先日のNeurIPS読み会での@hamadakoichiさんの発表によれば、
NeurIPS2018で、単に「GANsの生成品質を向上する」というだけの採択論文は、もう1本もない
とのこと。確かに最近のGANsによる生成画像は解像度、クオリティ共にもはや「本物」に近い。
で、上記発表の中でも紹介されてるProgressiveGAN、BigGAN、StyleGANあたりがここ数年のSOTAの変遷かと思うのでGANsで使われている性能評価尺度とあわせて振り返ってみた。
GANsの性能評価尺度
まず、GANsが生成する画像の品質をどうやって評価するのかについて。これはまだオープンな問題だが、比較的有名なのはinception scoreと*Fréchet Inception Distance (FID)*だと思う。両者の概要を以下に説明する。
Inception score 1
本スコアでは生成画像の「良さ」を以下2つの観点から測っている。
- 画像識別器が識別しやすい
- 物体クラスのバリエーションが豊富
$x_i$ を画像($i$ は画像のインデックスで総数は $N$ とする)、$y$ をラベルとすると、上記 1. は条件付き分布 $p(y|x_i)$ のエントロピーが小さくなることを意味する。一方で 2. は、$p(y|x_i)$ を $i$ について積分した周辺分布 $p(y)$ のエントロピーが大きくなることを意味する。そこで、両分布間の距離を測るためにKLダイバージェンスを用い、これを $i$ について平均化したうえでexpを取ったものがinception scoreである。inceptionと呼んでいるのは、画像識別器としてImageNetで学習済みのinceptionモデルを用いているため。
\exp\Bigl(\frac{1}{N}\sum_{i}{\rm KL}\bigl(p(y|x_{i})||p(y)\bigr)\Bigr)
2つの分布間の距離が大きいほど良い画像生成ができていると言えるため、inception scoreが大きいほど性能が高いということになる。
Fréchet Inception Distance (FID) 2
実画像の分布が考慮されていないというinception scoreの欠点を改善するため、実画像と生成画像の分布間の距離を測っている。inceptionモデルから得られる特徴ベクトル(最後のpooling層の出力)が多変量正規分布に従うと仮定し、実画像の分布と生成画像の分布間の距離をFréchet距離(Wasserstein-2距離)により求める。特徴ベクトルの平均と共分散行列が実画像についてそれぞれ $\boldsymbol{m_w}$、$\boldsymbol{C_w}$、生成画像について$\boldsymbol{m}$、$\boldsymbol{C}$ と得られているとすると、FIDは次式で定義される。
\|\boldsymbol{m}-\boldsymbol{m_w}\|^2_2 + {\rm Tr}\bigl(\boldsymbol{C}+\boldsymbol{C_w}-2(\boldsymbol{C}\boldsymbol{C_w})^{1/2}\bigr)
ProgressiveGAN 3
ICLR2017でNVIDIAのT.Kerrasらが提案。1024×1024というメガピクセルレベルの画像を圧倒的なリアリティで生成しており話題になった。生成画像例については以下のYouTubeビデオを参照いただきたい。

プログレッシブな学習
本論文のメインとなるコントリビューションは、下図のように低解像画像の生成からスタートし、徐々にレイヤを追加して解像度を上げていくというプログレッシブな学習方法を提案したことにある。
