この記事はOpt Technologies Advent Calendar 2017の11日目です。
概要
EMR、Hadoop、Sparkそれぞれの関係を、試しに動かしてみたりドキュメントに当たることで理解する。
それによって、何が起きているのかをログやメトリクスから把握できるようになることを目指します。
(社内勉強会にて話した内容に修正を加えたものになります。)
まず動かしてみる
何はともあれ動かせる状態にします。これをベースに色々実装を変えてSparkに慣れましょう。
最小構成
以前書いた記事はこちら
今回試してみるコードはこちら
Localで動かす
- Sparkのバイナリをダウンロードしてくる
- アプリのassembly-jarを作る
sbt batch_helloWorld/assembly
- spark-submitで実行する
spark-2.2.0-bin-hadoop2.7/bin/spark-submit --master local[2] --class com.github.uryyyyyyy.spark.batch.helloworld.Hello batch_helloWorld/target/scala-2.11/batch_helloWorld-assembly-1.0.jar
EMRで動かす
EMRクラスタを用意する
特筆することはないのですが、Spark(やメトリクス取得のためのGanglia)を各種バージョンを確認しつつ入れておき、
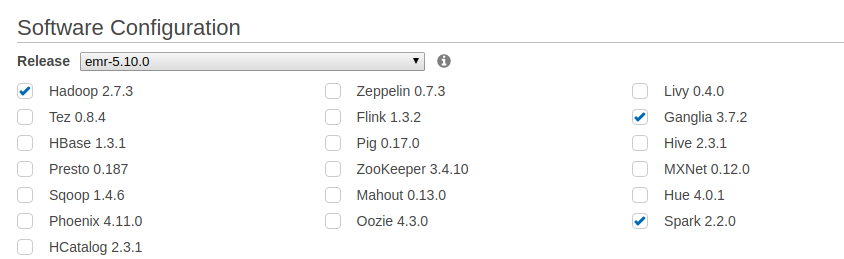
Web UIやSSHログインするためのSecurity Groupが空いているとなお良いです。
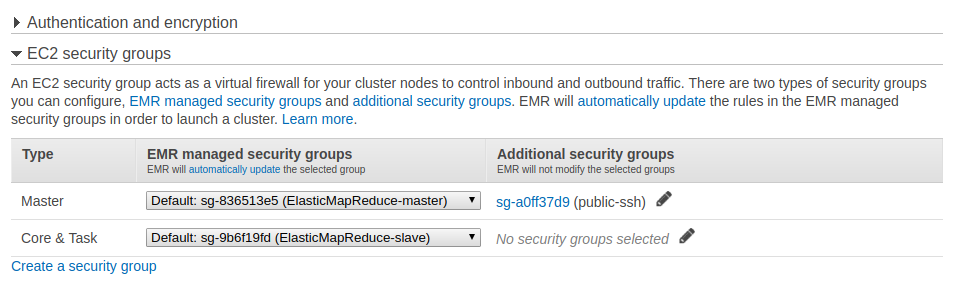
EMR上で動かしてみる
以前書いた記事はこちら。
先ほど、ローカルでの動作確認に使用したJarをS3にアップして、Main Classを指定してあげると良いでしょう。
ローカルでのUnitTest
特に変わったことはなく、普通にSpark起動するだけです。
https://github.com/uryyyyyyy/sparkSample/blob/master/batch_helloWorld/src/test/scala/HelloSpec.scala
RDDのままだと分散していて比較出来ないので、最終的にはファイルに吐き出すか collect処理をしてからassertする事になると思います。
...
