OpenAIからgpt-ossというオープンウェイトモデルがリリースされ、ローカル環境でもかなり品質の良いLLMが使えるようになりました。実際に触ってみると、日本語の応答品質が想像以上で、これは実用的に使えると感じました ✨
また、少し前にインストールを行っていたLM StudioもOpenAI互換APIサーバとして動作することがわかりました💡既存のコードがほぼそのまま使えるのは本当に便利です!
ということで、普段の開発スタイルWSL環境を活かしつつ、改めて環境を構築する方法にメモを残したいと思います。
1. 機密データもOK!gpt-oss-20bをローカルで!LM Studio+WSL+Python環境構築術
クラウドのAPIを使うのは簡単ですが、プライバシーの観点や、インターネット接続に依存しない環境での開発を考えると、ローカルLLMの活用は魅力的な選択肢ではないかと思います。
この記事では、Windows環境で動作するLM Studioと、WSL環境でのPython開発を組み合わせて、実際にローカルLLMを活用したプログラムを作成する方法を解説します。普段からWSL環境でPython開発を行っている方にとって、新たな開発の可能性が広がる内容になっています。
この記事の内容
- Windows環境のLM StudioとWSL環境のPythonプログラムを連携させる方法
- OpenAI互換APIを使用したローカルLLMへのアクセス方法
- 非ストリーム型とストリーム型の両方の実装パターン
- LLMの出力からThinking 部分を除去する処理
この記事の対象読者
以下のような方を想定しています。
- ローカルLLMに興味がある初学者プログラマ
- WSL環境でPython開発を行っている方
- プライバシーを重視したAI活用を検討している方
- OpenAIのAPIは使ったことがあるが、ローカル環境での実装は未経験の方
前提条件
以下の環境が整っていることを前提とします。
- Windows環境にLM Studioがインストール済み
- WSL環境にuvがインストール済み
- Pythonの基本的な知識
- ある程度コマンドラインでの基本的な操作に慣れていること
参照
実際にローカルLLM環境を構築していきます。
2. 使用技術の概要
設定に入る前に、今回使用する技術について簡潔に整理しておきます。それぞれの特徴と、なぜその技術を選択したかを理解することで、後の実装がスムーズに進められます。
LM Studioについて

特徴
- HuggingFaceから直接モデルをダウンロード可能
- GPU・CPUの両方に対応した最適化された実行環境
- OpenAI互換のREST APIサーバー機能
- リアルタイムでのパフォーマンス監視
今回の構成では、LM StudioがAPIサーバーとして動作し、WSL環境のPythonプログラムからHTTPリクエストでアクセスすることができます。これにより、ローカル環境でのLLM開発が非常に効率的になります。
OpenAI互換APIの利点
LM StudioがOpenAI互換のAPIを提供することで、既存のOpenAI用コードをほとんど変更なしで利用できます。これにより、学習コストを抑えつつローカル環境に移行できます。
WSL(Windows Subsystem for Linux)の利点
WSLを使用することで、Windows環境にいながらLinux環境でのPython開発が可能になります。特にAI・機械学習分野では、Linuxベースのツールやライブラリが多く、WSLの利用は実用的な選択肢です。
長所
- Linux環境での豊富なPythonパッケージ
- 今どきのツールチェーンの活用
- 本番環境(多くの場合Linux)との環境差の軽減
- Windows環境のLM Studioとの連携による柔軟性
uvによるPythonプロジェクト管理
uvは、高速なPythonパッケージマネージャーです。従来のツールと比較しても依存関係の解決とインストールが大幅に高速化されています。
従来ツール(venv、pip、pyenvなど)との比較
- venv … Python標準の仮想環境ツールだがactivateで環境切り替えが必須
- pip … 標準的だが動作が重い
- pyenv … Pythonのバージョン管理のみに特化
uvを使用することで、プロジェクトの初期化から依存関係の管理を全般を行える良さがあります。
openai/gpt-oss-20bモデルについて
今回使用するモデルは、2025年8月5日にOpenAIがリリースした最新のオープンウェイトLLMです。21億パラメータ(20.9B total parameters)を持ち、実際の実行時には3.6BパラメータがアクティブになるMixture-of-Experts(MoE) アーキテクチャを採用しています。