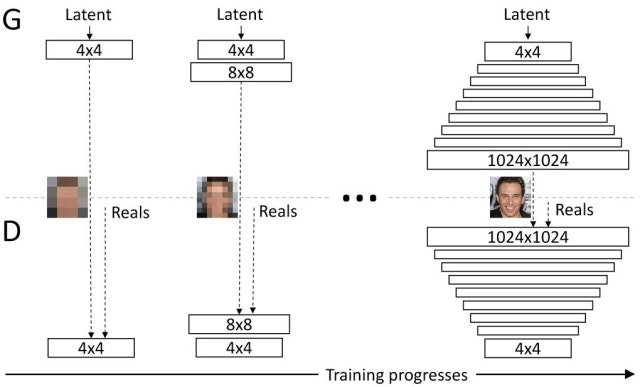
まずは4×4からスタートし、層を追加するごとに解像度を2倍にしていく。層を追加するときは、いきなり追加するのではなく、既存の層との重み付き和の形で追加して徐々にその重みを増やしていく。このようにプログレッシブな学習を行うことで、低解像度な画像の生成という単純なタスクから学習が進んでいくこととなり、学習が安定するだけでなく高速化にもつながる。
生成画像のバリエーションの改善
GANsには学習画像に含まれるバリエーションの一部だけを学習してしまうという傾向がある。この問題の解決には、discriminatorにミニバッチ全体の情報を与えてやることが有効と言われている。そこで本論文では、discriminatorにおいて計算される各特徴マップの空間座標ごとにミニバッチ内での標準偏差を求め、それを全て平均化して得られるスカラ値をコピーして敷き詰めることで新たな特徴マップとし、これをdiscriminatorに挿入している。
正規化
本論文では、共変量シフトを防ぐために一般的に用いられるBatchNormはGANsにおいては不要であり、重要なのは信号の大きさに制約をかけることであると主張している。本論文において用いられている正規化は以下の2種類で、いずれもlearnableなパラメータは含まない。
- 重み $w$ をレイヤごとに定数 $c$ で割る($c$ はHeの初期化で用いられているもの)
- generatorの各conv層の出力において、各ピクセルの特徴ベクトルを単位ベクトルに正規化
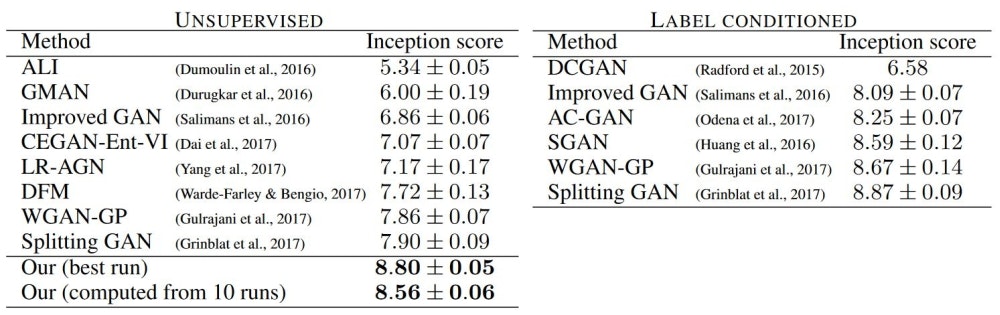
性能評価
論文中では基本的にMS-SSIM (multiscale structural similarity)による評価結果が報告されているが、ここではAppendixにあるinception scoreでの他手法との比較結果を引用する。データセットはCIFAR10である。教師なし手法においては当時のSOTAを達成しており、教師あり手法と比較しても遜色がない。ただ、やはり本論文の肝はメガピクセルレベルの画像をきわめてリアルに生成できることであり、ぜひ冒頭に引用したビデオを参照していただきたい。
BigGAN 4
2018年にDeepMindのA. Brockらが提案(ただしA. Brockはインターン生)。ImageNetのような極めてバリエーションが多く複雑なデータセットを使いclass-conditionalな画像生成を過去最大規模で学習させることに成功している。以下は生成画像の一例である。

SA-GANの改良
本論文ではベースラインとしてSA-GAN (Self-Attention GANs)5を採用している。SA-GANでは、CNNが不得意な大局的な情報の利用を実現するため、generatorとdiscriminatorの双方にself-attentionを導入している。
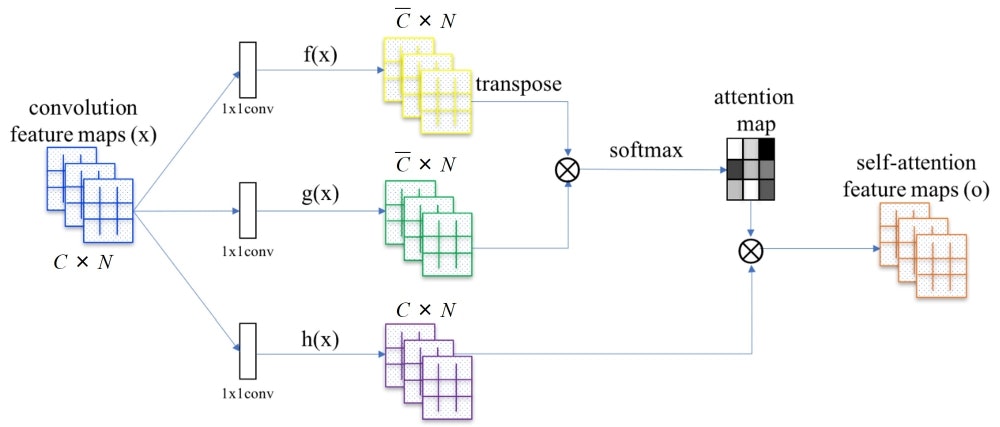
ここで、上記のattention mapの作り方についてもう少し説明する。まず、$C \times N$ の特徴マップ $x$(ただし、$C$ と $N$ はそれぞれチャネル数と画素数)は、2つの1x1 convによってそれぞれチャネル数 $\bar{C}$ の $f(x)$ と $g(x)$ に変換される。そして、$f(x)$ の転置と $g(x)$ を乗ずることによって次のように $N \times N$ のマップを得る。
