はじめに
以前の記事でGraylogを試してみた理由としては、実は色々な意味があった。
- 運用を今後考えるとLog監視だけでなく、分析とかって必要になるのかも?(監視だけならZabbixとかでも可能だが分析も必要となると…)
- 実はElasticsearchはずっと知りたかったけど、よくわかっていないのに単体で触って理解できるのか?(Graylogを触ったから理解するかは微妙だがきっかけとして)
- Log監視/分析のPaaSと比較して高くなるのか?(分析ってPaaSであるっけ?)
- 単純にLog監視/分析系のOSSを触ってみたい。(ちょっと理解したら次はELK Stackか…)
今回の記事は自身の備忘録として、上記の2について簡単にだがまとめておきたいと思う。特にGraylog初期インストール時にElasticsearchとしてはどういう設定なのか。マニュアル通りにインストールしただけではあまり理解できていないため、まとめながら落とし込んでいく。(本当に今更だし間違っている事が多々あるかと思うが…)
また、今回は基本的な構成の理解が主になる。(今後、GraylogがElasticsearchに対して内部でやっていることについて理解していきたい)
Graylogの構成のおさらい
公式マニュアルにGraylogの基本構成と大規模構成が記載されているので参考までに読む。(Deep DiveのURLもマニュアルには記載有)
Elasticsearchの基本構成
- Cluster:Nodeの集合体。
- Node:Elasticsearch Server。性能分散等はこのNodeを増やして対応する。
- Index:Databaseみたいなもの。
- Type:Tableみたいなもの。 ← Elasticsearch 6.xから1つのIndexに1つのTypeとなったらしい。今後のロードマップではこのType自体も削除するらしいため、ここではもう触れない。