リリース情報
- 発表日 … 2025年8月5日
- 公式発表 … OpenAI公式ブログ
- HuggingFaceページ … openai/gpt-oss-20b
- ライセンス … Apache 2.0(商用利用可能)
技術仕様と性能
- パラメータ数 … 21億パラメータ(アクティブ時3.6億)
- メモリ要件 … 16GB程度で実行可能
- コンテキスト長 … 128k tokens
- 性能 … OpenAI o3-miniと同等レベルの推論能力
モデル選択の理由
- 適度なサイズで現実的なPC環境でも動作しやすい
- 最新のオープンウエイト(ソースがないのでこう呼ぶ)モデル
- 多言語対応
次は、実際にLM StudioでAPIサーバーを設定していきます。
3. LM StudioでのAPIサーバー設定🪟
LM Studioを使用してopenai/gpt-oss-20bモデルを動作させ、WSL環境からアクセスできるAPIサーバーとして設定します。これにより、PythonプログラムからHTTPリクエストでローカルLLMにアクセスが可能です。
3.1 LM Studioの起動とモデルのダウンロード
【ステップ1】LM Studioの起動
WindowsのスタートメニューまたはデスクトップのアイコンからLM Studioを起動します。また、今回使用するモデルopenai/gpt-oss-20bのダウンロードも事前に行ってください。
参考
3.2 ローカルサーバーの設定
【ステップ2】サーバー設定画面への移動
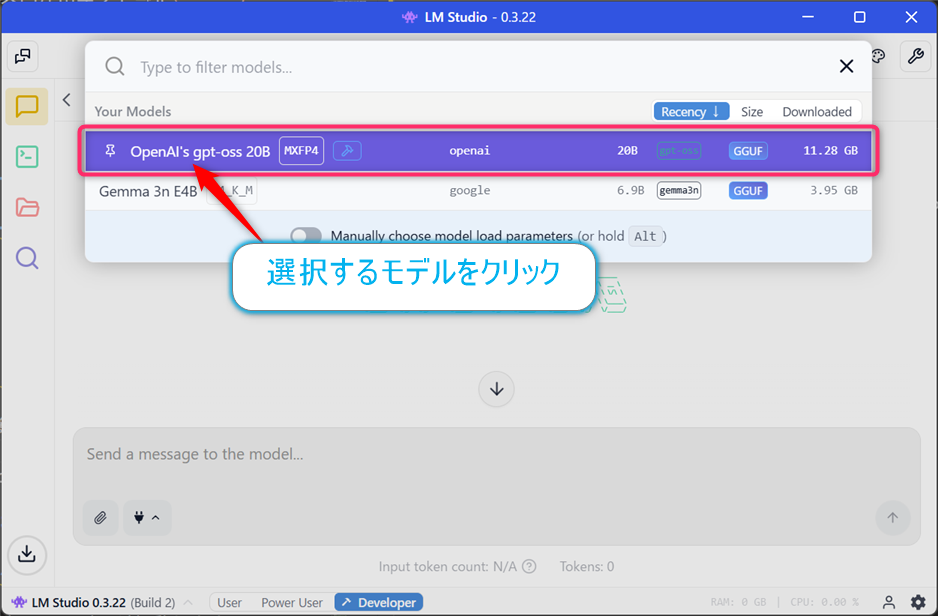
画面上部にある【Select a model to load】のドロップダウンからopenai/gpt-oss-20bを選択する。この作業でLLMモデルの読み込みが始まります。
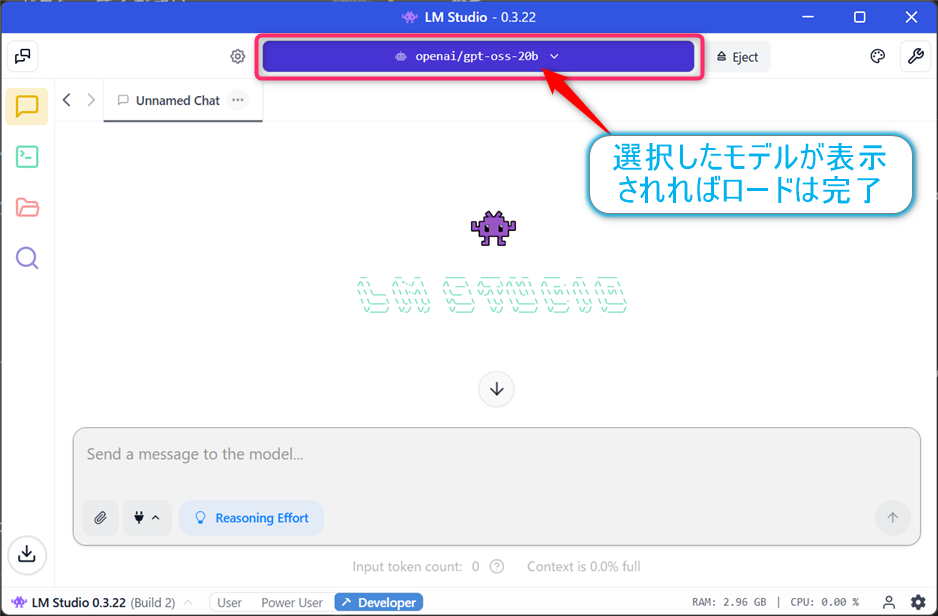
【ステップ3】APIサーバーの起動
モデル読み込み完了後
【Developer】モードになっているか確認を行う。
左にある【Developer】アイコンをクリックして
【Setting】ボタンをクリックし、設定を行う。
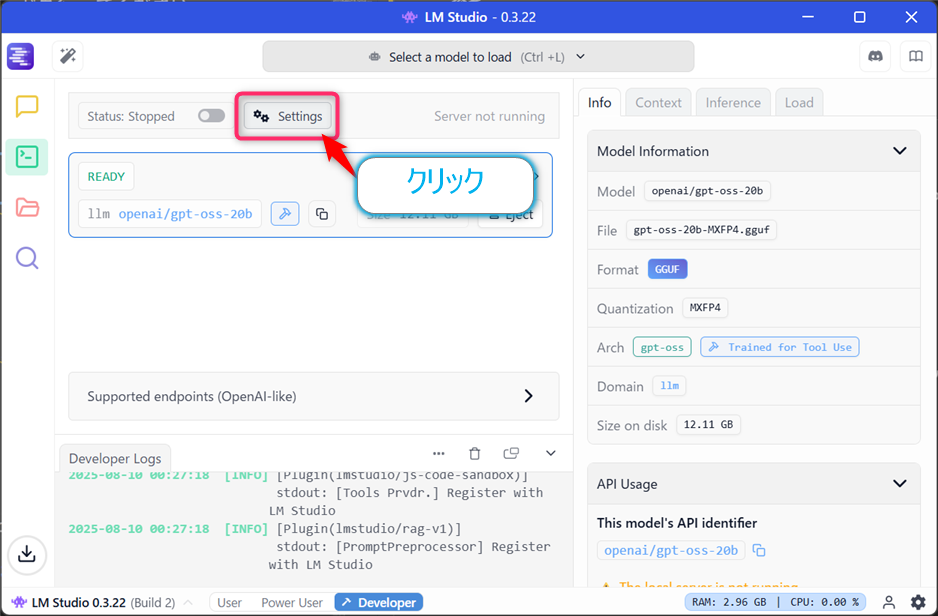
設定値は以下の通り
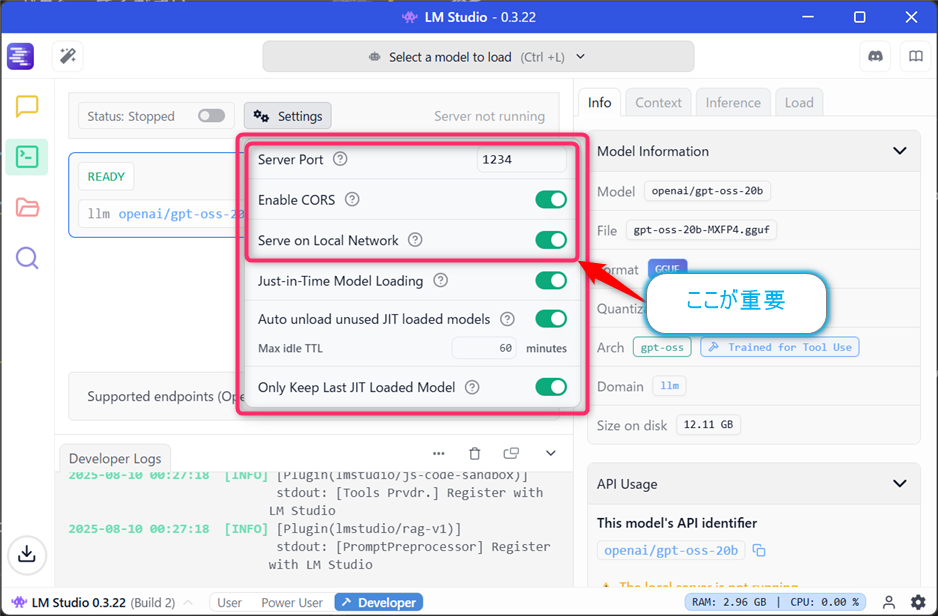
設定後、【Server Running】のトグルボタンをONにする。画面上部にReachable at:と表示され、WSLからアクセス可能なURLが表示されます。
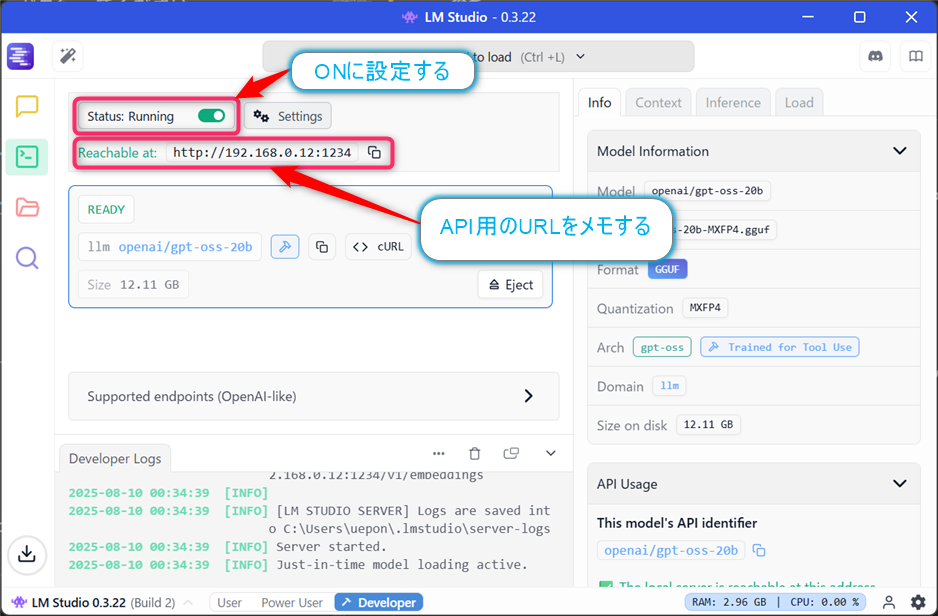
これでLM StudioのAPIサーバーが起動します、表示されたURLはメモしておいてください。
3.3 サーバー設定の確認と調整
基本的なサーバー設定
APIサーバーのデフォルト設定は以下の設定となっていますが、今回はWSL環境からのアクセスなので、これは使用できません(ループバックの設定を行えば使用可能)。
- ポート番号 … 1234
- ホスト … localhost (127.0.0.1)
WSLからのアクセスを可能にする設定
さきほど既に行っていますが、WSL環境からアクセスするために、以下の設定を行います。
- 【Settings】ボタンをクリック
- 【Serve on Local Network】をONにする(これが重要です)
- 【Enable CORS】は任意(ON/OFFどちらでも動作します)
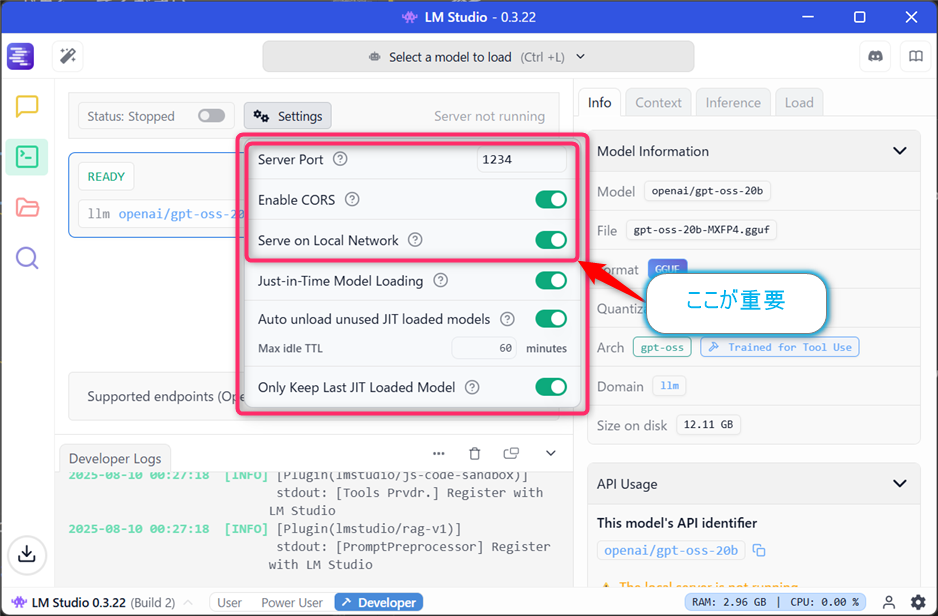
重要
【Serve on Local Network】をONにすることで、WSL環境からWindows側で動作するLM StudioのAPIサーバーにアクセスできるようになります。この設定を忘れると、後の接続テストで失敗する原因となります。
3.4 APIエンドポイントの確認
【ステップ5】エンドポイント情報の確認
サーバー画面のReachable at:に表示されるIPアドレスを確認し、以下の形式でエンドポイントを構成します。
-
Base URL …
http://表示されたIPアドレス:1234/v1 -
Models endpoint …
http://表示されたIPアドレス:1234/v1/models -
Chat completions …
http://表示されたIPアドレス:1234/v1/chat/completions
例:IPアドレスが192.168.1.100の場合
-
Base URL …
