はじめに
社内での輪読会のためにこちらの論文の内容をまとめます。GANについては研究で扱ったわけではないです。なので翻訳に誤った箇所もあるかと思いますので(あと英語も得意ではないので)、そのときは適宜修正リクエストください。
Abstract(完全翻訳ではない)
Neural Architecture Searchの研究が画像分類・セグメンテーションおいて優勢となっている。本論文では、generative adversarial networks(GAN)のためのNASアルゴリズムAutoGANについて紹介する。NASとGANを結合させることは今までにない試みである。
我々は、generator architectural variationsのための探索空間を定義し、探索のガイドのためにController RNNを用いた。そしてパラメーター共有とdynamic-resettingによりプロセスを加速化させた。Inception scoreを報酬として採用し、Multi-level search strategyをNASのパフォーマンスを上げる方法として導入した。
評価実験では、AutoGANの無条件での画像生成の有効性を検証した。特に、FIDのスコアがCIFAR-10において12.42、STL-10において31.01という高い従来のGANより高いパフォーマンスを達することができる構造を発見することができた。ソースコードについてはgithubで公開されている。
Neural Architecture Search(NAS)
NASはニューラルネットワークを自動的に最適化するアルゴリズムである。NASは3つの要素が存在する。
- 探索空間
- 全体的な構造の探索(マクロサーチ)
- 各セルごとの探索して事前に定義された方法でスタックする(ミクロサーチ)
- 最適化アルゴリズム
- 強化学習(ポピュラーな方法)
- 遺伝的アルゴリズム
- ベイジアン最適化
- ランダムサーチ
- 勾配ベースの最適化
- プロキシタスク(学習中に発見したアーキテクチャを効果的に評価するための設計)
- 低解像度画像を用いる
- 代理モデルでパフォーマンスを予測する
- 小さいバックボーンを使う
- パラメーター共有を活用する
ほとんどのNASでは、ネットワーク構造もしくはセルが1つのコントローラーで生成される。最近の研究では、「beam search」を使用して、画像分類タスクでNASに「multi-level search」を導入した。アーキテクチャの検索は小さなセルで開始され、最高のパフォーマンスの候補が保持される。 より大きなセルについては、それらに基づいて次の検索ラウンドが継続される。
提案手法
GANには2つのネットワークが存在する。
- Generator(以下G)
- Discriminator(以下D)
この2つを学習させる方法として、一方のG(or D)を固定してD(or G)のみを探索する方法を考えたとき、DまたはGの間のパワーに不均衡が容易に生じてしまう。一方で両者を結合して探索すると元々の不安さをさらに悪化させてしまう。そこで、この研究ではNASを使用してGのアーキテクチャのみを検索し、Gが深くなるにつれてDを成長させ、所定のルーチンに従って事前定義されたブロックをスタックすることを提案する。
AutoGANは、探索空間からブロックを選ぶためにRNN controllerを用いた方法に従う。下の図にそのスキームが説明されている。
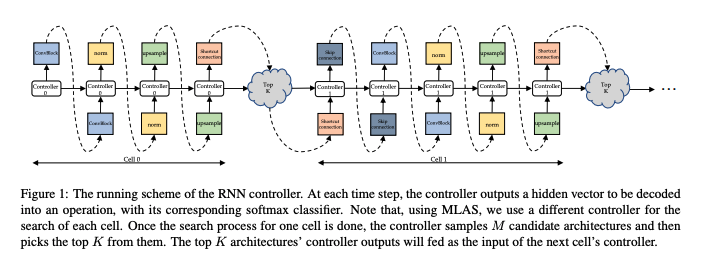
次に、AutoGANの3つの要素について説明する。
探索空間
AutoGANはmulti-level architecture search strategyに基づいている。ここでは(s+5)のタプル要素を用いる。s番目のセルを(skip_1, ..., skip_s, C, N, U, SC)とする。この時sは0から始まるセルのインデックスである(ただし0番目のセルにはskip_0は存在しない)。
- skip_i:現在のs番目のセルが(i-1)番目のセル(iは1~sの範囲)からのskip connectionを入力して取るかどうかを示すバイナリ値。各セルは他の先行セルから複数のスキップ接続を取得できる
-
C:
pre-activationとpost-activationの畳み込みブロックを含む畳み込みブロックタイプ -
N:
batch normalizationとinstance normalizationとno normalizationを含む -
U:
