回帰
(線形)単回帰モデル
1種類のデータから1種類の予測値を出力するモデルです。
入力データを$$x=(x_1, x_2, \cdots, x_n)$$、出力データを$$y=(y_1, y_2, \cdots, y_n)$$とするとき、モデルを最もよく表している__直線$$y=wx+b$$の傾き$w$と切片$b$を決めます。
$w$を__重み、$b$を__バイアス__といいます。
実際のデータとモデル($y=wx+b$)の間には誤差があるので、その誤差を
$$\varepsilon=(\varepsilon_1, \varepsilon_2,\cdots , \varepsilon_n)$$とします。このとき、各教師データについて
y_i = wx_i+b+\varepsilon_i
が成り立ちます。
モデルを最もよく表しているとは、適切な__損失関数__(例えば、二乗和誤差)を決め、モデル(直線の式)がそれを最小にするようなときにいいます。
損失関数$L(w,b)$を二乗和誤差(残差平方和ともいう)
L(w, b):=\sum_{i=1}^n \{y_i-(wx_i+b)\}^2
にすると、$$L(w,b)=\sum_{i=1}^n\varepsilon_i^2$$すなわち誤差の二乗和となっていることが分かります。場合によっては、(1/2)倍します(微分すると係数が1にできるため)。
詳細は省きますが、$L(w,b)$を$w, b$それぞれで偏微分した式$=0$を解くことで、$w, b$を求めることができます。
b = \bar{y}-w\bar{x}, \ w=\frac{Cov(x, y)}{Var(x)}=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^n(x_i-\bar{x})}
ここで、$\bar{x}$は$x$の平均、$Var(x)$は$x$の分散、$Cov(x, y)$は$x$と$y$の共分散を表しています。
特に、この$(w, b)$の元で
\begin{eqnarray}
&&y=wx+b=wx+(\bar{y}-w\bar{x})=\bar{y}+w(x-\bar{x})\\
&\Leftrightarrow& y-\bar{y}=w(x-\bar{x})
\end{eqnarray}
より、回帰直線は観測データの標本平均$(\bar{x}, \bar{y})$を通ります。
実装
Pythonで自力で実装&sklearnのlinear_modelのLinearRegressionモデルを用いた実装をしてみます。
なお、再現性のために乱数シードを設定しています。
まずは必要なライブラリをインポート。
import numpy as np
import matplotlib.pyplot as plt
from numpy.random import randn
次に、線形回帰を関数として定義。
def LinearRegression(x, y):
n = len(x)
temp_x = x.sum()/n
temp_y = y.sum()/n
w = ((x-temp_x)*(y-temp_y)).sum()/((x-temp_x)**2).sum()
b = temp_y - w * temp_x
return w, b
そして、教師データとして、$y=x+1+noise$を想定。$noise$は適当に標準正規分布に従う乱数に0.1をかけたものとしました。
# initial value
# y=x+1にノイズを加えたものを想定
x = np.array([1,2,3,4,5])
np.random.seed(seed=0)
y = np.array([2,3,4,5,6])+np.random.randn(5)*0.1
print(y)
w, b = LinearRegression(x, y)
print(w, b)
これを実行すると、およそ$w=1.02, b=1.08$と求まります。
念のため、グラフで可視化します。
plt.scatter(x, y, color="k")
xx = np.linspace(0, 5, 50)
yy = xx * w + b
plt.plot(xx, yy)
plt.show()

いい感じですね!
ちょっとコードを使いやすいように書き換える
クラスを使ってコードを書き換えて見ます。
modelというクラスを作り、パラメータを求めるfitメソッド、予測を出力するpredictメソッド、決定係数を計算するscoreメソッドを作りました。決定係数$R^2$は、1に近いほど精度がよいということです。
R^2:= 1-\frac{\sum_{i=1}^n (y_i-(wx_i+b))^2}{\sum_{i=1}^n (y_i-\bar{y})^2}
と定義されます。
class model():
def fit(self, X, y):
n = len(X)
temp_X = X.sum()/n
temp_y = y.sum()/n
self.w = ((X-temp_X)*(y-temp_y)).sum()/((X-temp_X)**2).sum()
self.b = temp_y - self.w * temp_X
def predict(self, X):
return self.w*X +self.b
def score(self, X, y):
n = len(X)
return 1 - ((y-(self.w*X+self.b))**2).sum() / ((y-y.sum()/n)**2).sum()
先ほどと同じように、教師データを入力します。
加えて、テストもさせてみます。
X = np.array([1,2,3,4,5])
np.random.seed(seed=0)
y = np.array([2,3,4,5,6])+np.random.randn(5)*0.1
lr = model()
lr.fit(X, y)
print("w, b={}, {}".format(w, b))
# テストデータ
test_X = np.array([6,7,8,9,10])
pre = lr.predict(test_X)
print(pre)
# 決定係数R^2
print(lr.score(X, y))
グラフ化します。
# 結果をグラフに表示
plt.scatter(X, y, color="k")
plt.scatter(test_X, pre, color="r")
xx = np.linspace(0, 10, 50)
yy = xx * w + b
plt.plot(xx, yy)
plt.show()

sklearnのライブラリを利用する
最後に、linear_modelの線形回帰LinearRegression()を用いて簡単にコードを書いてみましょう。
from sklearn import linear_model
X = np.array([1,2,3,4,5])
np.random.seed(seed=0)
y = np.array([2,3,4,5,6])+np.random.randn(5)*0.1
X = X.reshape(-1,1)
model = linear_model.LinearRegression()
model.fit(X, y)
print(model.coef_[0])
print(model.intercept_)
# 決定係数R^2
print(model.score(X, y))
$w$はcoef_[0]、$b$はintercept_に相当します。値が一致していることがわかると思います。ここで注意する点は、1次元の入力データの場合は$X=np.array([[1],[2],[3],[4],[5]])$のように入力する必要があります。$X=np.array([1,2,3,4,5])$だとエラーを吐きます。
次に、先ほどのテストデータで予測をしてみます。
test_X = test_X.reshape(-1,1)
pre = model.predict(test_X)
グラフ化します。
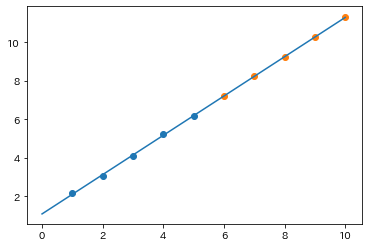
plt.scatter(X, y)
plt.scatter(test_X, pre)
plt.plot(xx, model.coef_[0]*xx+model.intercept_)
plt.show()
まとめ
sklearnを用いてコードを書くと、簡単に次のようにかけます。これは、他の手法でもほぼ同様の形でかけます。あとはパラメータであったり、教師データを訓練データとテストデータに分けるなどオプション的な要素が加わるだけです。
# モデルを定義
model = linear_model.LinearRegression()
# 学習(X:入力データ、y:正解ラベル)
model.fit(X, y)
# 予測(XX:未知のデータ)
model.predict(XX)
単回帰(最小二乗法)は以上です。
次回に続く。。。
追記
よく考えると、$b=(b, b, \cdots, b)\in \mathbf{\mathrm{R}}^n$とすべきでしたね。Pythonコードではブロードキャストのおかげでスカラー$b$としてもベクトルや行列との和は自動的に計算できます。
追記その2
from sklearn import linear_model
としてますが、
from sklearn.linear_model import LinearRegression
の方が楽ですね。他の書籍でもこちらが一般的かと。
参考文献
- 加藤公一『機械学習のエッセンス』SB Creative、2019年