- Shard:Indexに対しての物理的な分散。(RAIDみたいな感じ)
と、超ざっくり書くとこのように分かれているらしい。このようなレベルでさえ知らない自身が恐ろしい。。
GraylogのCluster
これは、インストール時の/etc/elasticsearch/elasticsearch.ymlに記載した通り
cluster.name: graylog
となる。これは特に踏み込まない。。
GraylogのNode
これもElasticsearch自体は1つしかインストールしていないため、Nodeは1つとなる。
[opc@graylog ~]$ sudo curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
{
"cluster_name" : "graylog",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1, ---★1つ
"number_of_data_nodes" : 1, ---★1つ
"active_primary_shards" : 8,
"active_shards" : 8,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
[opc@graylog ~]$
[opc@graylog ~]$ sudo curl -XGET 'http://localhost:9200/_cat/nodes'
10.0.0.2 19 26 0 0.00 0.00 0.00 mdi
[opc@graylog ~]$
GraylogのIndex
デフォルトIndexが一つ作成されている。
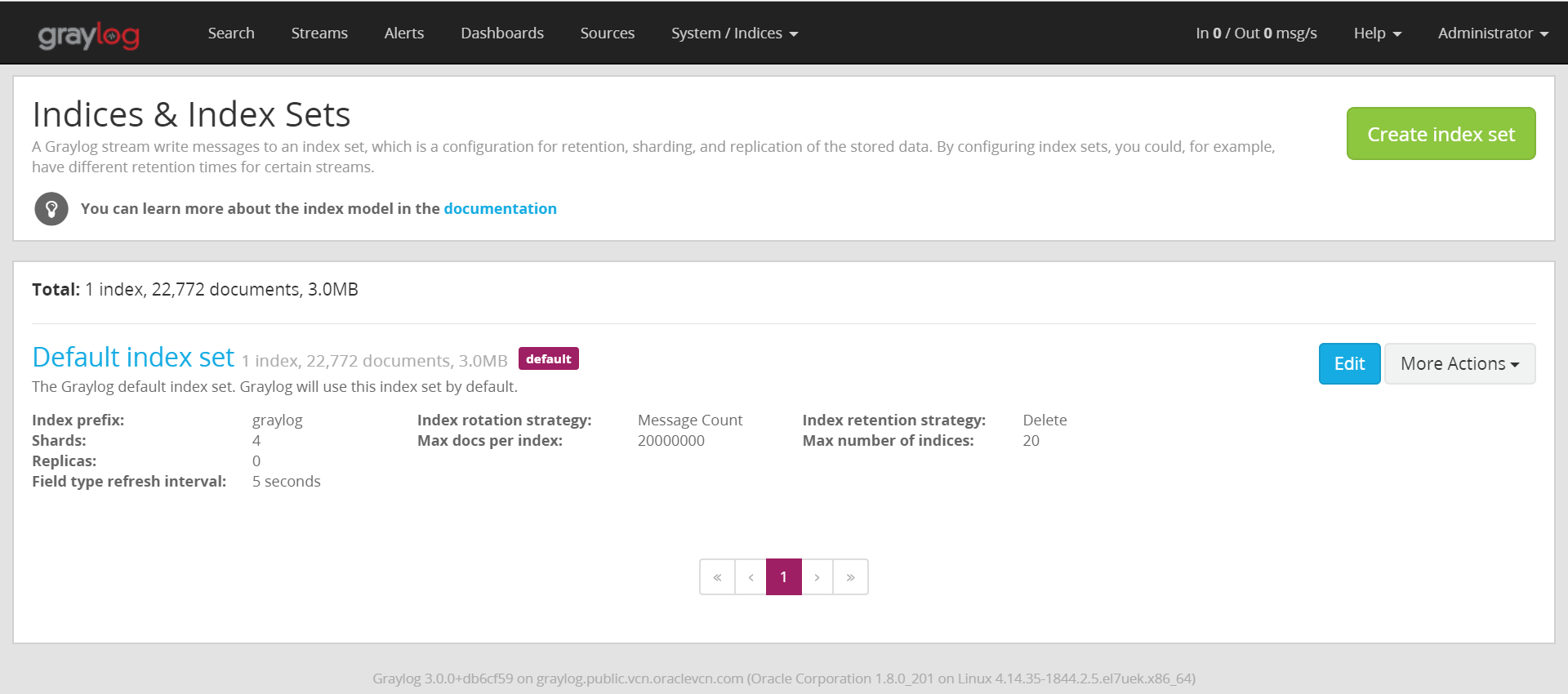
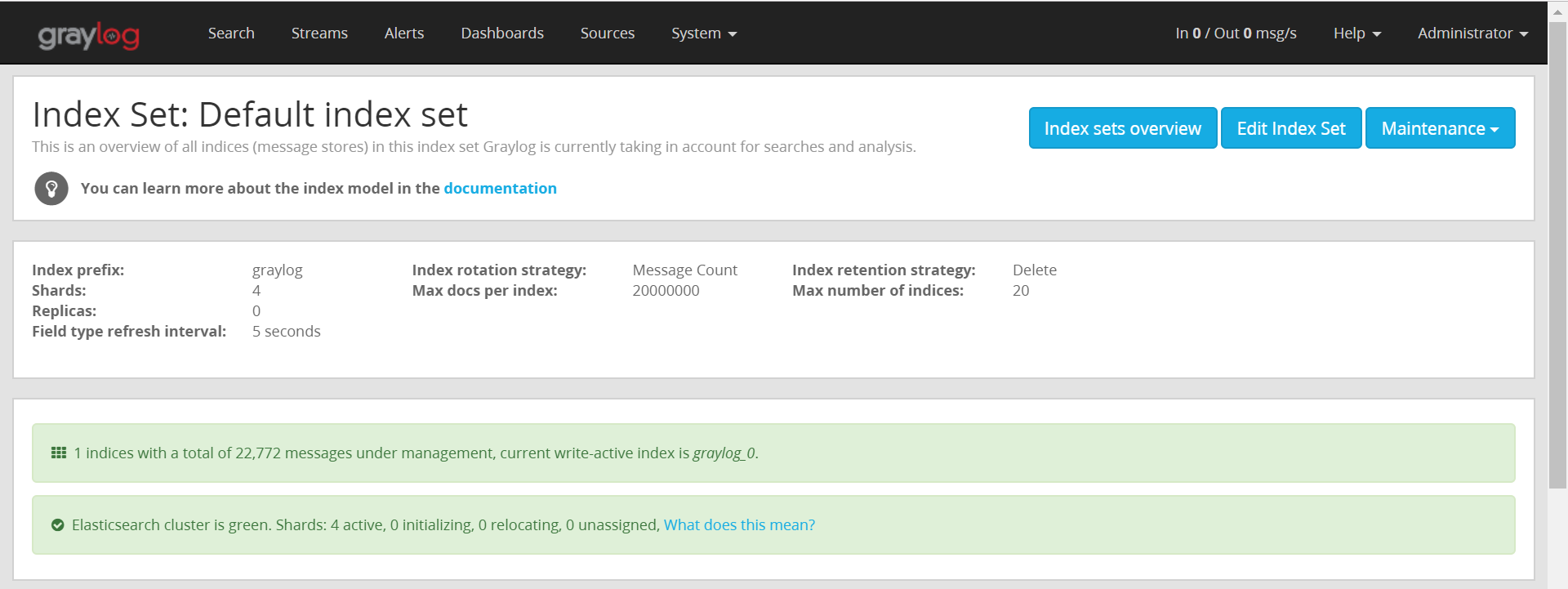
- Index prefix : cluster名と同じになる?