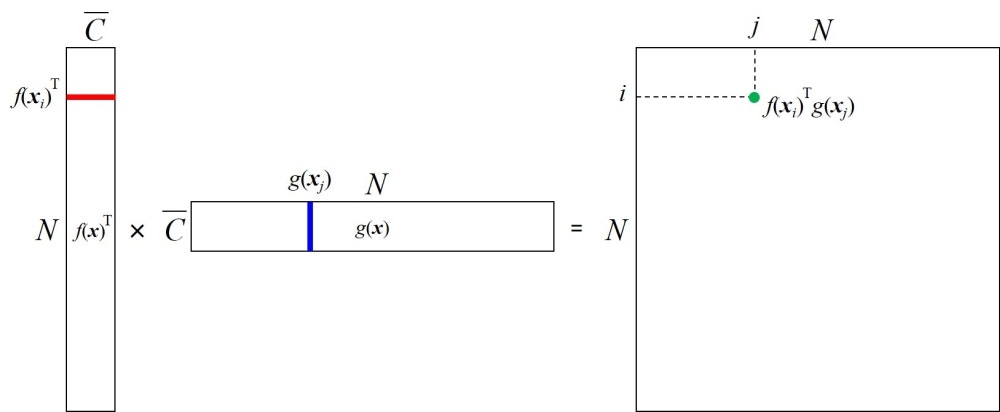
上図に示すように、得られるマップの位置 $(i, j)$ にはベクトル $f(x_i)$ と $g(x_j)$ の内積、つまり両ベクトルの類似度が入ることになる。ここで、$j$ を固定して $i$ についてsoftmaxをとったものがattention mapであり、画素 $j$ を生成する際に、画素 $i$ にどれだけ着目するかを示している。$f(x_i)$ と $g(x_j)$ が似通っているほどattention mapの値が大きくなるため、同じ画像中で特徴量が近くなる領域に着目した画像生成が可能となる。
本論文では、上記のSA-GANに対して以下の改良を施し、主にそのスケールを大きくすることで大幅に性能が改善できることを報告している。
- SA-GANでは256であったバッチサイズを8倍(2048)にまで増やすことでinception scoreを46%改善
- 各層のチャネル数を1.5倍に増やすことでinception scoreをさらに21%改善(depthを増やすのは逆効果)
- ノイズベクトルをgeneratorの入力層だけでなく隠れ層にも入力することで4%改善
このようにモデルサイズとバッチサイズを大きくすることで性能は向上するが、training collapseが発生しやすくなるため、本論文では学習中にcollapseが起きた段階で学習を止め、その直前の学習結果を使っている。論文中ではスケールを大きくすることで学習が不安定になる理由も考察されているが、ここでは割愛する。
Truncation Trick
本論文では、generatorに入力するベクトル $z$ をサンプリングする分布の違いがGANsの性能にどのように影響するかを調べ、truncation trickと呼ぶ手法を提案している。これは、学習と推論でそれぞれ異なる分布から $z$ をサンプリングするというものである。具体的には、学習時には平均0、分散1の正規分布を使い、推論時には切断正規分布を使う。切断正規分布とは、確率変数の定義域に上限と下限が設定された正規分布である。下図は分布を切断する閾値の大小によってどのように生成画像が変化するかを示したものであるが、閾値を大きくすると(通常の正規分布に近付けると)生成画像の多様性は向上するがクオリティが下がり、閾値を下げるとその逆の傾向が見られることがわかる。

このようにtruncation trickにより生成画像のクオリティと多様性のトレードオフを調整することが可能となるが、どのようなgeneratorのモデルに対しても効果を発揮するわけではなく、学習と推論で分布を変えてしまうことで生成画像にアーチファクトが発生するなどの問題を引き起こす場合がある。本論文では、この問題の解決にはgeneratorにorthogonal regularization(を改変したもの)を導入することが効果的であると報告している。
性能評価
ImageNetにおけるinception scoreとFIDは以下の通り。

なお、列の違いはtruncation trickにおける閾値の違いである。
- 3列目:truncation trickなし
- 4列目:FIDがベスト(最小)となるときの閾値
- 5列目:検証データにおけるinception scoreとなるときの閾値
- 6列目:inception scoreがベスト(最大)となるときの閾値
これを見ると、128×128の場合、例えば5列目の結果ではSA-GANと比較してinception scoreは52.52から166.3、FIDは18.65から9.6と大幅に改善していることがわかる。