ここまでで、とりあえず動かしてみることは出来ました。
EMRでの全体像を理解する
ここから、EMRとSparkの関係について述べていこうと思います。座学です。
全体の関係性を一言でまとめると、「EMR管理下のHadoopクラスタ(YARN)上で、Sparkアプリケーションを実行している」という形になります。
EMR
HadoopクラスタのSaaSです。どんなHadoop系アプリ(Spark、Ganglia)、クラスタのサイズはどうするか、Jobの投入や成功失敗はどうか、などの機能を提供してくれます。
Hadoop
Hadoopは分散処理フレームワークです。
分散処理をするためには、「並列で実行するためのコンピューティングリソース」だけでは不十分で、入力・出力が効率良く出来るファイルシステムが必要になります。
- コンピューティングリソースを管理するミドルウェア→YARN
- 分散ファイルシステム→HDFS
- (YARNの前身もありますが今や使われてないので割愛)
という関係性になります。
なお、クラウド環境であればS3、GCSという分散ファイルシステムが既にあるので、HDFSは使わないでそちらを使うのが一般的です。
(EMRはHA構成は出来ないので、Masterが死んだらクラスタごと死にます。この点でも永続化したいデータはS3に置き、クラスタはなるべくステートレスにしましょう。)
Spark
「分散コンピューティング環境」上で動作する分散処理フレームワークです。
分散コンピューティング環境には、mesosやYARN、StandAlone(Spark自体のクラスタ構成)が含まれますが、EMRにおいては「YARN上で実行される」ということになります。
もう少し詳しく
YARN
仕組みはこんな感じです。

from: https://jp.hortonworks.com/blog/apache-hadoop-yarn-concepts-and-applications/
まず、Resource Manager(Master)とNode Manager(Node)というプロセスがそれぞれ立っています。
MasterがJobのリクエストを受け取ったら、クラスタ上のどこかにApplication Masterを置いて、そのJobを実行します。
Application Masterは必要に応じてResource Managerへリソースを要求し、それがContainerとしてあてがわれるので、処理の一部をそこにやらせたりします。
クライアントからリクエストされてApplication Masterに割り当てられるタスクにはApplicationIDが振られ、それぞれのcontainerもContainerIDが振られます。
例)
- ApplicationID:
application_10000032000_0001 - ContainerID:
container_10000032000_0001_02_000001- IDの中にApplicationIDを含んでいることが分かる。
- ContainerIDは、ApplicationIDによらずクラスタ内でユニークになります。
ログは、${Container ID}/${stdout/stderr} のような形でログとして保存されていきます。
詳しくはこちら → EMRのログをS3/Localから追う
YARNのWeb UIを見ると、全体像としては以下のようになっていて、
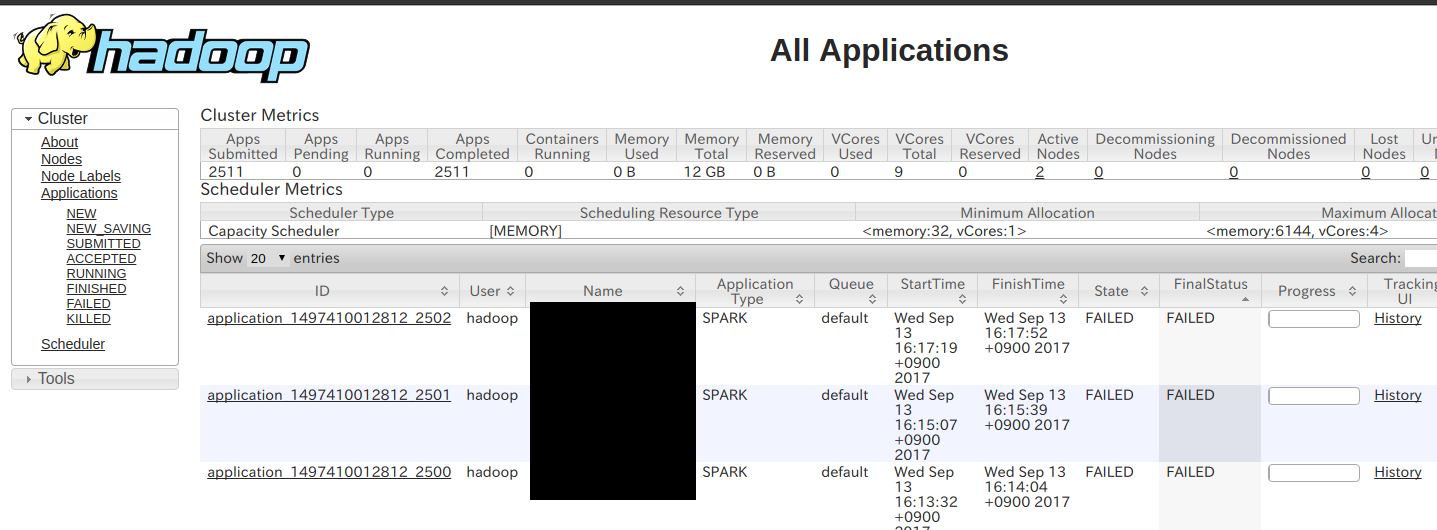
ApplicationIDを選ぶと以下のように
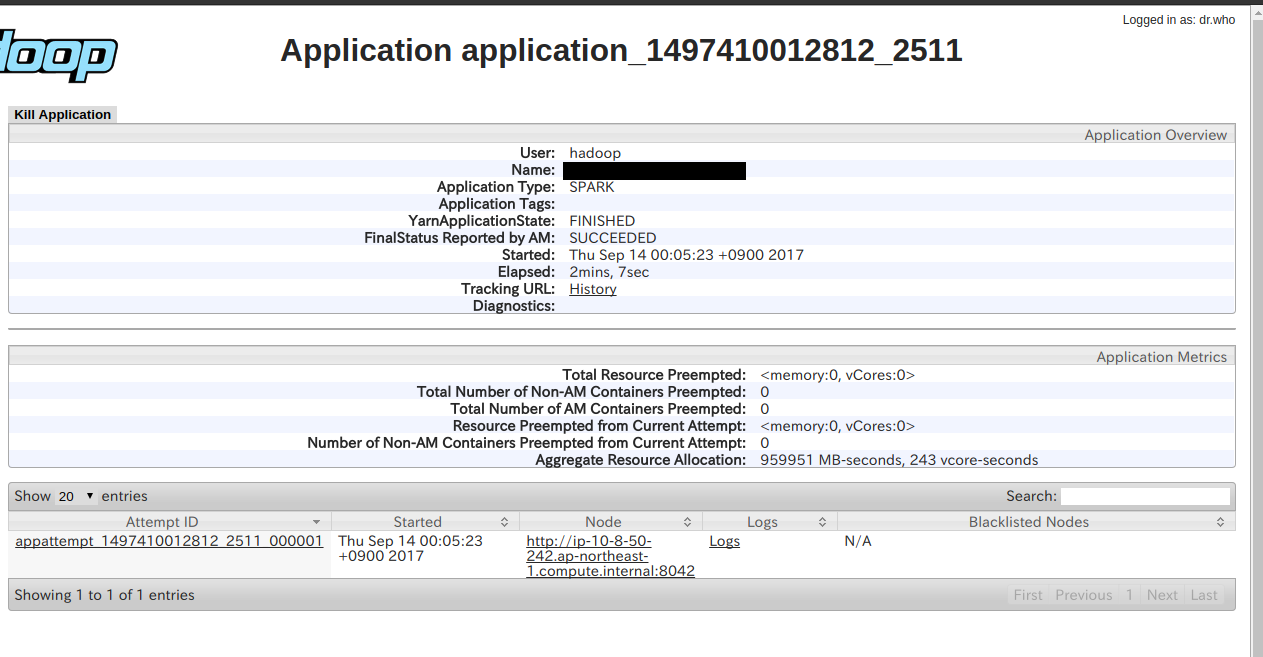
さらにログを見ると以下のようなUIになります。URLを見ると、どのContainerIDのログを見ているのかがわかりますね。

Spark
Sparkのみの全体像