http://192.168.1.100:1234/v1
これらのエンドポイントは、後のPython実装で使用します。
注意すべきネットワーク設定
-
ファイアウォール設定
- Windowsファイアウォールがポート1234への接続を許可するか確認してください。
- 初回起動時にWindowsから許可を求められる場合があります。
-
ネットワークアクセス
- 【Serve on Local Network】をONにすると、同じネットワーク上の他のデバイスからもアクセス可能になります。
- 社内ネットワークや公共Wi-Fiでは注意が必要です。
-
データの取り扱い
- ローカルLLMはデータが外部に送信されないメリットがありますが、LM Studioのログ機能で会話履歴が保存される場合があります。
- 機密情報を扱う際は、ログ設定を確認してください。
今回は学習目的なので基本設定で進めることにします。
3.5 動作確認
【ステップ6】LM Studio内でのテスト
APIサーバー設定の最終確認として、LM StudioでChatでやり取りができるかも確認しておきましょう。
トラブルシューティング
- モデル読み込みでエラーが発生する場合、メモリ不足の可能性があります。他のアプリケーションを終了してから再試行してください
- サーバー起動時にポートエラーが発生する場合、他のアプリケーションが同じポート(1234)を使用している可能性があります。LM Studioの設定でポート番号を変更するか、競合するアプリケーションを終了してください
これでLM StudioでのAPIサーバー設定は完了です。次の章では、WSL環境からこのAPIサーバーに接続する方法を確認していきます。
4. WSL環境からの接続テスト🐧
LM StudioのAPIサーバー設定が完了したら、WSL環境から実際に接続できるかをテストします。curlコマンドを使用してAPIのテストとしてモデル一覧を取得します。
4.1 WSL環境(ディストリビューション)の起動
WSLの起動
Windows Terminalなどから、使用しているWSLディストリビューション(Ubuntu、Debian等)を起動します。
4.2 curlコマンドでのAPI接続テスト
基本的な接続テスト
curlコマンドを使用して、LM StudioのAPIエンドポイントに接続してみます。
# 基本的な接続テスト(IPアドレスは実際の表示に合わせて変更してください)
$ curl -X GET http://192.168.1.100:1234/v1/models
成功すると、JSON形式でレスポンスが返ってきます。
期待される出力例
{
"object": "list",
"data": [
{
"id": "openai/gpt-oss-20b",
"object": "model",
"created": 1725840000,
"owned_by": "openai"
}
]
}
この出力でopenai/gpt-oss-20bが表示されれば、モデルが正常に読み込まれています。
4.3 簡単なチャット接続テスト
実際のチャット機能をテスト
OpenAI互換APIを使用して、簡単なメッセージを送信してみます。
# IPアドレスは実際の表示に合わせて変更してください
$ curl -X POST http://192.168.1.100:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-20b",
"messages": [
{
"role": "user",
"content": "こんにちは"
}
],
"max_tokens": 100
}'
成功すると、AIからの応答がJSON形式で返ってきます。
この接続テストが成功したら、次はPython開発環境の準備に進みます。
5. Python開発環境の準備🐧
WSL環境からの接続確認が完了したら、uvを使用してPythonプロジェクトを作成し、必要なパッケージをインストールしていきます。また、環境設定を管理するための.envファイルも作成します。
5.1 uvでのプロジェクト作成
新しいプロジェクトの作成
まず、プロジェクト用のディレクトリを作成し、uvでPythonプロジェクトを初期化します。
# プロジェクト用ディレクトリの作成
$ mkdir lmstudio-python-client
$ cd lmstudio-python-client
# uvでプロジェクトを初期化
$ uv init
uvがプロジェクトの基本構造を作成し、pyproject.tomlファイルが生成されます。
プロジェクト構造の確認
# 作成されたファイルを確認
$ ls -la