StyleGAN6
ProgressiveGANと同じNVIDIAのT.Kerrasらにより2018年12月にarXiv投稿された最新手法。ノイズベクトルを入力層から与えるという従来のgenerator構造を大きく変更し、まずノイズベクトルを別の空間にマッピングし、そこから得られた情報をgeneratorの各層に入力していくことで生成画像の大局的な構造から詳細構造までを柔軟に制御することを実現している。生成画像例については以下のYouTubeビデオを参照いただきたい。

Style-based generator
本論文で提案されたgeneratorは下図(b)の構造をしている。なお、ベースラインとなっているのは上述したProgressiveGANであり、そのgeneratorの構造は下図(a)である。従来のGANsにおけるgeneratorは基本的に(a)の構造であり、フィードフォワードネットワークの入力層にノイズベクトル $\boldsymbol{\rm z}$ が与えられる。一方で、(b)におけるstyle-based generatorでは入力層が存在せず、synthesis networkに入力されているのはただの定数である(ただし、定数の値は学習により決定)。
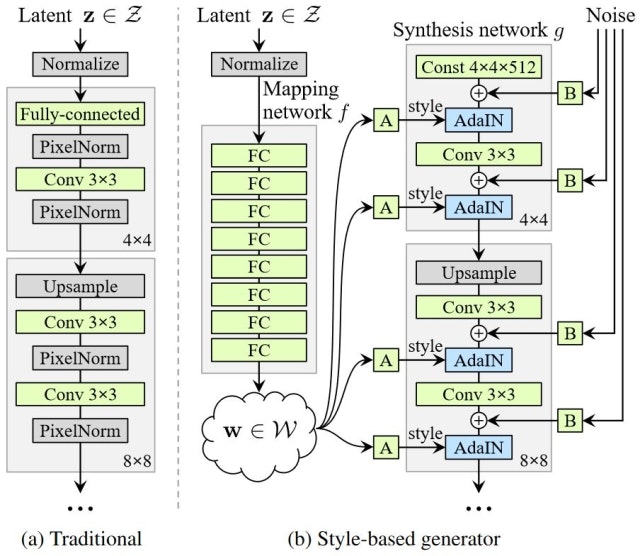
ではノイズベクトル $\boldsymbol{\rm z}$ はどうなるかというと、(b)の左に示されているように8層のMLPを通って $\boldsymbol{\rm w}$ に変換される。そして、図中に"A"で示されているアフィン変換によってパラメータ $\boldsymbol{\rm y}$ が生成される。ここで、$\boldsymbol{\rm y}$ は $\boldsymbol{\rm y}_s$ と $\boldsymbol{\rm y}_b$ から成り、次式で定義されるAdaptive instance normalization (AdaIN)を制御するパラメータである。AdaINは各畳み込み層の直後に適用される。
{\rm AdaIN}(\boldsymbol{\rm x}_i, \boldsymbol{\rm y}) = \boldsymbol{\rm y}_{s,i}\frac{\boldsymbol{\rm x}_i-\mu (\boldsymbol{\rm x}_i)}{\sigma (\boldsymbol{\rm x}_i)} + \boldsymbol{\rm y}_{b,i}
ここで $\boldsymbol{\rm x}_i$ は各特徴マップであり、それぞれ正規化されて $\boldsymbol{\rm y}$ によりスケールとバイアスが適用される。なお、スタイル変換等で使われている用語にならい、本論文では $\boldsymbol{\rm y}$ をstyleと呼んでいる。
また、生成画像に対して確率的な変動を与えるため、(b)の右に示されているように各層にノイズを与える。これはガウシアンノイズをスケーリングしたものであり、スケーリングファクタは各層で学習により決定される(図中の"B")。
Mixing regularization
本論文では、各層に入力されるstyleの影響をそれぞれの層に局在化させることを目的としてmixing regularizationという正則化手法を提案している。これは下図に示すように2つのノイズ $\boldsymbol{\rm z}_1$、$\boldsymbol{\rm z}_2$ から $\boldsymbol{\rm w}_1$、$\boldsymbol{\rm w}_2$ を生成しておき、ランダムに決めたポイントを境目としてsynthesis networkに入力する情報を $\boldsymbol{\rm w}_1$ から $\boldsymbol{\rm w}_2$ へ切り替えるというものである。
