この記事はOpt Technologies Advent Calendar 2017の17日目です。
概要
11日の記事(Spark on EMRの基礎をおさらいする)にてSpark on EMRの構成はおさらいしましたが、トラブルシュートするためにはSparkの内部処理についても理解しておく必要がある、ということでまとめます。また本記事は上記記事を読んでいる方向けの内容となります。
(本記事は社内勉強会にて話した内容に修正を加えたものになります。)
Sparkの処理の内部構造
概要
Sparkはコードでそれと意識していなくても分散処理が出来るのが強みですが、内部的には割とややこしいことをしています。具体的には、「どのロジック・オブジェクトがどこで実行されているか。またそのデータはどこから渡ってきているか」です。
RDD
Sparkでは扱うデータをRDDと呼ばれるコレクションのような入れ物で管理しています。
一つ一つのデータのことをRecordと呼び、同一Executorで実行されるRecordの集合のことをPartitionと呼び、Partitionを合わせるとRDD本体となります。

例えば以下のような処理があるとすると、
object Hello {
def main(args: Array[String]): Unit = {
val num = 3
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val rdd = sc.range(0, 100, 1, 10)
val value = rdd.map(_ * num)
.reduce(_ + _)
value mustBe 110
}
}
まず、 sc.range(0, 100, 1, 10) のところで、0~9、10~19、20~29のそれぞれをRecordとする10個のPartitionが作られ、Partition単位でExecutor Nodeに配布されます。
次にmap処理のところで、Logicとして _ * num が配布されてExecutor上で実行されます。(この時、numの実体も一緒に配布されます。)
遅延評価
分散処理をするには、データだけでなくロジックも渡す必要があります。それを学ぶためにSparkの処理モデルを理解しましょう。
SparkはDAGを用いた遅延評価です。
どういうことかと言うと、mapなどの命令を受け取った段階ではまだ処理は行わず、RDDオブジェクトが消費される命令(collect/reduce のようにDriverに結果を集約するか、 saveAsTextFile のように出力するAPI)が呼ばれたら、そこで初めてこれまで溜めていたmap処理などを順番に実行していきます。(後述しますが、これをJobと呼びます。)
これは、処理のDAGを最後まで作ってみないと「どのようにリソースを割り当てたら効率が良いのか」を判定出来ないからです。また、リトライ時にどう巻き戻せば良いのかの情報にもなったりします。
処理の順番はこのようになります。
object Hello {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Simple Application") // 1
val sc = new SparkContext(conf) // 2
val rdd = sc.textFile("s3://opt-uryyyyyyy/spark/data/hello", 10) // 4
println("----Start----") // 3
rdd.map(_ * 2) // Executor // 4
.saveAsTextFile("s3://opt-uryyyyyyy/spark/data/hello") // 4
}
}
4が多いですが、これは処理が各Taskの中で並列に動くからです。
例をもう一つ
object Hello {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Simple Application") // 1
val sc = new SparkContext(conf) // 2
val rdd = sc.range(0, 100, 1, 10) // 4
println("----Start----") // 3
rdd.map(str => str.toInt).map(i => (i%20, i)) // 4
.groupByKey(20) // 5
.map{case (key, itr) => (key, itr.size)} // 5
.foreach{case (key, value) => println(s"key: ${key}, value:${value}")} // 5
}
}
groupByKeyまでの処理が1stage。その後で1stage(stageは後述)です。
stage内であれば、partitionそれぞれが並列で処理されますが、stageを跨ぐときには一度足並みを揃えて実行されます。
(上記の例だと、 map の処理は自分のPartitionだけで完結する処理ですが、 groupByKey は全PartitionのRecordを確認する必要があるからです)
以下にSparkのDAG Visualizerを載せますが、あるJobにおいてStageが分かれているのがわかるかと思います。

