はじめに
手書きで書いた文章やテキストデータが埋め込まれていない謎のpdfをテキストデータにして保存しておきたいなぁと思ったことはありませんか?
Google Docsには光学文字認識(OCR)機能があり、画像をGoogle docsとして開くと自動で画像中の文字を認識して、docs内に埋め込んでくれます。
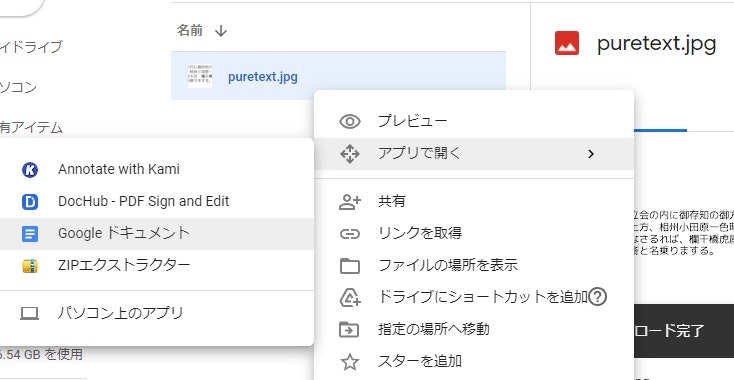

かなり精度も高く便利ではあるのですが、テキストを読み出すためにいちいちGoogle Driveにファイルを上げてGoogle Docsで開いて……とするのは面倒です。
Google Vision APIの方ではOCR機能が提供されているのですが、こちらは有料らしいのであまり使いたくないです。
なのでこれら一連の操作をラップしたクラスを作りました。
使い方
from googleAPI import GoogleAPI
googleAPI = GoogleAPI(drive_token_path='./auth_keys/drive/token.json', docs_token_path='./auth_keys/docs/token.json',
drive_credentials_path='./auth_keys/drive/credentials.json', docs_credentials_path='./auth_keys/docs/credentials.json')
print(googleAPI.OCR("./text.jpg"))
基本的にはOCR()に読み込みたいファイルのパスを渡すだけです。結果が返ってくるまでにはちょっと時間がかかります。
ここで、tokenはAPIへのアクセストークンでcredentialsはOAuth2.0クライアントIDです。
取得方法についてはREADMEにサラっと書いておいたのでそちらを参照頂けると幸いです。
使用例
例のテキストには外郎売の冒頭を使用しました。
1. 綺麗なテキスト

結果
拙者親方と申すは、御立会の内に御存知の御方も御座りましょうが、御江戸を発って二十里上方、相州小田原一色町を御過ぎなされて、青物町を上りへ御出でなさるれば、欄干橋虎屋藤右衛門、只今では剃髪致して圓斎と名乗りまする。
puretext error: 0
誤認識0です。かなり精度がいいですね。
2. ぼやけたテキスト

ちょっとぼやけていますが、人間なら問題なく読める範囲です。
結果
拙者親方と申すは、御立会の内に御存知の御方も御座りましょうが、御江戸を発って二十里上方、相州小田原一色町を御過ぎなされて、青物町を上りへ御出でなさるれば、欄干橋虎屋藤右衛門、只今では剃髪致してこ斎と名乗りまする。
blur error: 1
圓がこと誤認識されてしまっています。
欄`の方が読みにくいと思いますが、旧字体はデータが少ないとかあるんでしょうか?
3. 拡大してノイズが乗ったテキスト

こういう画像は結構多そうです。
結果
者親方と申すは、御立会の内に御存知の御方も御座りましょうが、御江戸を発って二十里上方、相州小田原一色町を御過ぎなされて、青物町を上りへ御出でなさるれば、欄干橋虎屋藤右衛門、只今では剃髪致して画家と名乗りまする。
coarse error: 2
圓斎が画家と誤認識されてしまっています。そうはならんやろ。
4. pdf

pdfは張れなかったのでスクショです。
結果
拙者親方と申すは、御立会の内に御存知の御方も御座りましょうが、御江戸を発って二十里上方、相州小田原一色町を御過ぎなされて、青物町を上りへ御出でなさるれば、欄干橋虎屋藤右衛門、只今では剃髪致して圓斎と名乗りまする。
pdf error: 0
完璧です。
5. 手書き文字

結果
手書手文字美女车
手書き文字の認識精度はあまり高くないみたいです。ひらがなが読み取られていないあたり、中国語として認識されていそうな気がします。
おわりに
手書き文字の認識精度はあまり高くないようですが、テキスト画像は高い精度で認識できるようです。
また、今回は試していませんが、プリントをスキャンしたpdfなんかもそこそこの精度で認識できると思います。良ければ使ってみてください。