- Shards : 4つになるみたい。詳細はShardsの章で。
- Replicas : Elasticsearchは読み取り用Shardという位置付けでReplicaが作成される。デフォルトではGraylogは0で作成されるみたい。本格的に考えるなら構築が必須。
- Field type refresh interval : デフォルトは5秒。Graylogのマニュアルには書いていない。。。この間隔でRAMバッファの内容がディスクに新しいセグメントとして書き込まれ検索可能になる(らしい)。セグメントが多くなるとマージがされていくみたい。性能考えるとこの辺も要検討ポイントになりそう。
- flushについて
-
refreshについて
これらの書かれ方を見ると、refreshは検索可能になるが、永続的に保持はされないように見えるので注意が必要かも。
- Index rotation strategy : デフォルトはMessage Count。データの保持期間のようなもので、この設定だとメッセージ数となる。その他に、サイズや期間での設定が可能。
- Max docs per index : 上記のローテーションが実施されるメッセージの数。選択したローテーションタイプでここの表示は変わる(はず)。
- Index retention strategy : デフォルトはDelte。ローテーションの方式についてで、この場合は削除される。他にもCloseやArchiveもあるらしい。
- Max Number of indices : デフォルトは20。ローテーションしたIndexが20に達すると、古い物から削除されていく。
こう見ていくと、本気でやろうと思うとかなり設計が必要になるイメージがある。以下にindexの詳細についての画面も貼っておく。
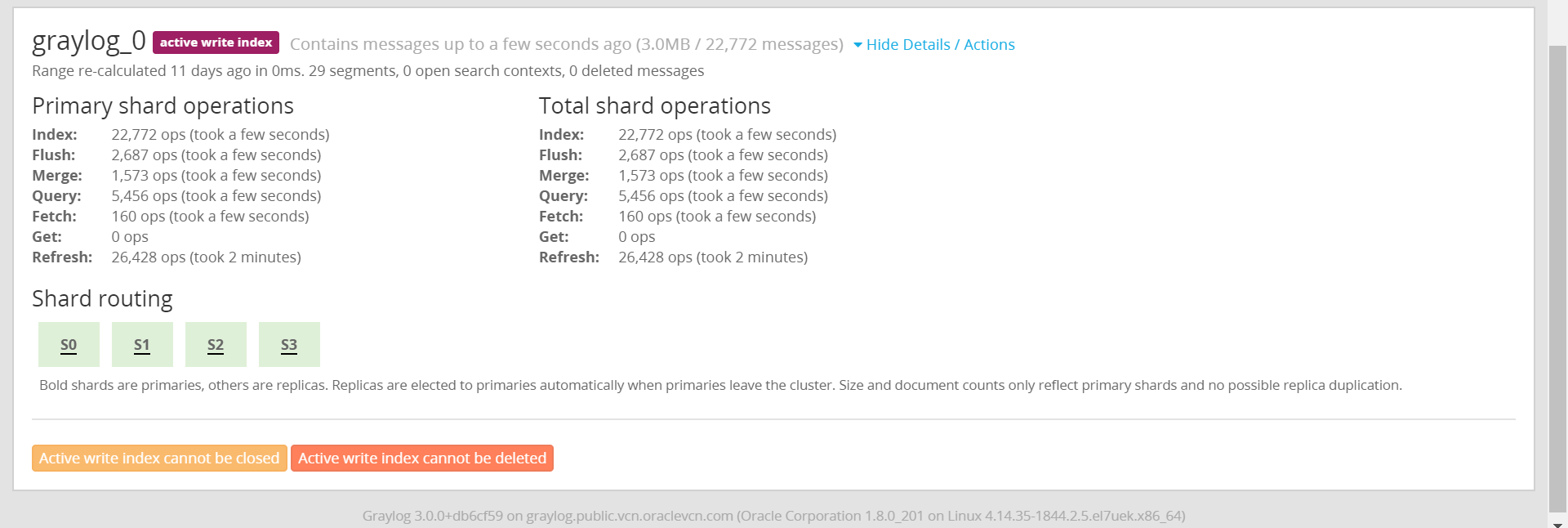
graylog_0がローテーションするとgraylog_1となる模様。
GraylogのShard
Indexの章にも記載したが、Shardは4つでReplicateのShardはない。
[opc@graylog ~]$ sudo curl -XGET 'http://localhost:9200/_cat/shards'
messages_0 3 p STARTED 0 261b 127.0.0.1 sVkZ3BV
messages_0 1 p STARTED 0 261b 127.0.0.1 sVkZ3BV
messages_0 2 p STARTED 0 261b 127.0.0.1 sVkZ3BV
messages_0 0 p STARTED 0 261b 127.0.0.1 sVkZ3BV
graylog_0 3 p STARTED 5777 1.1mb 127.0.0.1 sVkZ3BV
graylog_0 1 p STARTED 5695 776kb 127.0.0.1 sVkZ3BV
graylog_0 2 p STARTED 5725 758kb 127.0.0.1 sVkZ3BV
graylog_0 0 p STARTED 5728 791.8kb 127.0.0.1 sVkZ3BV
[opc@graylog ~]$
graylog_0のShardが4つ存在している。
Index名、Shardの番号、プライマリ/レプリカの情報、ステータス、ドキュメント数、サイズ、IP、node名となっている。
またデフォルトでは物理的に以下に配置されていた。
[opc@graylog ~]$ sudo ls -l /var/lib/elasticsearch/nodes/0/indices/EXDuCrKOQ9OwDJZpplNWRA
total 0
drwxr-xr-x. 5 elasticsearch elasticsearch 49 Mar 15 05:58 0
drwxr-xr-x. 5 elasticsearch elasticsearch 49 Mar 15 05:58 1
drwxr-xr-x. 5 elasticsearch elasticsearch 49 Mar 15 05:58 2
drwxr-xr-x. 5 elasticsearch elasticsearch 49 Mar 15 05:58 3
drwxr-xr-x. 2 elasticsearch elasticsearch 24 Mar 20 10:31 _state
ClusterにNodeを追加してみる
構成を少しだけ理解したので、デフォルトからClusterにNodeを追加してみたいと思う。
