初めに
- このプロジェクトは、Python・Flask・Hugging Face Transformersライブラリを使って構築されたシンプルなチャットボットAPIです。
- GPT-2モデルを使用して、ユーザーのメッセージに対して自動で返信を生成します。
- PT-2はやや古いモデルで、対応言語は英語のみですが、処理が軽く、PCでも素早く動作するというメリットがあります。そのため、Pythonの学習用途として利用するにはちょうど良いと考え、今回このモデルを採用しました。
主な機能
- Flaskで構築されたREST API
- GPT-2を使った自然言語生成
- CORS対応(他のドメインからもアクセス可能)
- CPU環境で動作(GPU不要)
- 応答生成のパラメータ調整可能(top_p、top_k、temperatureなど)
動作環境
- Python 3.8以上
- pip パッケージマネージャー
必要なPythonライブラリ
以下のコマンドで依存パッケージをインストールします:
pip install flask flask-cors transformers torch
ファイル構成
chatbot/
├── app.py # Flask アプリ本体
└── README.md # この説明ファイル
実行方法
-
- ライブラリのインストール
pip install flask flask-cors transformers torch
-
- Flaskサーバーの起動
# ドライブ直下に移動する
cd C:*****************\ai-chat-backend
# 仮想環境を作る
python -m venv venv
# 仮想環境を有効化する
venv\Scripts\activate
# サーバー起動
python app.py
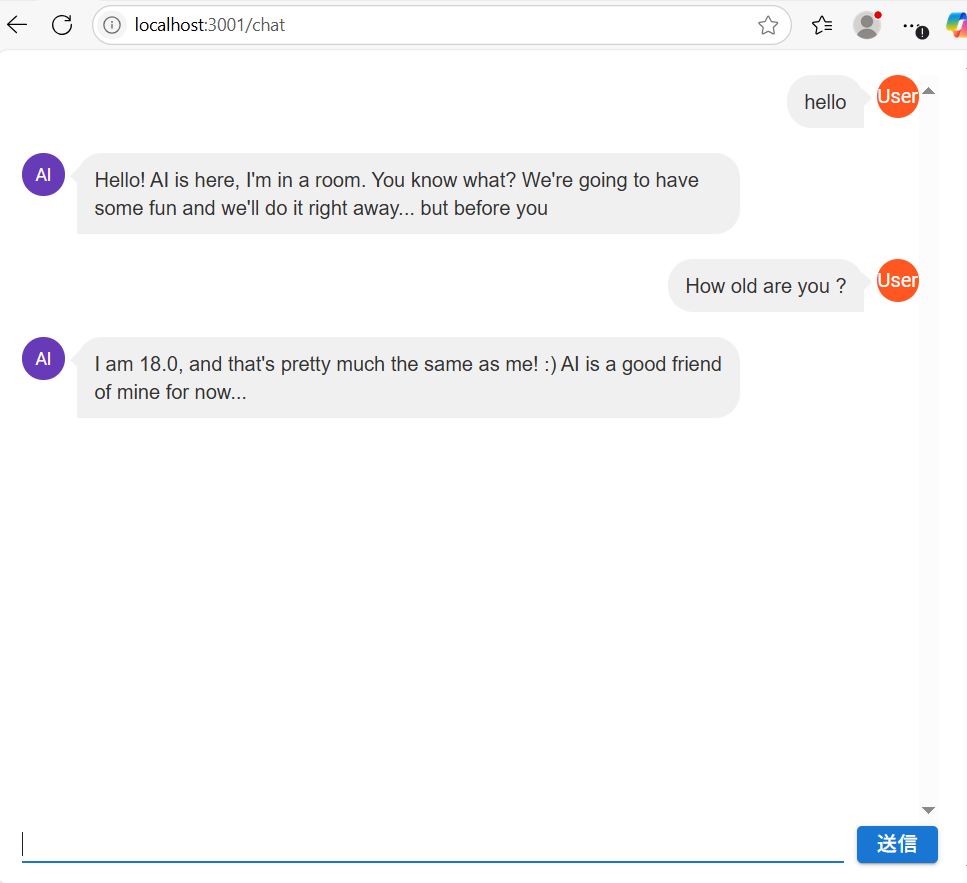
起動後、http://localhost:5000 でAPIが使用可能になります。
APIの使い方
-
- エンドポイント
POST /chat
-
- リクエストヘッダー
Content-Type: application/json
-
- リクエストボディの例
{
"message": "hello"
}
-
- レスポンスボディの例
{
"reply": "hello, I am fine..."
}
cmdで実行例
- リクエスト
curl -X POST http://localhost:5000/chat -H "Content-Type: application/json" -d "{\"message\":\"hello\"}"
- レスポンス
{
"reply": "Hello! I'm a robot. AI is not the same as human, so let's get going on this one...Hello there (laughs). You can see that you"
}
## APIの使い方
```python
outputs = model.generate(
input_ids,
max_length=50,
do_sample=True,
top_p=0.8,
top_k=30,
temperature=0.7,
no_repeat_ngram_size=2,
early_stopping=True
)
top_p, top_k, temperature などを変更することで、出力の自然さや多様性を調整できます。
app.py ソースコード説明
from flask import Flask, request, jsonify
from flask_cors import CORS
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
app = Flask(__name__)
CORS(app) # ここでCORS対応
model_name = "gpt2" # GPT-2モデルを指定
# モデルとトークナイザーの準備
# GPT-2のモデルとトークナイザーをロード。
# to("cpu") により、GPUがない環境でも動くようにCPUで推論。
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model = model.to("cpu") # CPUで動かす場合
@app.route("/chat", methods=["POST", "OPTION"])
def chat():
user_input = request.json.get("message", "")
prompt = f"User: {user_input}\nAI:"
# トークナイズしてモデルに渡す
inputs = tokenizer(prompt, return_tensors="pt") # 入力をトークンに変換。
inputs = {k: v.to(model.device) for k, v in inputs.items()} # モデルのデバイス(この場合はCPU)に移動。
# テキスト生成
with torch.no_grad():
outputs = model.generate(
inputs["input_ids"],
max_length=40,
do_sample=True,
top_p=0.8,
top_k=30,
temperature=0.7,
no_repeat_ngram_size=2,
repetition_penalty=1.2,
early_stopping=True
)
# 出力トークンをテキストに変換。
reply = tokenizer.decode(outputs[0], skip_special_tokens=True)
# プロンプト部分を削除し、AIの返答だけを取り出す。
reply = reply.replace(prompt, "").strip()
return jsonify({"reply": reply})
# このPythonファイルを直接実行したときに、Flaskサーバーを起動。
if __name__ == "__main__":
app.run(debug=True)
注意事項
-
gpt2 は英語モデルなので、日本語には適していません。
日本語対応モデル(例:rinna/japanese-gpt-1b や ELYZA-japanese-Llama-2-7b-instruct)を使用することで、より自然な応答になります。 -
CPU環境では処理が重くなる場合があります。可能であればGPU環境を推奨します。
github リンク
ご指摘等ございましたら、ぜひコメントいただけたら嬉しいです!