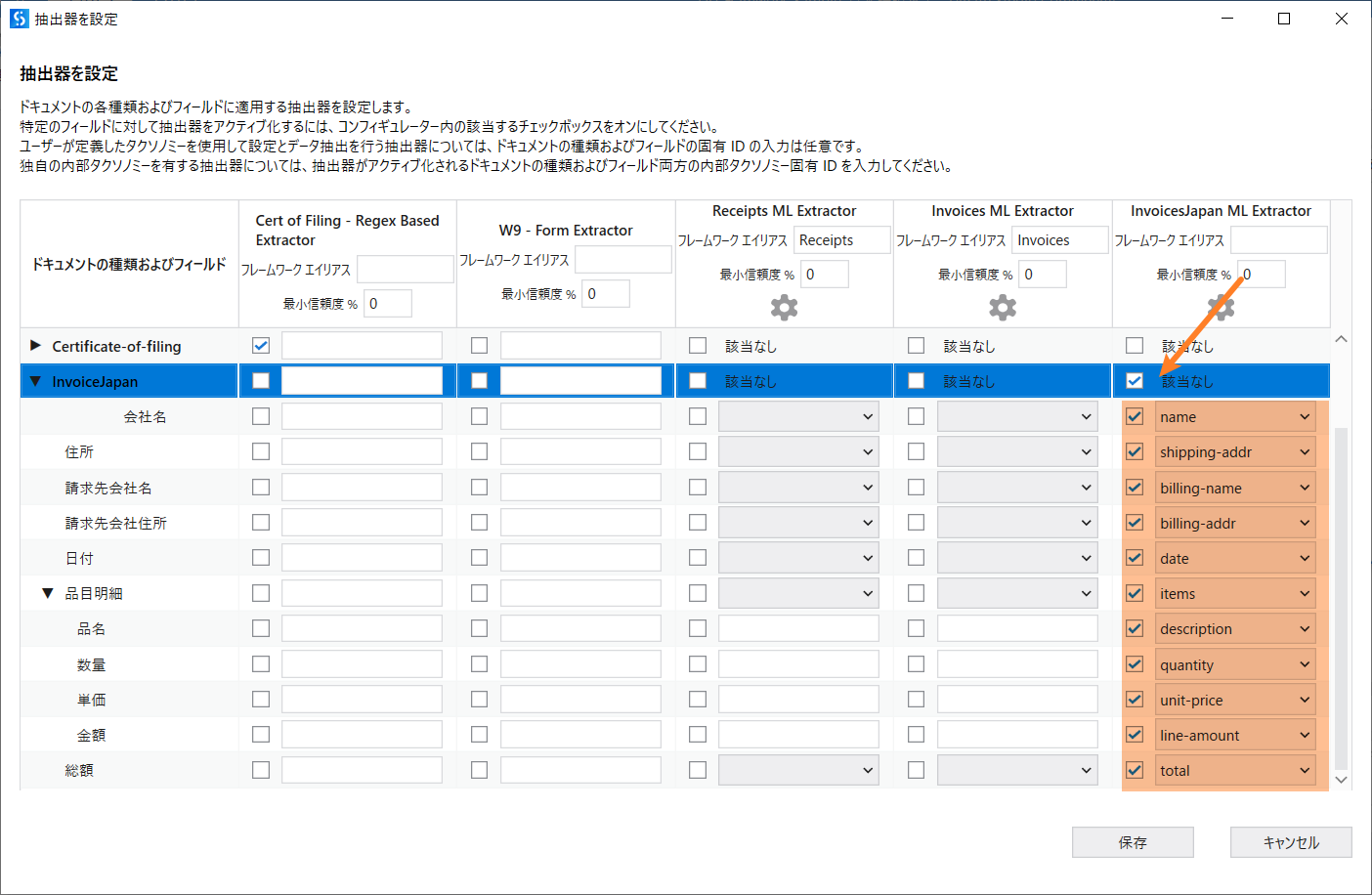
- 次に、抽出器を設定をクリックして、InvoiceJapanの利用抽出器をInvoiceJapan Extractorに指定して、それぞれフィールドの対応項目を選んで、保存してください。
-
InvoicesJapan ML Extractorアクティビティでの設定を以下の通りに変更します。
- エンドポイント:
in_Config("InvoicesEndpointJapan")(*日本語請求書のエンドポイントに変更) - APIキー:
in_Config("ApiKey")
- エンドポイント:
7. 分類器トレーナーの変更
タクソノミー定義が変更されたので、分類器トレーナーでの設定も変更する必要があります。
手順:
- 40_TrainClassifiers.xamlを開いて、[Train Classifiers Scope - Train Classifiers]アクティビティでの分類器を設定をクリックします。