bilinear upsamplingとnearest neighbor upsamplingとstride 2 deconvolutionなどのアップサンプリングを含む(GANで標準なもの) - SC:セル内のショートカットのバイナリ値を示す
下の図でAutoGANの探索空間について説明している。
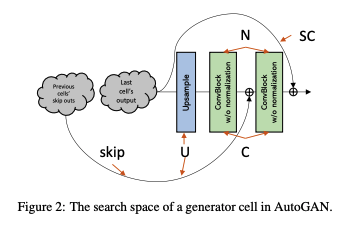
プロキシタスク
Inception score(IS)とFID scoreがGANの主な評価の指標となる。FIDスコアの計算にははるかに時間がかかるため、強化学習を介してコントローラーを更新する報酬として、派生したchild modelのISを選択する。
パラメーター共有を用いることでNASを効果的にブーストさせることができる。さらにパラメーターの動的リセットの戦略を導入する。GANのトレーニングを長時間行うとモードが崩壊することが確認されていて、共有された崩壊モデルのトレーニングを継続するのは時間の無駄であるためである。モード崩壊が発生すると、通常、トレーニング損失(ヒンジ損失)の分散が非常に小さくなることが観察される。
観察に基づいて、ジェネレーターとディスクリミネーターの両方について、最新のトレーニング損失値を保存する移動ウィンドウを設定する。これらの保存されたトレーニング損失の標準偏差が事前に定義されたしきい値より小さくなると、現在の反復の共有GANのトレーニングが終了する。
共有GANモデルのパラメーターは、現在のイテレーションでコントローラーを更新した後に再初期化される(RNNコントローラーのパラメーターを再初期化はしない)。したがって、歴史的な知識を継承してアーキテクチャー検索をガイドし続けることができる。 動的リセットにより、検索プロセスがより効率的になる。
最適化メソッド
2つのパラメーターをセットする。
- RNN controller (θ)
- Generator(とそれに応じたDiscriminator) の共有パラメーター(ω)
学習過程は以下のような擬似コードになる。
iters = 0 ;
stage = 0 ;
FDR = False ;
while iters < 90 do
train (generator, discriminator, FDR);
train (controller);
if iters % ustage == 0 then
save the top K architectures;
generator = grow (generator) ;
discriminator = grow (discriminator) ;
controller = new (controller);
stage+ = 1;
end
if FDR == True then
// dynamic reset
initialize (generator);
initialize (discriminator);
FDR = False;
end
iters+ = 1;
end
最初のフェーズでは、θを固定して、いくつかのエポックで共有GANのωをトレーニングする。GANの各トレーニングのイテレーションにて、アーキテクチャの候補がRNN controllerによってサンプルされる。FDRはdynamic resetのためのフラグで、トレーニング損失の標準偏差がしきい値より小さくなるとTRUEとなり、直ちにトレーニングが終了される。共有GANは、現在のエポックでのコントローラーのトレーニングが完了するまで再初期化されない。
次に、ωを固定してθをトレーニングする。controllerは、最初に共有ジェネレーターのK個のchild modelをサンプリングする。ISは報酬として計算される。RNN controllerは移動平均ベースの強化学習によって更新される。ustage回のトレーニングのあと、トップであるKアーキテクチャが派生アーキテクチャとしてピックアップされる。その間、次の段階のアーキテクチャ検索を進めるために、新しいコントローラが初期化される。
共有GANの学習
RNN controllerのポリシーπ(a, θ)を固定し、共有パラメーターωを標準のGANトレーニングを介して更新する。具体的には、以下のようなヒンジの敵対的損失を使用して交互にトレーニングする。
L_D =E_{x∼q_{data}} [min(0, −1 + D(x)] + E_{z∼p(z)}[min(0, −1 − D(G(z))]
L_G = E_{z∼p(z)}[min(0, D(G(z))]