以下のような構造になっているはずです。
├── README.md
├── main.py
└── pyproject.toml
5.2 必要なパッケージのインストール
OpenAI互換クライアントの追加
LM StudioのAPIにアクセスするため、openaiライブラリを追加します。
# openaiライブラリの追加
$ uv add openai
環境変数管理ライブラリの追加
.envファイルから環境変数を読み込むため、python-dotenvライブラリを追加します。
# python-dotenvライブラリの追加
$ uv add python-dotenv
依存関係の確認
# インストールされたパッケージの確認
$ uv pip list
Package Version
----------------- --------
annotated-types 0.7.0
anyio 4.10.0
certifi 2025.8.3
distro 1.9.0
h11 0.16.0
httpcore 1.0.9
httpx 0.28.1
idna 3.10
jiter 0.10.0
openai 1.99.5
pydantic 2.11.7
pydantic-core 2.33.2
python-dotenv 1.1.1
sniffio 1.3.1
tqdm 4.67.1
typing-extensions 4.14.1
typing-inspection 0.4.1
pyproject.tomlの確認
# 設定ファイルの内容確認
cat pyproject.toml
以下のような内容になっているはずです:
[project]
name = "lmstudio-python-client"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.12"
dependencies = [
"openai>=1.99.5",
"python-dotenv>=1.1.1",
]
5.3 .envファイルの作成
環境設定ファイルの作成
プロジェクトルートに.envファイルを作成し、LM StudioのAPI設定を記述します。
環境変数の設定
.envファイルに以下の内容を記述します(IPアドレスは実際の表示に合わせて変更)。
# .envファイルの編集
$ nano .env
# LM Studio API設定
OPENAI_API_BASE=http://192.168.1.100:1234/v1
OPENAI_API_KEY=dummy-key
MODEL_NAME=openai/gpt-oss-20b
# その他の設定
MAX_TOKENS=1000
TEMPERATURE=0.7
重要な設定項目の説明
- OPENAI_API_BASE … LM StudioのAPIエンドポイント
- OPENAI_API_KEY … ローカル環境では不要だが、openaiライブラリが要求するためダミー値を設定
- MODEL_NAME … 使用するモデル名
- MAX_TOKENS … 生成する最大トークン数
- TEMPERATURE … 生成の創造性を調整(0.0〜1.0)
これでPython開発環境の準備は完了です。次の章では、実際にPythonでLM StudioのAPIにアクセスするコードを実装していきます。
6. Pythonでの実装🐧
開発環境の準備ができたら、実際にPythonコードでLM StudioのAPIにアクセスしてみましょう。非ストリーム型とストリーム型の両方の実装パターンを学習します。
6.1 基本的なクライアント設定
完全なソースコードは最後にまとめて掲載します。
クライアントファイルの作成
まず、基本的なLLMクライアントのコードを作成します。
設定読み込みの処理抜粋
import os
from openai import OpenAI
from dotenv import load_dotenv
# 環境変数の読み込み
load_dotenv()
# OpenAIクライアントの初期化
client = OpenAI(
base_url=os.getenv("OPENAI_API_BASE"),
api_key=os.getenv("OPENAI_API_KEY")
)
# 設定値の取得
MODEL_NAME = os.getenv("MODEL_NAME")
MAX_TOKENS = int(os.getenv("MAX_TOKENS", 1000))
TEMPERATURE = float(os.getenv("TEMPERATURE", 0.7))
print("LM Studio Python Client初期化完了")