InstanceをOracle Cloud Infrastructure(OCI)で構築した後に、以前の記事を参考にまずはJavaとElasticsearchをインストールする。通常、Elasticsearchは同じCluster名がネットワーク上にあると自動でCluster構成を組んでくれるらしいが、マルチキャストが使えないので、自身で構成をする必要がある。(どこのCloudベンダもマルチキャストは使えないので注意)
ClusterのNode追加方法
Computeが追加出来たら、最初のサーバーと追加したサーバーで以下を実施する。
[opc@graylog ~]$ sudo vi /etc/elasticsearch/elasticsearch.yml
【以下を追加】
node.name: node-1 または node-2
network.hosts: 0.0.0.0 ---※1
discovery.zen.ping.unicast.hosts: ["**最初のサーバー**", "**追加したサーバー**"] ---※2
【ここまで】
※1:後々、面倒なのでListenを0.0.0.0にした。
※2:Internal IPアドレスで設定。
[opc@graylog ~]$ sudo systemctl restart elasticsearch.service
[opc@graylog ~]$
[opc@graylog ~]$ curl -XGET 'http://localhost:9200/_cat/nodes'
10.0.0.10 17 16 1 0.62 0.26 0.12 mdi - node-2 ---★Nodeが追加された
10.0.0.2 13 26 2 0.26 0.25 0.19 mdi * node-1
[opc@graylog ~]$
[opc@graylog ~]$ curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
{
"cluster_name" : "graylog",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2, ---★nodeが追加された
"number_of_data_nodes" : 2, ---★nodeが追加された
"active_primary_shards" : 8,
"active_shards" : 8,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
[opc@graylog ~]$
次に、最初のサーバーにて以下を実施する。
[opc@graylog ~]$ sudo vi /etc/graylog/server/server.conf
【以下を修正】
elasticsearch_hosts = http://"**最初のサーバー**":9200,http://"**追加したサーバー**":9200
【ここまで】
[opc@graylog ~]$ sudo systemctl restart graylog-server.service
[opc@graylog ~]$
最後にShardの配置が変わっているかを確認してみる。これも最初のサーバーから確認。
[opc@graylog ~]$ curl -XGET 'http://localhost:9200/_cat/shards'
messages_0 2 p STARTED 0 261b 10.0.0.2 node-1
messages_0 1 p STARTED 0 261b 10.0.0.10 node-2
messages_0 3 p STARTED 0 261b 10.0.0.2 node-1
messages_0 0 p STARTED 0 261b 10.0.0.10 node-2
graylog_0 2 p STARTED 5845 1.1mb 10.0.0.2 node-1
graylog_0 1 p STARTED 5822 786.4kb 10.0.0.10 node-2
graylog_0 3 p STARTED 5906 1.1mb 10.0.0.2 node-1
graylog_0 0 p STARTED 5833 1.1mb 10.0.0.10 node-2
[opc@graylog ~]$
上記のように、Shardがnode1と2で分散されるようになった。
最後に
Elasticsearchの超基本だけは理解が出来た。次こそはlogの設定等について確認していきたい。