はじめに
以前、EC2で直接動かしていたCrawlerをECSに移行した話という記事を書いたのだが、このCrawlerが遅いため、高速化したかった。
遅かった原因は、ECSで使用するEC2インスタンスをケチっていたからなので、EC2インスタンスを増やして実行させるコンテナを増やせば解決する話ではあるのだ。
が、趣味で動かしているCrawlerにお金をかけたくないという貧乏性から、コストをかけずにリソース的な制約から開放され、スケーラブルなServerlessCrawlerを作ることを目指そうと思う。
本投稿は、サーバレスでスケーラブルなCrawlerの構想を練るための記事である。
まだ、実装してないので、こうした方が良いんじゃないっていうアドバイス募集しております。
※ 実際に動いているわけではないことに注意
構成図
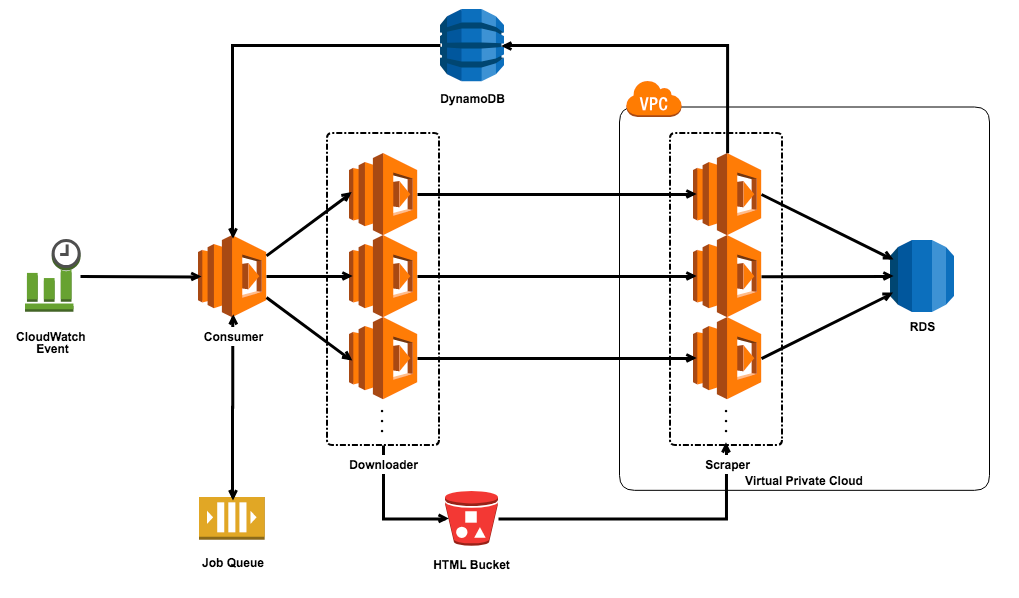
Serverless Crawlerの構成図はこんな感じ。
各コンポーネントの役割
Event Source (CloudWatch Event)
Consumerを呼び出すEvent Source。
CloudWatch Eventを使用して、一定間隔でConsumerを呼び出す役割を持つ。
Requst Queue (SQS)
ConsumerがポーリングするQueue。
Queueの中には、Request Blockのkeyが入っている。
2回実行されることを割けるために、FIFO Queueを使用する。
Consumer (Lambda Function)
Event Sourceから呼び出され、Request Queueをポーリングする。
Request BlockからRequestデータを取り出し、Downloaderを呼び出す役割。
Downloaderの同時実行数も制御する。
Downloader (Lambda Function)
Consumerから送られたURLに対してリクエストを送り、取得したHTMLをS3に保存し、Scraperを呼び出す役割。
可能な限り同時にリクエストが送ることができるようにする。
Scraper (Lambda Function)
S3からHTMLを取得して、スクレイピングし、RDSに保存する役割。
新たにクローリングするページがあれば、DynamoDBに追加する。
HTML Bucket (S3)
Downloaderが保存したHTMLドキュメントを保存するS3 Bucket。
Request Block (DynamoDB)
Consumerが読むRequestが格納されているDynamoDBのテーブル。
うまいこと使えば、無料で使えるので、DynamoDBを選択。
Tableの中には、DownloaderやScraperで使う情報が入っている。
Serverless Crawlerでは、別ドメインのリクエストは同時並列に実行したいので、DynamoDBの1行には、別ドメインのURLがリスト形式で格納されている。
データの形式はこんな感じ。
"key": "Number",
"next": "Number",
"requests": [
{
"url": "String",
"downloader": "String",
"scraper": {
"type": "String",
"id": "Number",
},
"option": "Map"
},
...
]}
keyはHash Keyで、SQSのQueueにはこれらのkeyの値が入っている予定。
ただ、Queueにkeyをpushする必要があり、sendMessageBatchでも最大10メッセージしかpushできないので、それをサーバレスで実現するのはコスト的にも見合いそうになさそうだったので、nextカラムを追加して、次のkeyの値を格納しておくことにする。
Consumerでnextの値をQueueにpushして、nextの値がnullになるまでConsumerを呼び出すようにしたい。
処理の流れ
DynamoDBには、既にデータが格納されている前提で。
- CloudWatch Event
- 10~30秒に一度ConsumerのLambda Functionを呼び出す
- Consumerを呼び出す間隔が、同じドメインにリクエストを送る間隔になる
- 10~30秒に一度ConsumerのLambda Functionを呼び出す
- Consumer (Lambda Function)
- Queueからデータを取得
-
1.で取得したデータを元に、DynamoDBからリクエストの内容を取得する -
2.で取得したリクエスト内容をParseする- AnguerとかReactで書かれたサイトと、単純なサイトを分割
- Downloaderのタイプで分割
- 一つのDownloaderで実行させるJobの数でrequestsを分割
- AnguerとかReactで書かれたサイトと、単純なサイトを分割
-
3.でparseした分、Downloaderをinvoke - nextの値をQueueにpush
- Downloader (Lambda Function)
- Consumerから受け取った値からDownloaderを生成
- 並列処理でリクエストを送る
- Nodeで書けば、Non Blocking IOなので、並列処理書きやすいはず
- Downloadが完了したら、s3に保存
- Scraperをinvoke
- s3のputイベントでLambdaを呼び出す事ができるが、Scrapeに必要な情報を送るために、Lambdaからinvokeする
{ "key": "String", "scraper": "Map", "option": "Map" }
- Scraper (Lambda Function)
- Downloaderから受け取った情報を元に、s3からhtmlを取得
- Downloaderから受け取った情報を元に、Scraperを生成
- スクレイピングを実行
- スクレイピングしたデータをRDSに保存
- 新しくScrapingする必要のあるページが出てきた場合は、DynamoDBに追加する
- 既にDynamoDBに追加されている場合は、追加しない
おわりに
一旦頭の中の構想を書き出してみたが、SQSあたりは微妙感がある。
SQSを使っている理由は、DynamoDBを一定間隔で、順番に実行したかったためだけである。
CloudWatch Eventで呼び指す時に、インクリメントされる何らかの値を渡せたらSQSは必要無いのかもしれない。
あとは、RDSに保存しているところも、完全にサーバレスにするのであれば、DynamoDBにしたいところであるが、テーブル設計をやり直すのが結構コストだったのと、DynamoDBの無料枠は超えそうだったので、そのままRDSを使うことにした。
後はこれを実際に作るだけ![]()