print(f"モデル: {MODEL_NAME}")
print(f"API Base: {os.getenv('OPENAI_API_BASE')}")
6.2 非ストリーム型での通信実装
基本的なチャット機能抜粋
一度にすべてのレスポンスを受け取る従来型の実装です。
def chat_completion_basic(user_message):
"""非ストリーム型でのチャット通信"""
try:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "user", "content": user_message}
],
max_tokens=MAX_TOKENS,
temperature=TEMPERATURE
)
return response.choices[0].message.content
except Exception as e:
print(f"エラーが発生しました: {e}")
return None
if __name__ == "__main__":
print("\n=== 非ストリーム型テスト ===")
user_input = "Pythonの特徴を3つ教えてください"
print(f"質問: {user_input}")
print("回答を生成中...")
result = chat_completion_basic(user_input)
if result:
print(f"回答: {result}")
else:
print("回答の生成に失敗しました")
実行とテスト
# 非ストリーム型のテスト実行
$ uv run python main.py
LM Studio Python Client初期化完了
モデル: openai/gpt-oss-20b
API Base: http://133.68.80.212:1234/v1
=== 非ストリーム型テスト ===
質問: Pythonの特徴を3つ教えてください
回答を生成中...
回答: Need to answer in Japanese. Provide three features.**Python の主な特徴(代表的な3点)**
| # | 特徴 | 具体例・メリット |
|---|------|------------------|
| **1. 読みやすく書きやすい構文** | インデントでブロックを表し、余計な記号が少ない。<br>```python<br>def greet(name):<br> print(f"Hello, {name}!")``` | コードレビューや保守が楽になり、初心者でも学びやすい。 |
| **2. 豊富で統一された標準ライブラリ** | `datetime`・`json`・`re` など、多くの機能が「何もしない」状態から利用可能。<br>```python<br>import json, os, re``` | 外部パッケージを導入せずに多様なタスク(ファイル操作、正規表現、データ構造変換)が実装できる。 |
| **3. 高レベル言語でありながら高速化が可能** | C/C++ で書かれた拡張モジュールや `numpy`・`pandas` などの数値計算ライブラリを利用できる。<br>```python<br>import numpy as np<br>a = np.arange(1000)**2``` | 高速処理が必要な場面でも、Python の簡潔さを保ったままパフォーマンスを引き上げられる。 |
これらの特徴により、**スクリプト言語としてだけでなく、データサイエンス・Web 開発・自動化ツールなど幅広い分野で採用されています。**
6.3 ストリーム型での通信実装
完全なソースコードは最後にまとめて掲載します。
リアルタイムレスポンス機能(ストリーム型)抜粋
生成されたテキストをリアルタイムで受信し表示する実装です。
def chat_completion_stream(user_message):
"""ストリーム型でのチャット通信"""
try:
stream = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "user", "content": user_message}
],
max_tokens=MAX_TOKENS,
temperature=TEMPERATURE,
stream=True # ストリーミングを有効化
)
print("回答: ", end="", flush=True)
full_response = ""
for chunk in stream:
if chunk.choices[0].delta.content is not None:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_response += content
print() # 改行
return full_response
except Exception as e:
print(f"エラーが発生しました: {e}")
return None
if __name__ == "__main__":
print("\n=== ストリーム型テスト ===")
user_input = "WSLとDockerの違いを説明してください"
print(f"質問: {user_input}")
result = chat_completion_stream(user_input)
if result:
print(f"\n\n完全な回答を受信しました({len(result)}文字)")
else:
print("回答の生成に失敗しました")
実行とテスト
$ uv run main_stream.py
LM Studio Python Client初期化完了
モデル: openai/gpt-oss-20b
API Base: http://133.68.80.212:1234/v1
=== ストリーム型テスト ===
質問: WSLとDockerの違いを説明してください
回答: Need explain differences between Windows Subsystem for Linux and Docker, likely in Japanese. Provide overview of what each is, how they differ: WSL is a compatibility layer to run Linux binaries on Windows; Docker uses containerization, can run on top of WSL or Windows. Explain architecture, use cases, performance, isolation, etc.## WSL(Windows Subsystem for Linux)と Docker の違い
| 項目 | WSL (Windows Subsystem for Linux) | Docker |
|------|------------------------------------|--------|
| **目的** | Windows 上で Linux バイナリをそのまま実行できるようにする「互換レイヤー」 | アプリケーションを軽量なコンテナとしてパッケージ化し、環境差異をなくして移植性・スケーラビリティを高めるための **コンテナランタイム** |
| **動作原理** | Windows カーネルが Linux システムコールをエミュレート(WSL 1)<br>または軽量な Linux カーネルを実行(WSL 2) | Linux コンテナのファイルシステム・ネットワーク・プロセス空間を名前空間と cgroups で分離し、ホストカーネル上で直接動かす |
| **OS レイヤー** | Windows がホスト OS。Linux は「仮想的な」レイヤーとして実行される | Linux コンテナは **同じカーネルを共有**(Docker Desktop なら Windows 上に軽量 Linux カーネルを動かす) |
| **用途** | - 開発者が Windows 環境で Linux ツール・スクリプトをそのまま使いたい<br>- Bash、Python、Go 等の開発<br>- シェルスクリプトやパッケージマネージャ(apt, yum)を利用したい | - アプリケーションを環境依存性なくデプロイしたい<br>- CI/CD パイプラインでビルド・テスト・デプロイを統一したい<br>- マイクロサービスの分離やスケールアウト |
| **パフォーマンス** | WSL 2 ではほぼネイティブに近いファイル I/O、ネットワーク速度。WSL 1 は少し遅いが軽量。 | コンテナはオーバーヘッドが低く、VM より高速。カーネル共有のためリソース効率が高い |
| **隔離レベル** | 同一 Windows ユーザー空間内で Linux 環境を走らせる。プロセスは同じハードウェア(CPU/メモリ)を共有し、完全に分離されているわけではない。 | ネームスペース・cgroups によって **プロセス単位で隔離**。コンテナ間の干渉はほぼゼロ |