- 今回のドキュメントの種類のInvoiceJapanもチェックに入れます。
8. 抽出器トレーナーの変更
日本語の請求書ですので、抽出器トレーナーも変更する必要があります。
手順:
- 60_TrainExtractors.xamlを開いて、[Train Extractors Scope - Train Extractors]アクティビティでの抽出器を設定をクリックします。
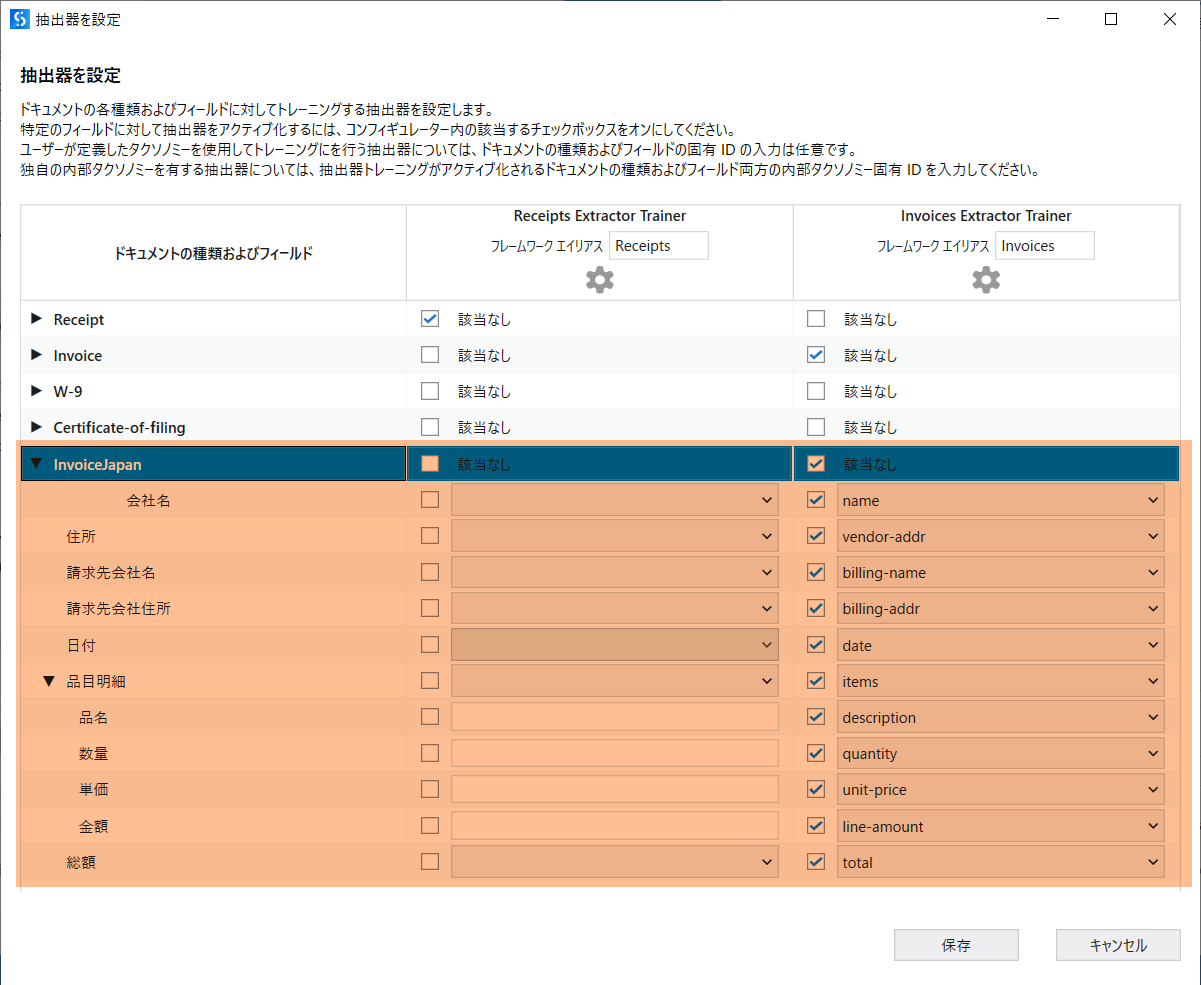
- 次の[抽出器を設定]画面に、[Invoices Extractor Trainer]下の歯車マークをクリックして、以下のを入力して、
- エンドポイント:https://du.uipath.com/ie/invoices_japan
機能を取得をクリックします。