Job, Stage, Task
先ほどJob, Stageという単語を使いましたが、Sparkでは、RDDを消費するAPIを呼ぶと、その時点でのDAG自体をJobと呼び、Jobは複数のStage(reduceなどが入るとStageが分かれる)を含むものになります。ここで、Stageというのは関数オブジェクトと思ってもらえばよいです。
各Executorでは、渡ってきたPartition単位に区切られたデータと、Stageの関数を実行していきます。この単位をTaskと呼びます。
つまり、あるJob内のTask数は Partition数 * Stage数 ということになります。階層構造を図示すると以下のような形です。
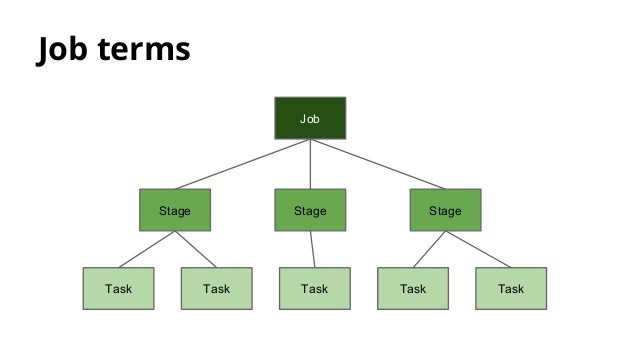
from: https://www.slideshare.net/javiersantospaniego/distributed-computing-with-spark
マシンをまたいだ挙動
ExecutorでDAGが生成され、RDDを消費するAPIが呼ばれるとJobが作られます。Jobが作られると、DriverはExecutorに処理(Jobの関数)を転送します。
普通のアプリケーションの場合は、DriverからExecutorへRDDのPartitionを渡すことはせず(Driverが抱えるデータが大きすぎるため)、ExecutorそれぞれがS3などからデータを取得してPartitionを生成し、Jobを実行します。

Executor内部の挙動

先ほどの図と説明で、Executorの中にPartitionと、Jobに含まれる各Stageの関数が渡ってきて、それをTaskとして実行します。繰り返しですが、StageにはLogicと、それに付随する変数が含まれます。(図右上)
ちなみに細かいことですが、SparkではBroadCastという機能とCacheという機能があります。
BroadCastについては、Taskの説明で述べたように、ロジックの中で何度も変数を転送するのは無駄なので、事前に各Executorにデータを配置してしまおうというAPIになります。メモリをずっと専有しますが、転送コストがかからず便利なことが多いです。(図左中央)
またCacheについてですが、RDDは無駄にメモリを食わないようにするために基本的には使い終わったらGCされます。複数Job/Stageで使いまわしたいデータであれば、Cacheに入れておいて再利用するのがよいでしょう。ただ、その分メモリを圧迫するため、シリアライズしてメモリ空間に配置したり、Diskに一時的に置いておいたりという実装を選ぶことも出来ます。(図左中央, 左上)
Executorのパラメータ調整
nums(Executorの個数), cores(Executorそれぞれに割り当てるcore数), memory(Executorそれぞれに割り当てるメモリ)といったパラメータがある。
numsを増やすと並列度は上がるので外部IOなどは効率的になるが、Taskに使えるメモリが減るのでGC頻発やOoMになりやすくなったりする。
memoryは、割り当てるのはあくまでYARNのRecourceManagerでの粒度なので、Sparkアプリが使えるメモリはそのうちの6割ほど
ApplicationMaster(Driver)もリソースを喰うことに注意(YARNのMasterNodeで実行されるわけではない)

from: https://spark.apache.org/docs/2.2.0/tuning.html#memory-management-overview
from: https://github.com/AllenFang/spark-overflow/blob/master/README.md
どこがボトルネックになりやすいか
Sparkで言うと、
- 外部IO
- Executor間のIO(shuffle)
- キャッシュ時にディスクに書き込むか(Disk I/O、Serializeなど)
どこでハマりやすいか
データがどこにあるかを意識する
- RDDを全部DriverNodeに持ってきてしまいOoM/他Node遊んでる
- Taskの中にSerializableでないものが混じっててエラー
- コネクションなどはpartition毎に貼るのが無難
- 偏ったKeyでAggregateしてしまい、特定のPartitionだけOoM
- Partitionの数が少ないとメモリ枯渇しやすく、多いとshuffleのコストが高い
- 一部のノードだけ負荷が高く、他が遊んでいる
- 上記と同じく、データが偏っているため起きる
- Driverだけ負荷が高い場合、分散処理以外で詰まってる可能性がある