ミクシィグループ Advent Calendar 2020 2日目の記事になります。
概要
Twitterで画像を投稿したときに「いい感じのところを勝手に表示してくれる」ことに少し前に気づいた。
あれ、Twitterの画像投稿のサムネって、、、いい感じのところだけ表示されるようになってるのか?知らなかった。すごい pic.twitter.com/U7Aa5Y54ZE
— 佐藤俊太郎 (@ushisantoasobu) September 26, 2020
どうやら結構前からの仕様のようで、それはそれで困っている人もいるようだが(例)、自分としては面白いなと思いつつ、WWDC 2019の"Understanding Images in Vision Framework"という動画に出てきた"Saliency"というものについて思い出し、いつか自分でもこういったことをやってみたいと思っていたので試してみた。
"Saliency"とは
"Understanding Images in Vision Framework"の"Saliency"について大雑把にまとめておくと、
- Saliency = 「顕著性」(という日本語が自分の中ではしっくりきた。他に調べた感じだと「突出」「特徴」など)
- Visionフレームワークで画像のSaliency(顕著)な領域を取得することができる
- Saliencyには2種類あって、「attension based」なものと「objectness based」なもの
- attension based = 人間の知覚に近いもの
- objectness based = 物体を分けるための機械的なもの
- Saliencyには2種類あって、「attension based」なものと「objectness based」なもの
以下、動画のスライドのスクショを用いて補足。

(↑ 「attension based」なもの(中央)と「objectness based」なもの(右)の違い。前者が「人の顔」を捉えているのに対して、後者は「人全体」を捉えている)

(↑ 「attension based」なもの(中央)だと、「人の動き」(歩こうとしている方向の空間)も捉えていることがわかる)

(↑ "Saliency"を利用したユースケースが2つ紹介されていた。「画像のフィルター」(上のスクショ)と「スライドショーのズームアニメーション("Saliency"の領域に寄っていく)」)
実装してみる
"attension based" or "objectness based"?
きっかけはTwitterの画像投稿ではあったが、現在自分が開発している「家族アルバム みてね」でよく耳にする問題 = 「人物が写った縦長の解像度の写真を正方形のサムネで表示したときに、その人物の顔が切れてしまって少し残念」といったような問題、これの改善ができないかとずっと思っていたが、であるならば"attension based"なものが良いだろうと思いこの記事では"attension based"を採用することにした。
サンプルコード
"Saliency"の領域を取得すること自体はかなり簡単に書ける(先の動画のサンプルコードのまま)。
let image = squareImageView.image
let handler = VNImageRequestHandler(cgImage: image!.cgImage!, options: [:])
let request: VNImageBasedRequest = VNGenerateAttentionBasedSaliencyImageRequest()
request.revision = VNGenerateAttentionBasedSaliencyImageRequestRevision1
try? handler.perform([request])
guard
let result = request.results?.first,
let observation = result as? VNSaliencyImageObservation
else {
fatalError("missing result")
}
guard let objects = observation.salientObjects else { return }
for object in objects {
print(object.boundingBox)
}
![]() 注意としては、最後の
注意としては、最後のobject.boundingBoxで取得できるCGRectの値の原点は「左下」であるということ(先の動画でも触れられている(下画像))
![]() 最近届いたMacbook Pro(M1チップ搭載)で意気揚々と動かしてみたが、なぜかこの
最近届いたMacbook Pro(M1チップ搭載)で意気揚々と動かしてみたが、なぜかこのboundingBoxが取得できなかった...XcodeのバージョンなのかMacOSのバージョンなのかなど何が原因かはわかっていないが残念

