強化学習の勉強のためにゲーム環境を自作してみました。その際、苦労したことをメモとして残します。
動作環境
今回使用した主なプログラムを下に記載します。
- Windows10Home
- Anaconda 4.10.3
- Tensorflow 2.5.0
- Keras-RL2
- OpenAI Gym 0.18.3
- Pygame 2.0.1
ゲームの内容
今回作成したゲームは「地球帰還ゲーム」です。宇宙船を操縦し地球に帰るだけのしょぼいゲームです。
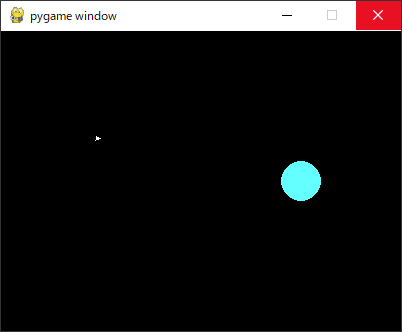
左の小さい白い三角形が宇宙船で、右の水色の丸は地球です。宇宙船は上か下に進路を少しだけ変更できますが、速度は変えることができません。宇宙船が画面外に出るか、進路を上げすぎて真上を向くか、もしくは真下を向くと、ゲームオーバー(失敗)です。無事、宇宙船を地球に到達させることができれば、ゲームクリアー(成功)となります。
Gymのための環境説明
学習が速くなるようにパラメータ数を最小限にして作成しています。
- 観測(Observation)で与えるデータは「宇宙船のX座標(0~400)」「宇宙船のY座標(0~300)」「宇宙船の向いている方向(0~π)」の3つだけです。
- 行動(Action)は「上を向く(0)」「下を向く(1)」の2つだけです。
- 報酬(Reward)はゲームが続いているときは「報酬なし(0)」で、ゲーム終了時は「失敗(-1)」か「成功(1)」を得ます。
- 宇宙船の初期状態は、位置は(X:0~100,Y:100~200)の範囲内で、向きは右方向を90度として(72~108度)の範囲内で、出現しています。
- 地球の位置は固定です。
- 宇宙船がどのように進んだかわかるように軌跡を残す仕様にしてます。(10ゲーム分)
最初はもっと難しいゲームを考えていたのですが、モデルが全く学習しなかったので仕方なく上の様な仕様になりました。こんなゲームでも学習させるのに大変苦労しました。
プログラム
今回作成したプログラムを記載します。
import pygame
import math
import numpy as np
import gym
from tensorflow.keras.models import Sequential,load_model
from tensorflow.keras.layers import Dense,Flatten
from tensorflow.keras.optimizers import Adam
from rl.memory import SequentialMemory
from rl.policy import BoltzmannQPolicy
from rl.agents.dqn import DQNAgent
makernd = lambda a,b:np.float32(np.random.random_sample()*(b-a)+a)
shipsin = lambda r,a:math.sin(r+math.pi*7/8*a)*5
shipcos = lambda r,a:math.cos(r+math.pi*7/8*a)*5
class game(gym.Env):
def __init__(self):
self.screen = pygame.display.set_mode((400,300))
self.clock = pygame.time.Clock()
self.action_space = gym.spaces.Discrete(2)
self.observation_space = gym.spaces.Box(low=np.float32([0,0,0]),high=np.float32([400,300,math.pi]))
self.reward_range = (-1,1)
self.logcount = 9999
def reset(self):
self.observation = np.float32([makernd(0,100),makernd(100,200),makernd(math.pi*2/5,math.pi*3/5)])
if self.logcount >= 10:
self.screen.fill((0,0,0))
pygame.draw.circle(self.screen,(100,255,255),(300,150),20)
pygame.display.update()
self.logcount = 0
self.logcount += 1
return self.observation
def render(self,mode):
x = self.observation[0]+0.5
y = self.observation[1]+0.5
r = self.observation[2]
pygame.draw.polygon(self.screen,(255,255,255),((int(x),int(y)),(int(x+shipsin(r,-1)),int(y-shipcos(r,-1))),(int(x+shipsin(r,1)),int(y-shipcos(r,1)))))