- エンドポイント:https://du.uipath.com/ie/invoices_japan
- 次のように、請求書の設定をして、保存ボタンをクリックします。
9. 結果の確認
上記の設定変更で、日本語請求書の処理もできるようになりました。ワークフローを実行して、結果を確認してみましょう。
手順:
-
UiPath StudioでMain-Attended.xamlを開きます。
-
リボン欄での「ファイルを実行」を選んで実行します。
-
ファイル選択ダイアログが開いたら、事前準備でダウンロードしていた
\Data\ExampleDocuments\の日本語請求書PDF(例:Sample_Invoice_03.pdf)を選択してください。 -
しばらく実行したら、抽出結果の検証ステーションが表示され、抽出結果を確認します。
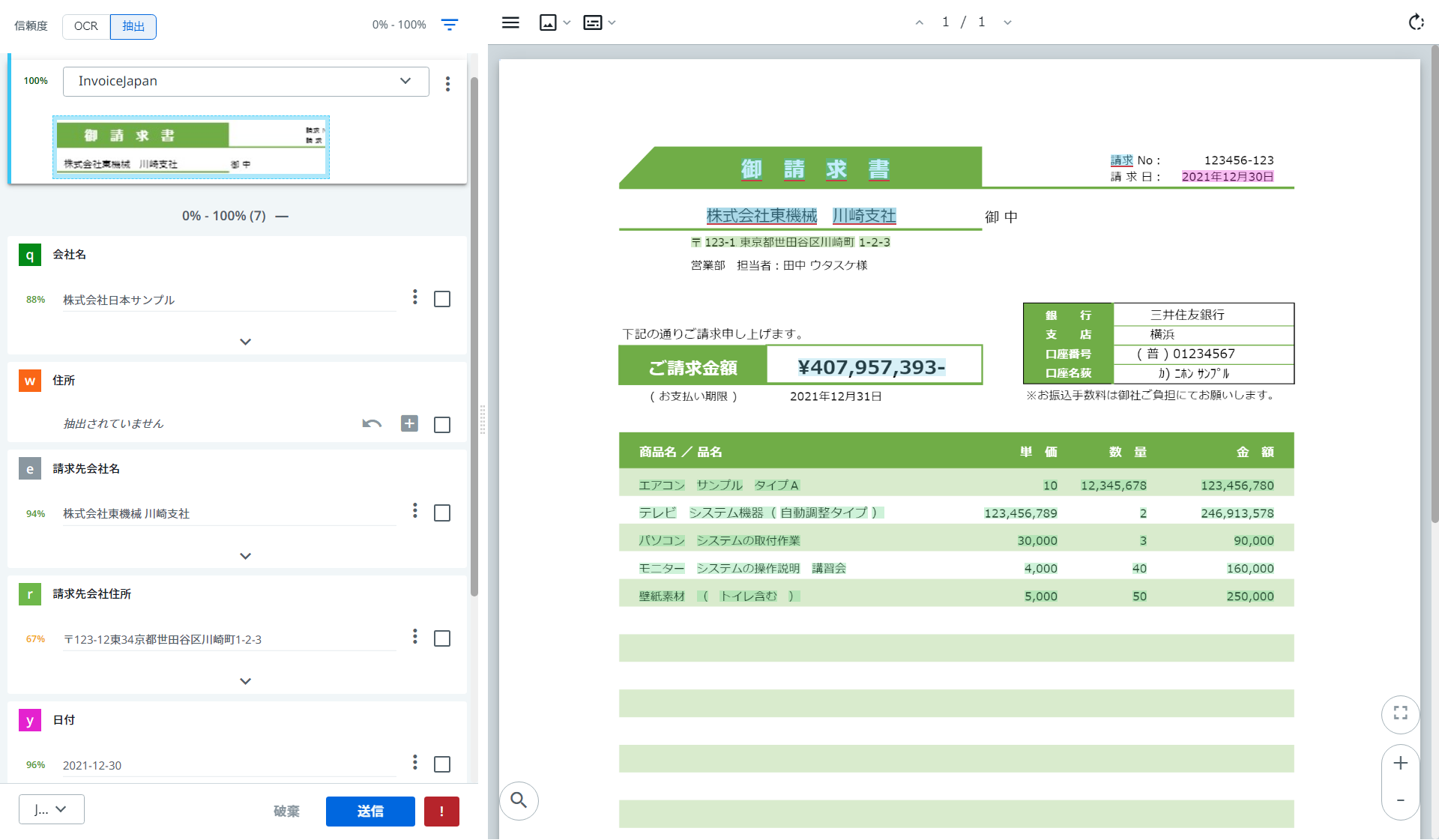