| **管理ツール** | `wsl` コマンド(インストール、起動、バージョン切替など) | Docker CLI (`docker run`, `docker build`) と Compose, Swarm, Kubernetes など |
| **互換性** | Linux ディストリビューションを選択してインストールできる。Windows アプリと同時に実行可能。 | コンテナは「イメージ」によって完全に再現可能。イメージは Docker Hub 等で共有できる |
| **典型的な構成** | `wsl --install -d Ubuntu` → そのまま Bash から開発・デバッグ | `docker run nginx`, `docker-compose up` など |
---
### まとめ
- **WSL は「Linux を Windows 上で動かすための環境」**
- 開発者が Linux ツールを使う際に便利。
- カーネルレベルは Windows が担当(WSL 2 では軽量な Linux カーネルを起動)。
- **Docker は「アプリケーションをコンテナ化して環境差異をなくすツール」**
- コンテナは同じカーネル上で分離され、移植性・スケーラビリティが高い。
- WSL 2 をバックエンドに使う Docker Desktop は「WSL 上
完全な回答を受信しました(2008文字)
6.4 対話的なチャットシステム
完全なソースコードは最後にまとめて掲載します。
簡単なチャットループ抜粋
ユーザーとの対話を続けるシンプルなチャットシステムを実装します。
def interactive_chat():
"""対話的なチャットシステム"""
print("\n=== 対話チャット開始 ===")
print("'quit'と入力すると終了します")
print("'stream'と入力するとストリーム型に切り替わります")
print("'normal'と入力すると非ストリーム型に切り替わります")
use_stream = False
while True:
user_input = input("\nあなた: ").strip()
if user_input.lower() == 'quit':
print("チャットを終了します")
break
elif user_input.lower() == 'stream':
use_stream = True
print("ストリーム型に切り替えました")
continue
elif user_input.lower() == 'normal':
use_stream = False
print("非ストリーム型に切り替えました")
continue
elif not user_input:
continue
print("\nAI: ", end="" if use_stream else "")
if use_stream:
chat_completion_stream(user_input)
else:
result = chat_completion_basic(user_input)
if result:
print(result)
else:
print("回答の生成に失敗しました")
# メイン実行部分の更新
if __name__ == "__main__":
# 基本テスト
print("\n=== 非ストリーム型テスト ===")
result = chat_completion_basic("こんにちは")
if result:
print(f"回答: {result}")
# ストリームテスト
test_stream()
# 対話チャット
try:
interactive_chat()
except KeyboardInterrupt:
print("\n\nチャットを終了します")
実行とテスト
$ uv run python main.py
LM Studio Python Client初期化完了
モデル: openai/gpt-oss-20b
API Base: http://133.68.80.212:1234/v1
=== 非ストリーム型テスト ===
回答: Need to respond in Japanese greeting.こんにちは!今日はどんなご用件でしょうか?お気軽にお聞きください。
=== 対話チャット開始 ===
'quit'と入力すると終了します
'stream'と入力するとストリーム型に切り替わります
'normal'と入力すると非ストリーム型に切り替わります
あなた: こんにちは
AI: Need to respond in Japanese greeting.こんにちは!今日はどんなご質問やお話をしましょうか?