pygame.display.update()
self.clock.tick(60)
def step(self,act):
self.observation[2] += np.float32(act*2-1)/20
self.observation[0] += math.sin(self.observation[2])*6
self.observation[1] -= math.cos(self.observation[2])*6
if self.observation[0] >= 400 or self.observation[1] <= 0 or self.observation[1] >= 300 or self.observation[2] <= 0 or self.observation[2] >= math.pi:
return self.observation,np.float32(-1),True,{} #失敗(画面外に出た、船が真上か真下を向いた)、reward=-1
if (self.observation[0]-300)**2+(self.observation[1]-150)**2 <= 400:
return self.observation,np.float32(1),True,{} #成功(船が地球に到着した、地球の半径20)、reward=1
return self.observation,np.float32(0),False,{} #まだ飛行中、reward=0
pygame.init()
env = game()
env.reset()
model = Sequential([Flatten(input_shape=(1,3)),Dense(16,activation='relu'),Dense(16,activation='relu'),Dense(16,activation='relu'),Dense(2,activation='linear')])
# model = load_model('game') #保存したモデルを呼び出す時に使用する
memory = SequentialMemory(limit=50000, window_length=1)
policy = BoltzmannQPolicy()
dqn = DQNAgent(model=model,nb_actions=2,gamma=0.99,memory=memory,nb_steps_warmup=100,target_model_update=1e-2,policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
dqn.fit(env,nb_steps=100000,visualize=True,verbose=1) #visualize=Falseにすれば、画面描写をしなくなる
dqn.model.save('game',overwrite=True)
dqn.test(env,nb_episodes=10,visualize=True)
pygame.quit()
学習させてみる
学習が成功したモデルの学習状況を説明します。
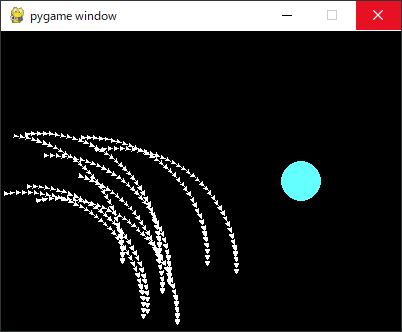
学習初期は下図のように、1種類(下図では下方向)の行動しかしないモデルが多くありました。ず~と下を向き続け画面端もしくは真下を向いたので「失敗」になっています。たまにランダムで上下を選ぶモデルもあったのですが、大半のモデルは同じ選択を続けました。
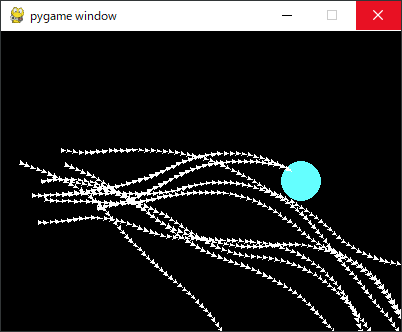
学習が進むと下図のような軌跡になりました。先の「失敗」を何とか学習できたようで、下を向き続けることが少なくなっています。下を向かなくなったので初めて「成功」することができました。
こうした偶然の「成功」を何十・何百回行うことによりやっと学習が進み、「成功」した例と同じような軌跡を進むようになります。
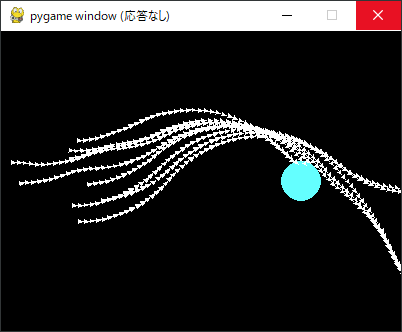
更に成功回数が多くなるとパターンも増え、どんな初期状態でも成功することができるようになりました。
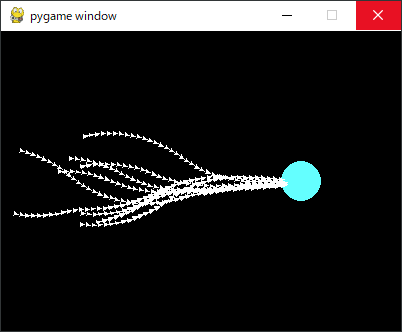
報酬について
報酬の設定について色々調べていたところ、下のような希望しない学習を行い成功しにくくなったことがあるので、今後のために記載しておきます。
- 宇宙船が地球から遠ざかる時に負の報酬(-0.01)を与えるようにしたところ、画面端ではすぐに画面外に出て「失敗」にして負の報酬を止めるという学習をした。
- 宇宙船が地球に近づく時に正の報酬(0.01)を与えるようにしたところ、地球にゆっくり近づいて多くの報酬を得るという学習をした。
まとめ
今回のプログラムで学んだことを記載します。
-
モデルに関すること
・本モデルの作成方法では学習初期で同じ選択を行う場合が多い。
・学習速度はモデル毎に結構違う。出来の良いモデルを探そう。 -
ゲームに関すること
・成功しやすいゲームにする。(成功報酬がなければ成功する方法を学習しません。)
・報酬は適当に決めては駄目。