サンプルコードを動かしてみる
さて、実際にいくつかの画像で"attension based"な"Saliency"の領域がどのように取得できるのかみていくこととする
(以下自分の顔写真がたくさん出てきます。ウザい顔しているものもあると思うのですがご了承ください ![]() )。
)。
| 画像 | 補足・感想 |
|---|---|
 |
普通に顔の領域が取得できている(もちろんマスクも問題なし) |
 |
思ったより胴体も含まれている? |
 |
挙げた手も含まれている |
 |
歩く様子。先に話したWWDCの動画のように「人の動き」を含めた領域を取得できるかと思ったが、、、いくつか似たような画像で試したが、基本的には画像全体の領域が取得されるようだった |
 |
ただの景色でも試してみた。こちらも基本的には画像全体の領域が取得される |
 |
手前のホオズキにフォーカスして撮った写真だが、、、後ろの人(ボヤけているが)も含めた領域が取得されているようにも見える |
 |
人物(嫁)の領域だけが取得される想定だったが、、、後ろで光っている非常ドアなんかも含まれてそう? |
 |
二人の人物が写った写真だと、二人まとめた領域が取得されるぽい(emojiは最後に重ねたもの) |
 |
手と物体であればどちらが取得されるのだろうと思い試してみたが、どちらも含む領域が取得された |
 |
何か適当なオブジェクト |
 |
同上 |
画像一覧サムネに適用してみる
「人物が写った縦長の解像度の写真を正方形のサムネで表示したときに、その人物の顔が切れてしまって少し残念」
と先に書いたが、では実際にどのように改善(改悪の可能性もある)されるのか、「画像一覧サムネ」に適用して実験してみる。
なお、「取得したSaliencyの領域から、どのように画像を正方形に切り抜くか」のアルゴリズムはそれはそれで考えることが多く、ここではシンプルに以下のようにして切り抜くこととした。
- 取得したSaliencyの領域を、中心を変えずに正方形にする
- その正方形のwidth/heightが、元画像の短辺の80%よりも小さければそこまで拡大する
- 取得したSaliencyの領域が小さいときに「拡大されすぎてしまう」という問題を避けるため
- その結果、元画像の領域から外れてしまう場合は、外れないように調整してあげる
- それでもダメな場合は諦める(何も調整しない)
以下、beforeがいわゆる「.scaleAspectFill」でサムネイルを表示したもの、afterが「"Saliency"を利用し上のアルゴリズムで切り抜いて」サムネイルを表示したもの。
| before | after |
|---|---|
 |
 |
それぞれの元画像は以下のようなものになっている