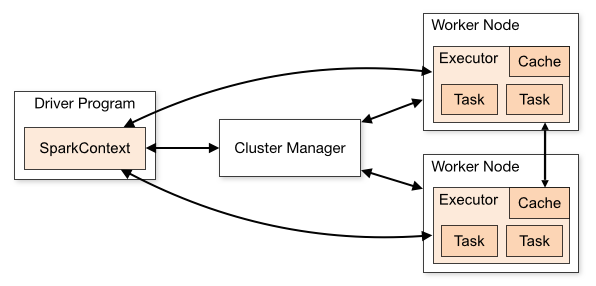
from: https://blog.cloudera.com/blog/2014/05/apache-spark-resource-management-and-yarn-app-models/
Driver Program(Master)、Executor Program(Node)という構成になっています。
すごくザックリ言うと、map的な記述の中はExecutor Program、その他全て(データを用意したり、処理の結果を待ったり)はDriver Program、という感じです。
サンプルプログラムを例に取って追ってみましょう。
(コメントにDriver, Executorのあるのが、それぞれ該当行のコードがどちらで実行されているかを示しています。)
object Hello {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Simple Application") // Driver
val sc = new SparkContext(conf) // Driver
val rdd = sc.range(0, 100, 1, 10) // DriverからExecutorに配布
val value = rdd.map(_ * 2) // Executor
.reduce(_ + _) // Executorから集約されていってDriverに返ってくる
value mustBe 110 // Driver
}
}
object Hello {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Simple Application") // Driver
val sc = new SparkContext(conf) // Driver
val rdd = sc.textFile("s3://opt-uryyyyyyy/spark/data/hello", 10) // DriverがExecutorに「ファイル取ってこい」と指示
println("----Start----") // Driver
rdd.map(_ * 2) // Executor
.saveAsTextFile("s3://opt-uryyyyyyy/spark/data/hello") // Executor
}
}
なお生ログについては、EMRでは実体がYARNなので、普通のYARNと同じようにContainer(Executor/Driver Node)毎に保存されます。(例えば、Driver側で吐かれたログはDriverが動いているコンテナ上に吐かれます。)
以下の図では、driverと書かれているところの右に stdout , stderr とありますが、ここをクリックすると、先ほど見たようなYARNのログに画面に飛ぶことが出来ます。

Spark on YARN
Sparkのclusterモードにおいては、Application MasterでDriver Programが動き、他Container上でExecutor Programが動きます。

from: https://blog.cloudera.com/blog/2014/05/apache-spark-resource-management-and-yarn-app-models/
同じ構成ですが、AWSの方で提供されている図も合わせて見てみましょう。
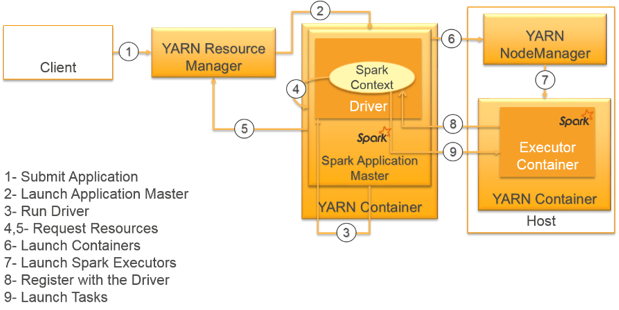
from: https://aws.amazon.com/blogs/big-data/submitting-user-applications-with-spark-submit/
まず、YARNのResource Managerにjobがsubmitされます。