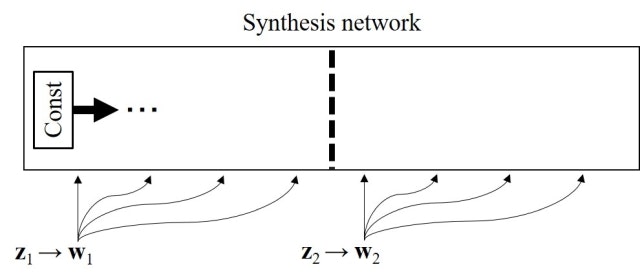
こうした正則化を入れることにより、synthesis networkは隣接した層間でstyleに相関があるという前提を置くことができなくなるため、styleの影響を各層に局在化させることが可能となる。
ノイズによる確率的な変動
例えば顔画像の生成における髪の毛の位置などといったランダムな要素は、本手法では乱数の挿入により確率的に変動させることができる。これは、最初の図に示したようにガウシアンノイズをスケーリングしたものをconv層の出力に対して画素単位で加算することで実現される。下図は、どの層にノイズを入力するかで生成画像にどのような違いが出るかを示したものである。(a)が全層にノイズを加えたもの、(b)がノイズなし、(c)と(d)はそれぞれ64×64~1024×1024 (fine)、4×4~32×32 (coarse)の層にだけノイズを加えたものである。ノイズを加えないとのっぺりとしたテクスチャのない領域が目立つのに対し、ノイズを加えることで細かなテクスチャが生まれている。また、ノイズを加えるレイヤの解像度によって生成されるテクスチャの細かさにも違いが出ている。

性能評価
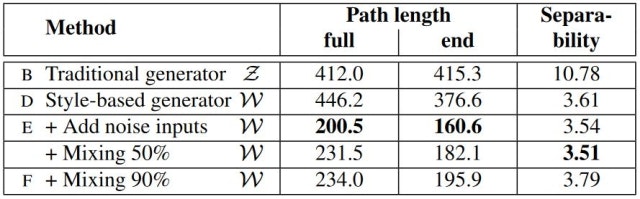
潜在空間のある部分空間からサンプリングしたベクトルだけを使って画像を生成したとき、生成される画像において変動する要素が一つしかない(e.g., 性別だけが変わる、肌の色だけが変わる)ような場合、その潜在空間はdisentangleされている(もつれが解かれている)と言う。このような空間が獲得できることが本手法の利点であり、それを確認するため本論文ではperceptual path lengthとlinear separabilityによる評価を提案している。
perceptual path lengthとは、潜在空間中を移動するパスを区分線形近似し、各区間の始点と終点で画像の見た目にどれだけ差があるかを調べてその全区間の和を求めたものである。これは、もし潜在空間がdisentangleされているならば、あるパスに沿って生成される画像の遷移はスムーズなものになるはずであるという直観を定量化したものである。画像間の見た目の差はVGG16から得られる特徴量間の距離(perceptually-based pairwise image distance7)により評価している。
また、linear separabilityとは、潜在空間中の各点が、その点から生成される画像のアトリビュートごとに線形分離できるかどうかを評価したものである。つまり、例えば男性の画像を生成するベクトルと、女性の画像を生成するベクトルとがどれだけ線形に分離可能かを定量化したものである。本論文では、まず顔画像のアトリビュートを特定する分類器を学習し、潜在空間のある点から生成した顔画像を分類することでその点に対してアトリビュートのラベルを付与している。そして、潜在空間中でこれらの点がラベルごとに線形分離できるかを線形SVMで実際に分離することで評価している。分離しやすさの定量化には条件付きエントロピー $H(Y|X)$ を用いている。ここで、$X$ はSVMにより予測されたラベルであり、$Y$ はあらかじめ画像分類器により付与されていたラベルである。$H(Y|X)$ が小さいほど分離が容易であると言える。