いくつかの写真の表示領域が調整されていることがわかる。やってみての感想は、
- 顔が中心の方に来る
- サービスの要件次第では良さそう
- 悪い面としては、勝手に調整される分、どの画像のサムネなのかがわかりづらくなったこと
- そういった視点からも、今回は「画像一覧サムネ」に適用してみたが、サムネイルとかではなくそれ自体がコンテンツのもの、例えばWidgetなんかに適用してあげた方が有用なのかなと思った
最後の「Widgetなんかで有用なのでは」というのは、やってみるまであまり考えてなかったが、確かにAppleの「写真」アプリのWidgetって、、、似たように表示領域の調整をしているように見えるのだがどうなのだろうか?(下画像。明らかにただ「中央」を表示しているだけではない)
| 元画像 | Widget |
|---|---|
 |
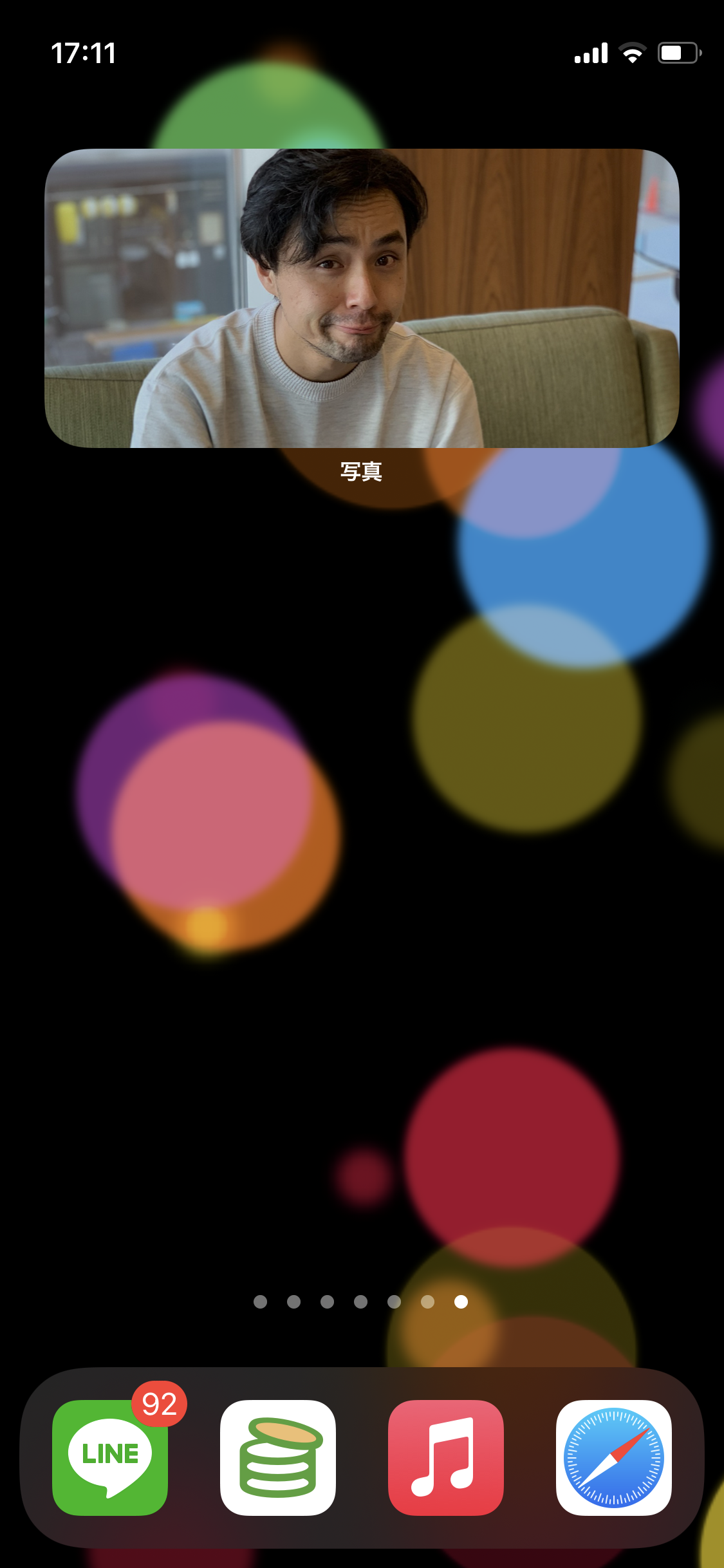 |
パフォーマンスはどうか?
"Saliency"の領域を取得する処理はパフォーマンスが気になるところ。
自分が計測してみた感じだと、
- 画像サイズ(= width * height)に等倍の処理時間がかかる
- なぜか初回はちょっとだけ時間がかかる(Vision側で何かセットアップみたいなコードが動いている?
 )
)
以下、初回以降の計測結果(iPhone XSにて実行。3回動かしてみての平均時間)。要件次第だが、十分実用的な数字だとは思う一方無視していい数字でもないなという印象。
| 画像サイズ(width, height) | かかった時間(sec) |
|---|---|
| (3024.0, 4032.0) | 0.4136 |
| (887.0, 1182.0) | 0.0383 |
まとめ
まあ本気でやろうと思ったら、バックエンドでこのような解析を行い、その結果をiOS/Androidなどで共有するのが普通かとは思います。
が、ちょっとしたユーザ改善なんかのために、VisionフレームワークなりMLまわりの技術をアプリ内で完結する形で今後利用できないかと考えていたので、今回のリサーチができたのは良かったかなと思った。