さらに、マルチレベルアーキテクチャ検索(MLAS)をAutoGANに導入する。ここでは、ジェネレーター(およびそれに対応する弁別器)が徐々に成長する。MLASは、ビーム検索を使用して、ボトムアップのセル単位で検索を実行する。次のセルを検索するときは、別のコントローラーを使用して、現在の候補セルから上位Kビームを選択し、それらに基づいて次のラウンドの検索を開始する。
Controllerの学習
ここではωを固定してθを更新する。サンプリングされたchild modelのaのISとして報酬R(a,ω)を定義する。RNN controllerはREINFORCEを用いた移動平均ベースのAdamを用いて更新される。また、探索を促進するためにエントロピーを追加する。
この研究ではLSTM controllerを用いている。各タイムステップで、LSTMは隠れ状態ベクトルを出力する。これは、対応するsoftmax分類器によってデコードおよび分類される。そして新しいセルが既存のモデルに追加されて出力画像の解像度が上がると、新しいコントローラーが初期化される。以前の上位Kモデルのアーキテクチャと対応する隠れ状態ベクトルが保存される。隠れ状態ベクトルは、次のセルの操作を検索するための入力として新しいコントローラーに供給される。
アーキテクチャの導出
最初に、学習したポリシーπ(a, θ)からいくつかのジェネレーターアーキテクチャをサンプリングする。 次に、報酬R(IS)が各モデルに対して計算される。 次に、最高の報酬の観点から上位Kモデルを選択し、それらをゼロからトレーニングする。 その後、ISを再度評価し、ISが最も高いモデルが最終的な派生ジェネレーターアーキテクチャになる。
評価実験
- 学習データ
- CIFAR-10
- STL-10(転移性を確かめるため)
- 学習(GAN)
- 学習率:2e-4
- loss:ヒンジ
- optimizer:Adam
- バッチサイズ
- generator:128
- discriminator:64
- スペクトル正規化をdiscriminatorのみに使用
- 学習(RNN controller)
- 学習率:3.5e-4
- optimizer:Adam
- 1e-4で重み付けされた報酬にコントローラーの出力確率のエントロピーを追加
- 学習(AutoGAN)
- iterate:90
- GAN epochs:15/iter
- RNN controller steps:30/iter
- Dynamic resettingのための閾値:1e-3
- 検出されたアーキテクチャのトレーニングを5000回行う
CIFAR-10の結果
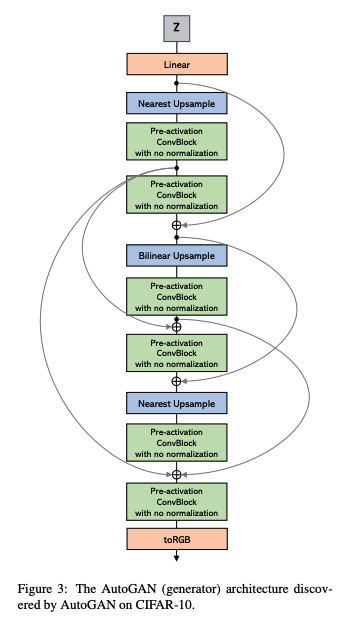
下の図がCIFAR-10で発見されたアーキテクチャ
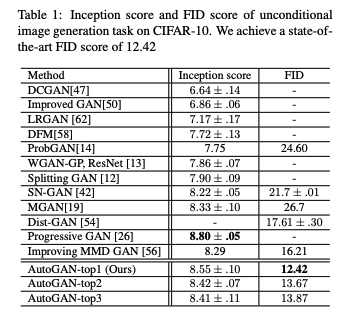
従来のGANとの比較をISとFIDで行なったのが下の表
実際に生成された画像が下の写真

STL-10での結果
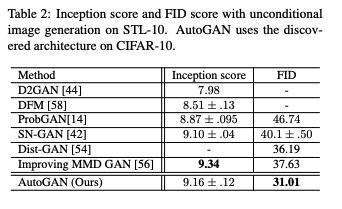
CIFAR-10で作られたアーキテクチャでSTL-10を学習させた結果を従来のGANと比較した。結果は以下の表。
実際に生成された画像が以下の写真。

Conclusion
さらに従来のGANより高い性能を出すために行うことは以下。
-
attention/self-attention・style-based generator・relativistic discriminator・Wasserstein lossを用いた探索空間の拡張 - 高解像度の画像を用いたテスト。しかしCIFAR-10の時点で43時間もかかっているのでアルゴリズムの改善が必要
- Discriminatorの探索
- 条件付きGANや半教師付きGANなどのラベルを組み込む機能をつける
さいごに
この論文を読む前にNASの知識がなかったので、そこから勉強する必要がありました。しかし私が機械学習の研究をやっていた頃(と言っても1年前くらい)にはNASなんて言葉はそんなに聞かなかったような気がするのですが、どうやら今はこのAutoMLが結構熱い分野のようですね。。正直この機械学習の技術の流動の速さに驚きました。また、ここでは論文の4.3. Ablation Study and Analysisについては省略しています(あまりこの分野に深入りするもりは無かったので)。
あと、これのPythonのコード動かしてみようと思ったのですが、GPU対応のPCでは無かったのでpipで詰まりましたw