結果は以下の通りである。perceptual path length、linear separability共にベースライン(ProgressiveGAN)と比較して大幅に小さくなっている(改善している)ことがわかる。なお、データセットは本論文で新たに提案されたFFHQ (Flickr-Faces HQ)である。
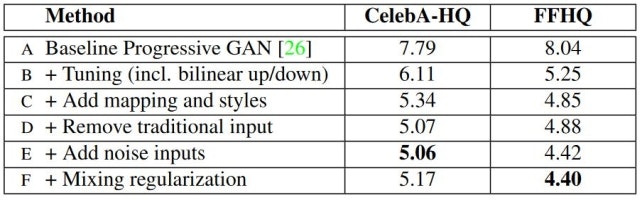
また、本論文で提案された様々な改善がどのように寄与しているかをFIDで評価した結果も報告されている。やはりProgressiveGANから大幅な改善が見られる。
まとめ
GANsによる画像生成系でここ数年で話題になったProgressive/Big/StyleGANsについてまとめた。ざっくり言うと、以下のような感じだろうか。
- ProgressiveGAN:段階的にネットワークを成長させることでメガピクセル画像の生成を実現
- BigGAN:ネットワークの大規模化によりImageNet級の超多クラス画像生成を実現
- StyleGAN:各層に入力信号を与えることでアトリビュート単位での生成画像の制御を実現
これらの最新手法では、確かに本物と見分けられないほどの超リアルな画像を生成することができるが、まだまだ課題は残っている。冒頭に紹介した読み会での発表にも取り上げられているように、特に複雑な幾何構造を持つような画像の生成はまだ不得意である。以下はBigGANの論文内で紹介されている例であるが、(a)は比較的生成が容易な例、(b)は困難な例である。例えば犬の画像の生成においてはテクスチャ生成が支配的で、またデータセット内でのバリエーションもそれほど大きくない。一方で、画像内の様々な位置に人の顔があるような画像や、群衆の画像などのようにダイナミックで構造的な画像の生成は苦手であり、今後の取り組みが期待される。

-
Tim Salimans et al., "Improved Techniques for Training GANs," NIPS2016. ↩
-
Martin Heusel et al., "GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium," NIPS2017. ↩
-
Tero Kerras et al., "Progressive Growing of GANs for Improved Quality, Stability, and Variation," ICLR2017. ↩
-
Andrew Brock et al., "Large Scale GAN Training for High Fidelity Natural Image Synthesis," arXiv, 2018. ↩
-
Han Zhang et al., "Self-Attention Generative Adversarial Networks," arXiv, 2018. ↩
-
Tero Karras et al., "A Style-Based Generator Architecture for Generative Adversarial Networks," arXiv, 2018. ↩
-
Richard Zhang et al., "The Unreasonable Effectiveness of Deep Features as a Perceptual Metric," CVPR2018. ↩