-
ドキュメントの分類や会社名、請求先会社の情報も正しく抽出されています。
-
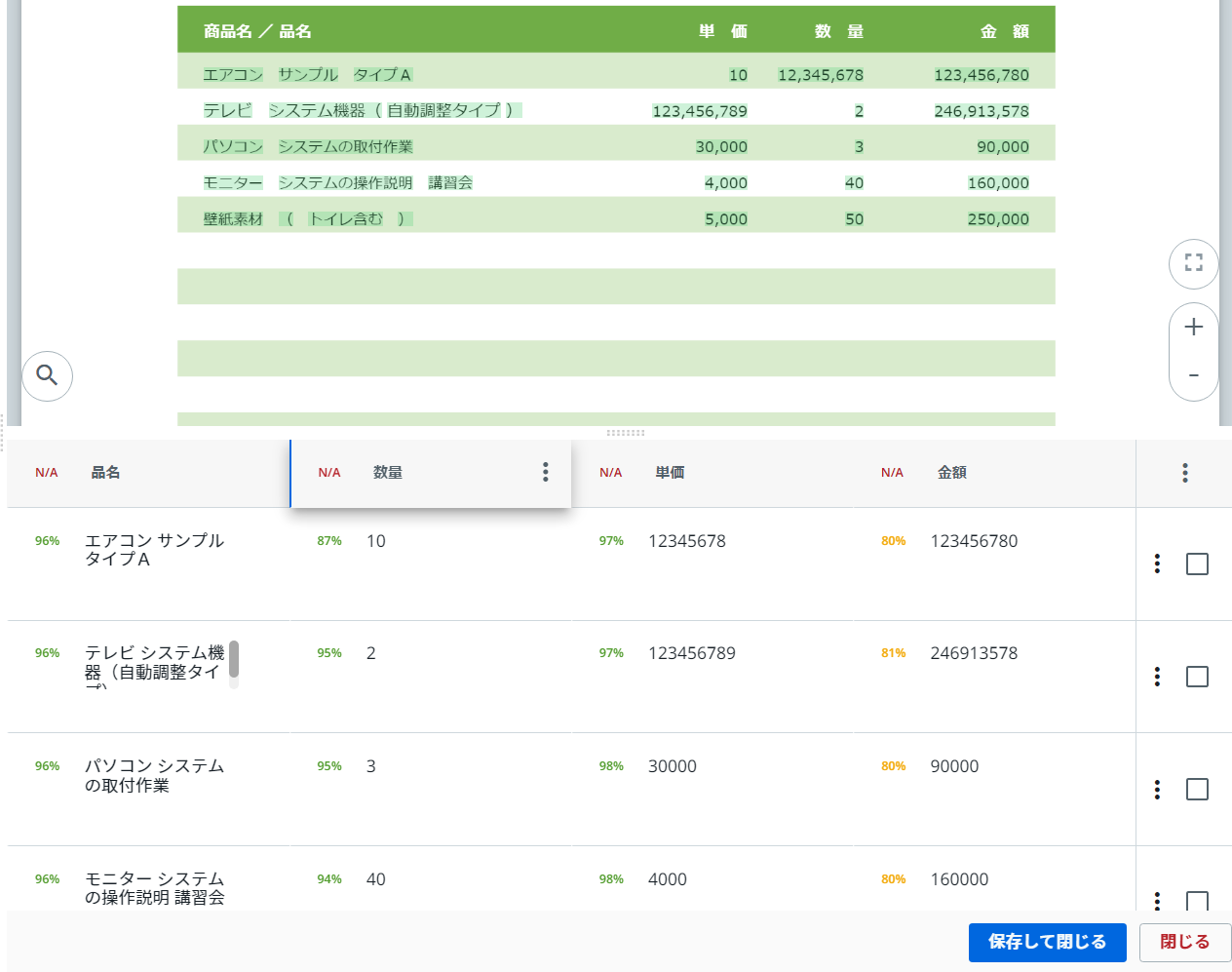
商品明細のテーブルには、行数が可変する項目が含まれていますが、それらが正しく抽出されています。
ご参考までに、ここまでのワークフローを02.Template利用_第五回_SampleWF_PDFに保存しています。
10. 終わりに
このワークフローを実行するたびに、ファイル選択ダイアログが表示され、PDFファイルを1つ選択して処理しています。
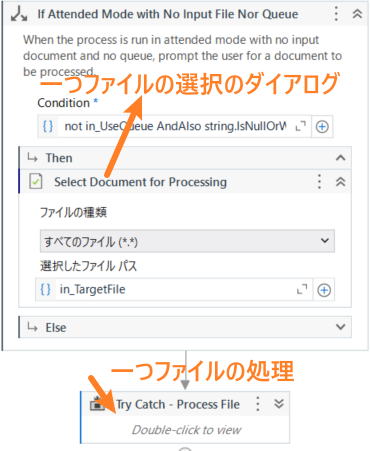
Main-Attended.xamlを改修して、1回の実行で複数のファイルを処理できるようにしてください。
次回では、テンプレートを利用して、無人オートメーションを実行する際に、どのような設定や修正が必要なのかを解説します。