あなた: quit
チャットを終了します
6.5 完全なソースコード
lmstudio_api_sample.py
LMStudioを使用したAPIサーバのサンプルコード(Windows-WSL-Python)
これで、非ストリーム型とストリーム型の両方の実装が完了しました。ただ、この出力結果ではLLMのThinking の部分が含まれています。そこで、LLMの出力からThinking 部分を除去する処理を考えます。
7. レスポンス整形とThinking部分の除去🐧
openai/gpt-oss-20bモデルの出力には、思考過程を示すThinking部分が含まれています(Thinkingしないモデルにはないので不要な場合にはよみ飛ばしてください)。
7.1 Thinking部分の特徴
典型的なThinking部分の例
先ほどのプログラムの例では、以下のようにThinking部分が表示されています。
Need to respond in Japanese greeting.こんにちは!今日はどんなご用件でしょうか?
Need to respond in Japanese greeting.がThinking部分となります。その後が生成結果となります。
Thinking部分の一般的な特徴
- 言語 主に英語(別言語)で記述されることが多い
- 内容 AIの内部的な判断や指示
- 文体 「Need to」「Should」「Must」などの助動詞で始まることが多い
- 区切り ピリオドで終わり、その後に実際の回答が続く
注意点
Thinking部分の形式や有無は、使用するモデルや設定によって大きく異なる可能性があります。openai/gpt-oss-20bで見られるパターンが、他のモデルでも同様に現れるとは限りません。
今回は例としてopenai/gpt-oss-20bモデルのThinking部分を除去する方法を考えます。
7.2 Thinking部分を除去する関数
基本的な除去処理の実装
Thinking 部分の特徴を基に、正規表現を使用した除去処理を考えてみます。
import re
def clean_thinking_response(text):
"""
レスポンスからThinking部分を除去する
Args:
text (str): 生のレスポンステキスト
Returns:
str: クリーンアップされたテキスト
"""
if not text:
return text
# openai/gpt-oss-20bで観察される基本的なパターン
# 英語で始まりピリオドで終わる部分を除去
cleaned = re.sub(r'^[A-Z][^。]*?\.\s*', '', text)
# 複数の空白を一つにまとめ、前後の空白を除去
cleaned = re.sub(r'\s+', ' ', cleaned).strip()
return cleaned
使用例
# 使用例
raw_output = "Need to respond in Japanese greeting.こんにちは!今日はどんなご用件でしょうか?"
clean_output = clean_thinking_response(raw_output)
print(f"生の出力: {raw_output}")
print(f"クリーン後: {clean_output}")
8. まとめ
今回は、Windows環境のLM StudioとWSL環境のPython開発を組み合わせて、ローカルLLMのAPIサーバとして使用してみました。
LM StudioでのAPI開発の利点
- プライバシー保護 … データが外部に送信されないローカル環境での AI 活用
- コスト効率 … クラウドAPIの利用料金を気にせずに開発とテストが可能
- 柔軟性 … WSL環境によるLinuxツールの活用とWindows環境の共存
- 移植性 … OpenAI互換APIによるクラウドとローカルの切り替えの容易さ
参考リンク
公式ドキュメント
おわりに
今回はLM Studioを使用してローカルLLM環境を構築してみみましたが、想像していたよりもずっと簡単に実用的な環境が作れることに驚きました。自分にとってはLM StudioとWSLの組み合わせは、既存の開発スタイルを大きく変えることなく導入できるのが本当に良かったです😊
また、思っていた以上にgpt-ossモデルの品質もよく、クラウドAPIに頼っていた作業の一部は確実にローカル環境で代替できそうです。プライバシーを保ちながらAIの恩恵を受けられるのは、特に研究や業務での活用において大きな価値があると思います。