Application Masterがjobを実行するので、そこがDriver Programになります。
Driver Programは、RDDを作るときにリソースをResource Managerに要求して、Containerが割り当てられたらそれをExecutor Programとして分散処理をします。
結果は分散ファイルシステム(S3とか)に置いても良いし、Driverに集約して残りの処理をしても良いです。
以下はSparkのHistoryServerのWeb UIですが、App IDがあるのが見えるでしょうか?これはEMRではYARNのApplicationIDです。

Tips
Web UIへのアクセス
Web UIはpublicアクセスを許可しないのが一般的です。(ログなども見れてしまうため)
ただ、ブラウザから見たほうが都合が良いことが多いです。
そこでプロキシを経由します。やり方は以下の通り。
ファイルの入出力
Hadoop上で動くアプリは、基本的にはクラスタ内部のHDFSに出力されることを想定しています。
それ以外に吐き出す場合は、それ用のアダプタと、その設定(もちろん認証情報も)が必要です。
S3は、EMRではデフォルトでアダプタとその設定が入っています。権限もEC2のものを使うことは出来ます。
アダプタとしては公開されてなかったはずですがこちら。 /usr/lib/hadoop-mapreduce/hadoop-aws-2.7.3-amzn-5.jar
設定としては、EMRクラスタの各ノードにある /etc/hadoop/conf/core-site.xml にある
<property>
<name>fs.s3.impl</name>
<value>com.amazon.ws.emr.hadoop.fs.EmrFileSystem</value>
</property>
このあたりの記述です。
GCSに繋ぐためには、アダプタをjarに同梱 or 配布する必要があるのと、設定を記述する必要があります。また、credentialのjsonを各ノードに配置も必要です。
僕が書いたものではないですが、こちらの資料が詳しいです。
Spark on EMRからGoogle Cloud Storageに接続する
ローカル/テスト時とクラスタ上での違い
- ローカルでは1JVMプロセス、クラスタでは複数JVMプロセス
- データのシリアライズ周りで挙動が違ったりする
- ネットワークなど色んな要因でエラーになるので、リトライ可能の徹底を
- ローカルとクラスタで、各種jarが異なったりする
- S3接続のモジュールなどはEMRでは微妙に挙動が違った
- データサイズ
- データサイズが増えたりデータの偏りなどで、本番のみトラブるとかよくある
クラスタのメトリクス可視化
Gangliaは、Hadoopクラスタの物理的なメトリクスを収集します。
アプリケーション内部のメトリクスはSparkが蓄積しますが、Spark側で検知出来ないトラブルが起きていると、だいたいこちらで追えます。また、ボトルネックの特定にも役立ちます。
よくある使い方
- なんか処理が遅い
- CPUが振り切っている場合
- SparkのロジックでCPUバウンドである
- GCの処理が支配的になっている
- ネットワークのスループットがやたら高い
- shuffleするデータが大きい/回数が多い可能性。
- データサイズを小さくしてからreduceなど出来ないか検討
- 一部のノードだけ負荷が高く、他が遊んでいる
- データの分散が上手くいってない
- Driver Nodeだけ負荷が高い場合、分散処理以外で詰まってる
- CPUが振り切っている場合
- 急にYARNにkillされててアプリのログがほぼない
- だいたいメモリ食い過ぎでYARNに殺されてる。メモリ使用量を見る
Web UIはこのような形です。物理Nodeごとに各種メトリクスを追うことが出来ます。
